
Publié le 11 juillet 2025, par Nicolas CHOLLET
Dans cet article, nous mettons en avant un cas client très classique : un client BotB qui pilote des campagnes Ads à la performance (génération de leads), mais qui perd la vision de ce que devient le lead une fois intégré dans le CRM. Devient-il un client ? Quand ? Quelle typologie de client, etc..
En combinant la donnée Ads, Web et CRM (Hubspot ici), nous pouvons donner une vision de la performance de bout en bout, et donner une vision du ROI globale des campagnes beaucoup plus précise
Comment reprendre le contrôle de sa donnée marketing en 6 semaines ?
Des exports manuels à une vision ROI en temps réel – récit d’une transformation par étapes.
Avant : des données éparpillées, un calcul de ROI des campagnes approximatifs
Quand nous avons rencontré l’équipe en charge de l’acquisition, leur marketing digital fonctionnait… mais à quel prix. Chaque mois, l’équipe en charge des opérations marketing, passait près de deux jours à compiler des données issues de HubSpot, Google Ads, LinkedIn, Meta, Bing et GA4. Tout se faisait à la main, dans Excel, avec un niveau de fiabilité et de scalabilité limité.
« On savait qu’on passait à côté d’opportunités. Il nous manquait une vision consolidée du parcours client, et surtout une manière fiable d’en mesurer le ROI. »
Le constat était clair : trop de temps perdu à agréger, pas assez à analyser. Et surtout, impossible d’expliquer simplement à un CODIR le vrai retour sur investissement des campagnes.
🎯 L’objectif : relier chaque euro investi en “Paid” à une opportunité signée dans Hubspot
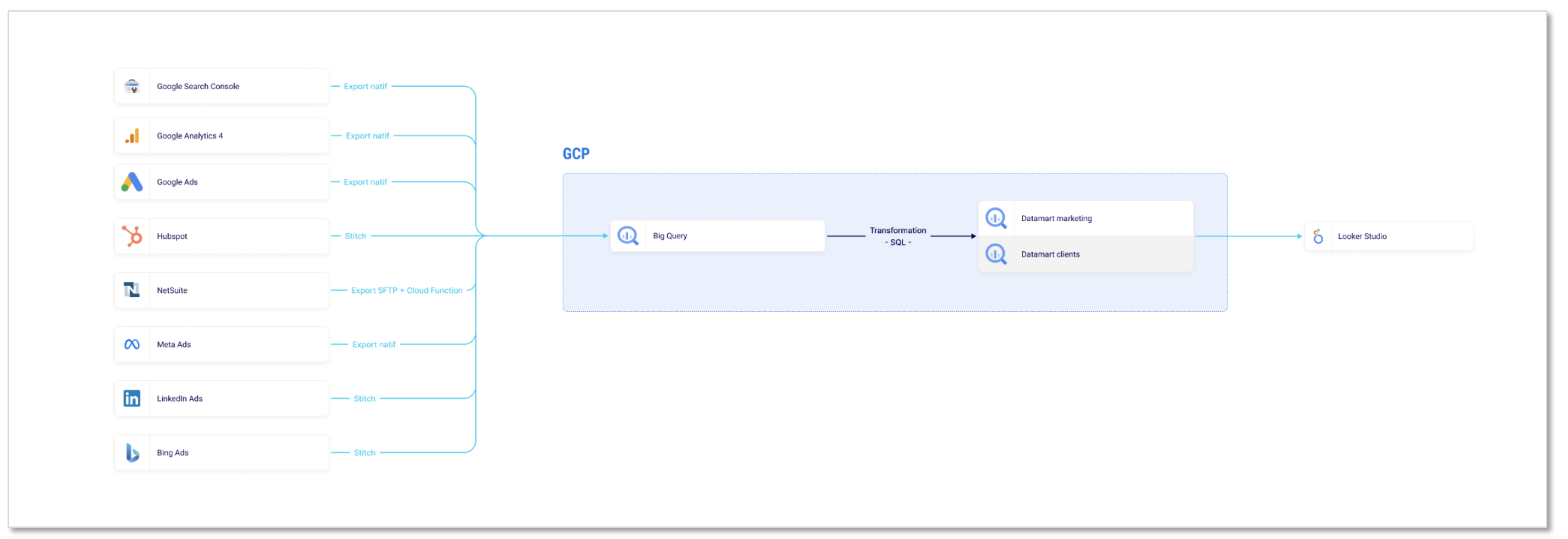
Le besoin formulé était précis : suivre le coût d’acquisition jusqu’à la vente, avec un pilotage régulier, visuel, autonome. Pas de plateforme miracle, mais une architecture sobre et robuste :
- Stitch pour connecter les plateformes Ads et HubSpot à un data warehouse,
- BigQuery dans Google Cloud Platform comme socle de plate-forme data
- Looker Studio pour restituer les KPI business en temps réel.
Ce que nous avons mis en place
🔌 1. Centraliser les données avec Stitch
Nous avons choisi d’utiliser l’ETL “Stitch”. Bien que n’étant pas particulièrement à la mode, il est robuste, peu couteux (100 euros / mois), et parfait pour les cas d’usages du marketing digital.
L’équipe a activé six connecteurs Stitch : Google Ads, Bing Ads, Meta Ads, LinkedIn Ads, GA4, HubSpot. Ce choix plutôt qu’un transfert natif (de la donnée brute GA4, GAds) a été stratégique : les chiffres récupérés via Stitch étaient strictement identiques à ceux vus en interface, à la virgule près.
« C’est ce qui a convaincu la direction : quand les chiffres sont ISO entre tous les outils, il n’y a plus de débat. »
🧱 2. Structurer la donnée dans BigQuery
Toutes les données sont arrivées dans une zone dite raw. À partir de là, des requêtes programmées chaque nuit ont permis de créer des datamarts lisibles par tous : un pour chaque source, un pour les campagnes paid globales, et un dernier – le plus important – croisant campagnes et pipeline HubSpot.
Le deal, les UTM, la valeur signée : tout est relié, avec une granularité à la campagne et au deal.
« On a gardé la structure la plus simple possible. Pas d’orchestrateur, pas d’outil exotique. Juste des scheduled queries SQL, bien commentées. Pour des cas plus structurés, nous aurions utilisé Dataform ou dbt »— Xavier
📊 3. Visualiser la performance dans Looker Studio
Deux dashboards principaux ont été construits :
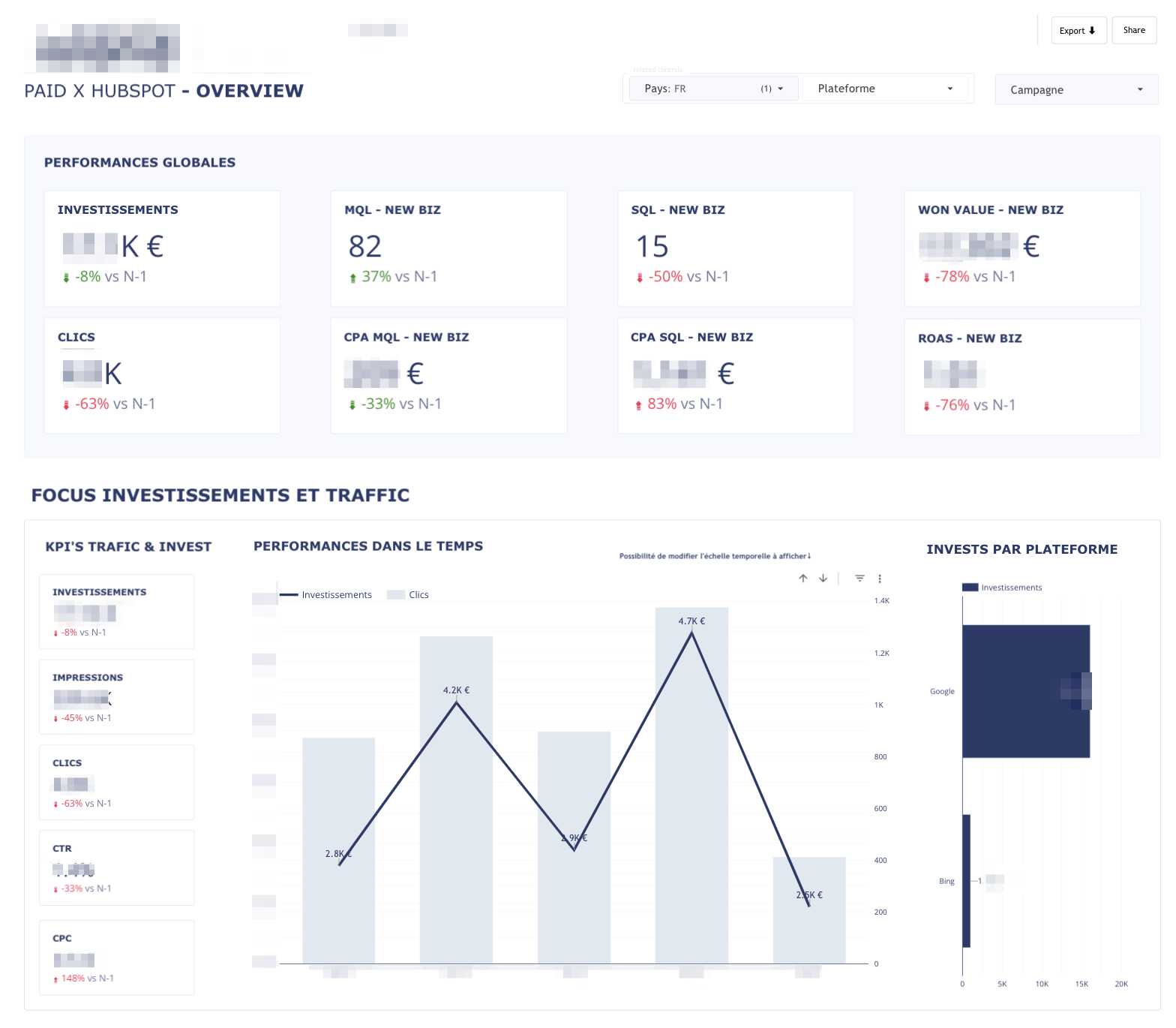
- Paid × HubSpot Overview : un cockpit avec les investissements, MQL, SQL, ROAS et valeur signée.
- Focus Investissements & Trafic : une lecture plus macro des dépenses et des canaux, pour ajuster les budgets à la volée.
Chaque tableau de bord est mis à jour automatiquement, consultable à tout moment par l’équipe.
« Pour la première fois, on pouvait répondre en une minute à la question : “Quelles campagnes ont généré des leads de qualité ce mois-ci ? Et combien ont-ils rapportés de CA” »
🔄 Reprise en main & autonomie
Au-delà des chiffres, c’est une nouvelle culture de la donnée qui a émergé. L’équipe marketing pose désormais des questions précises, fait des hypothèses, teste, puis mesure. Et surtout, elle ne dépend plus d’un data engineer pour explorer ses données.
Ce projet n’a pas été pensé comme une dépendance à un prestataire, mais comme une transmission.
- Chaque connecteur Stitch a été ré‑authentifié avec les credentials de l’équipe.
- Les requêtes SQL ont été documentées ligne par ligne.
- Une bibliothèque Notion a été remise, avec guides visuels : créer une intégration, modifier une requête, importer un fichier dans BigQuery, etc.
« Je n’avais jamais utilisé BigQuery ni écrit de SQL avant. Aujourd’hui, je suis capable de dupliquer une requête, d’ajouter un filtre, et de comprendre comment tout s’articule. »
🚀 La suite : attribution avancée & signaux offline
Le socle est en place. Plusieurs pistes d’évolution ont été identifiées pour maximiser la valeur des données :
- Mettre en place une attribution multi-touch, en intégrant les parcours GA4 plus finement.
- Envoyer les conversions offline (ex : passage à SQL ou deal signé) vers Meta Ads et Google Ads, pour améliorer les algorithmes d’enchères.
- Prédire la Lifetime Value d’un lead dès sa qualification, pour ajuster dynamiquement les budgets.
- Orchestrer les modèles via dbt Cloud, si les besoins ou l’équipe data grandissent.
✨ En résumé
En 6 semaines, notre client est passé :
De… | À… |
Des exports Excel hebdo | Un pilotage temps-réel |
Des KPI last-touch sans valeur client | Un ROAS à la vente, certifié HubSpot |
Une culture outil centrée Excel | Une équipe marketing autonome sur Looker & BigQuery |
Un temps de reporting > 1 journée | Un cockpit opérationnel, à jour chaque matin |
Vous vivez les mêmes douleurs ?
Vous jonglez avec les exports, les dashboards approximatifs, les KPI non fiables ?
Et si vous passiez à une architecture simple, lisible, maintenable par vos propres équipes ?
👉 Écrivez-nous : contact@unnest.co
Partie 2 → Pas à pas : dans les coulisses du projet
Une fois les objectifs définis, nous avons structuré le projet en 6 étapes. Voici le détail de ce qui a été fait, les choix effectués, et les subtilités rencontrées en chemin.
1. Cartographie des sources et des besoins
Avant toute ligne de code, nous avons commencé par un diagnostic très concret :
- Quelles plateformes sont utilisées ? (6 au total)
- Quelles données intéressent vraiment les équipes ?
- À quelle granularité ? (campagne, canal, UTM, pays…)
- Quelles questions récurrentes restent sans réponse ?
➡ Résultat : une première user story map avec une dizaine de cas d’usage identifiés.
2. Connexion des sources de données via Stitch
L’équipe marketing n’a pas d’admin cloud, donc nous avons privilégié une solution simple et robuste : Stitch Data.
- Connecteurs activés : Google Ads, Bing Ads, Meta Ads, LinkedIn Ads, GA4, HubSpot.
- Fréquence : 1 synchronisation quotidienne.
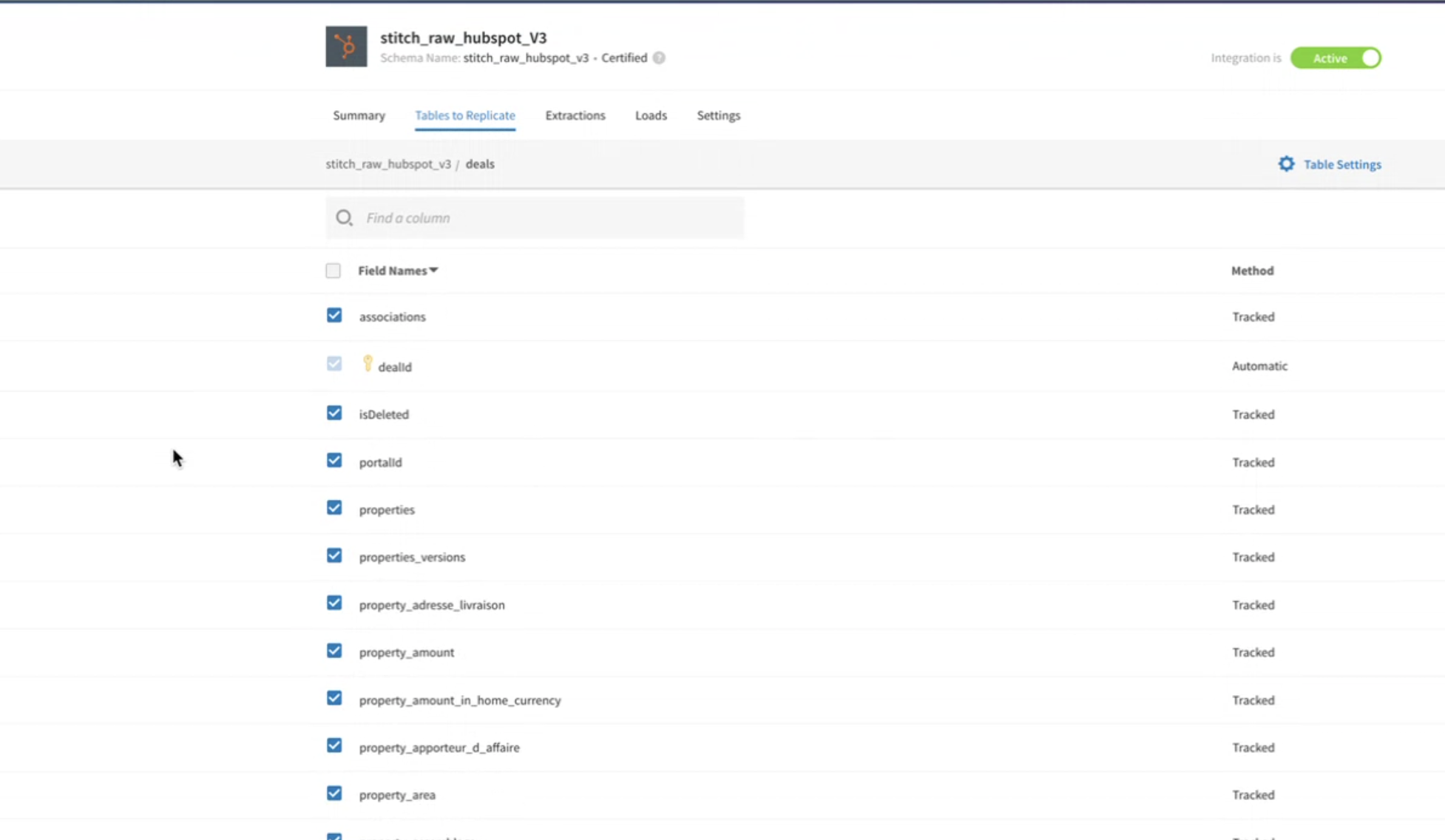
- Spécificité : seuls les champs utiles sont répliqués (ex. :
dealsdans HubSpot).
Pourquoi Stitch et pas les connecteurs natifs ?
- ISO interface : les chiffres sont identiques à ceux vus dans Google Ads ou Meta.
- Simplicité de maintenance (interface 100% web, sans infra).
- Rapidité pour créer les connexions
- Très peu couteux
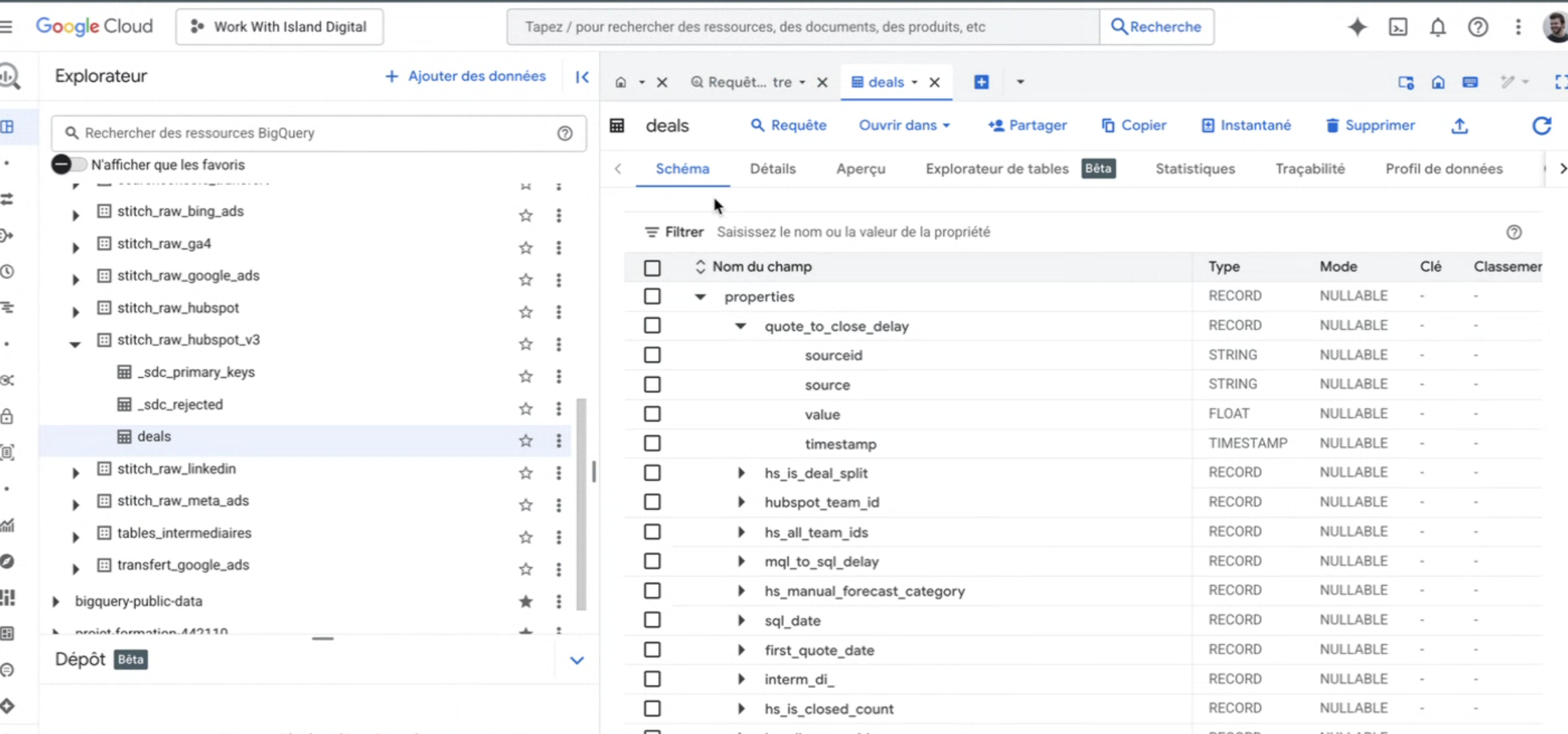
3. Structuration de la donnée dans BigQuery
Une fois les données ingérées, elles sont stockées dans un espace “raw” (
stitch_raw_*). Pour chaque source, nous avons ensuite :- Créé une requête SQL planifiée (scheduled query) qui nettoie, normalise et structure les données.
- Sorti le résultat dans une table dite “mart” (e.g.
mart_google_ads,mart_hubspot_deal_inbound).
Exemples de traitements faits :
- Conversion de timestamps, renaming de colonnes, flatten des champs imbriqués (
RECORDdans HubSpot).
- Suppression des doublons (
propertiesvsproperties_versionsdans HubSpot).
- Normalisation des UTM (
utm_campaign,utm_source,utm_medium, etc.).
« HubSpot, c’est de loin la source la plus piégeuse. Chaque client a ses propres personnalisations, et il faut passer du temps à explorer la donnée brute. »— Xavier
4. Création des datamarts croisés : Paid × HubSpot
L’enjeu central du projet : croiser les coûts publicitaires avec le pipeline HubSpot.
Nous avons donc :
- Agrégé toutes les plateformes Paid dans une table unique
mart_paid.
- Joint cette table à
mart_hubspot_deal_inbound, à la maille de la campagne (utm_campaign,utm_source, etc.).
- Créé une table finale
mart_paid_x_hubspotavec les indicateurs clés : - Investissements
- Clics
- MQL (Marketing Qualified Lead)
- SQL (Sales Qualified Lead)
- Won Value (valeur des deals gagnés)
- ROAS
➡ C’est cette table qui alimente le dashboard principal.
Choix fort : la valeur du deal est attribuée à la date de création du lead (et non à la date de signature). Cela permet d’évaluer le ROI réel d’une campagne au moment où le lead entre dans le funnel.
5. Tests de qualité des données
Pour garantir la confiance dans les chiffres, nous avons mis en place une routine de validation quotidienne :
- Comparaison automatique entre les données BigQuery et les chiffres affichés en interface (HubSpot, Google Ads, etc.).
- Alertes si un écart > 0,5 % est détecté.
- Audit manuel sur les périodes critiques (clôture mensuelle, changement de campagne…).
Cas particulier : GA4
- Deux exports ont été testés : avec et sans la dimension landing page.
- Pourquoi ? Car dans certains cas, la landing provoque des duplications de sessions
- Décision : séparer les usages (landing pour le SEO, sans landing pour le ROI paid).
6. Mise en place des tableaux de bord Looker Studio
Deux dashboards ont été construits :
📊 Dashboard 1 : Paid × HubSpot Overview
- KPI business : investissements, MQL, SQL, Won Value, ROAS.
- Graphique comparatif investissements / clics.
- Vue plateforme par plateforme.
- Filtres : pays, canal, campagne.
📈 Dashboard 2 : Focus Trafic & Investissements
- Vision macro : impressions, CPC, CTR.
- Analyse temporelle des dépenses (S+1, mois glissants…).
- Comparaison multi-plateformes (Google, Bing, Meta, LinkedIn).
➡ Ces dashboards sont consultés chaque semaine, et utilisés au quotidien pour arbitrer les budgets.
7. Documentation & transfert de compétences
L’équipe marketing ne maîtrisait ni SQL, ni BigQuery. Pour garantir l’autonomie à long terme, nous avons :
- Créé une bibliothèque Notion avec des guides concrets :
- Créer une intégration Stitch
- Importer un fichier dans BigQuery
- Modifier une requête SQL
- Décrire les champs de chaque table
- Réalisé une session de transfert (2h) avec démonstration et cas pratiques.
- Vérifié l’adoption : l’équipe a elle-même créé un connecteur NetSuite et une requête de nettoyage – sans assistance externe.
« Il est important que les équipes métier chez nos clients puissent reprendre et enrichir ce que nous développons pour eux, même sans background technique. Et c’est ce qui s’est passé. »— Nicolas
Les auteurs



XAVIER STEVENSSenior data Analyst chez unnest
je vous aide à transformer votre donnée en insights actionnables.
Avec le SQL comme seconde langue vivante, je modélise & transforme tout type de données afin de conduire des analyses et in fine d’aider mes clients à prendre des décisions data driven.
Références : Décathlon, Matmut, Respire, HomeBox, Nutrimuscle
#SQL #bigquery #Looker #data analyse #ETL


NICOLAS CHOLLETPDG et fondateur chez unnest
Nous accompagnons nos clients sur différents sujets autour de la data: digital analytics et mesure du ROI des investissements marketing, cadrage de vos besoins et pilotage de projets data et la structuration et consolidation de la donnée (Data Warehouse).
Références : L’Oréal, Ba&sh, VanCleef & Arpel, Sogexia, KPMG
#consulting #datastrategy #datamarketing