Attention : cet article date de décembre 2021. Les scripts ne sont probablement plus à jour. En revanche, les princicpes persistent.
Dans cet article, nous allons présenter deux manières d'automatiser la vérification des cookies qui sont déposés sur un site web. C'est très utile pour vérifier périodiquement sa conformité au RGPD (au moins en ce qui concerne les cookies).
C'est aussi un prétexte pour utiliser quelques outils intéressants :
- Google Cloud storage (pour stocker un fichier statique)
- Google Cloud Compute Engine (pour créer une machine virtuelle)
- Google Big Query (pour stocker les résultats dans une table)
- Headless Chrome crawler (un crawler javascript)
- Casper js (un autre crawler javascript)
Enfin, dans un prochain article, nous montrerons comment créer un tableau de bord dans Google Data Studio à partir de cette donnée.
Contexte
Dans le cadre du RGPD, il est nécessaire d'obtenir le consentement de l'utilisateur avant le dépôt des cookies non essentiels.
C'est le cas par exemple des cookies de tracking publicitaires, ou encore dans certains cas des cookies d'analytics.
Pour cela, on utilise en général une CMP (Consent Management Platform). Mais malgré tout, des vérifications sont toujours nécessaires. En effet, les cookies peuvent venir de plusieurs sources :
- Parfois, ils proviennent des scripts ajoutés via Google Tag Manager (ou un autre TMS).
- Parfois, ils proviennent d'un bout de code dans la page (typiquement un bouton de partage Facebook, ou une vidéo Youtube). Et il est alors plus difficile de l'identifier.
Il est donc essentiel de pouvoir automatiser la vérification des cookies qui sont déposés sur un site, afin de :
- S'assurer de sa conformité RGPD
- Vérifier périodiquement qu'il n'y a pas de régressions, et déclencher des alertes le cas échéant.
Dans cet article, nous allons passer en revue 2 manières d'automatiser la vérification des cookies.
La première méthode est signée Simo Ahava : https://www.simoahava.com/google-cloud/cookie-audit-with-google-bigquery/ .
La seconde méthode est signée Ray Viljoen : https://github.com/fubralimited/cookie-crawler . Elle a l'avantage d'être simple et robuste, et de pouvoir tourner sur une liste de domaines définis. En revanche, elle ne permet de récupérer que les cookies "first party".
Dans les deux cas, il reste un peu de travail derrière pour industrialiser, mais les bases sont là.
Méthode 1 : Compute Engine / Headless Chrome / Big Query
Globalement, nous suivons le tutoriel suivant : https://www.simoahava.com/google-cloud/cookie-audit-with-google-bigquery/
Certains packages sont nécessaires.
- Python 3
- Git
- Google Cloud SDK
Se loguer sur GCP
Il faut tout d'abord créer un projet dans Google Cloud Platform. Ensuite, dans le terminal, taper :
shellgcloud init
On vous demande alors de vous loguer :
shellTo continue, you must log in. Would you like to log in (Y/n)? Y
Loguez vous dans la fenêtre qui va s'ouvrir, puis dans le terminal, sélectionner son projet :
shellPick cloud project to use: [1] myproject-gcp-282907 [2] Create a new project
Et voilà. Vous devriez maintenant avoir un message du type :
shellgcloud has now been configured! You can use [gcloud config] to change more gcloud settings. Your active configuration is: [default]
Cloner le repo Github
Il se trouve ici : https://github.com/sahava/web-scraper-gcp
Dans le terminal, se mettre dans le répertoire souhaité. Et taper :
shellgit clone https://github.com/sahava/web-scraper-gcp.git
Se placer dans le dossier créé :
shellcd web-scraper-gcp
Puis renommer le fichir config.json.sample en config.json :
shellmv config.json.sample config.json
Editer le fichier config.json. Cela donne quelque chose comme cela :
json{ "domain": "unnest.co", "startUrl": "https://www.unnest.co/", "projectId": "web-scraper-gcp", "skipExternal": false, "bigQuery": { "datasetId": "web_scraper_gcp", "tableId": "crawl_results" }, "redis": { "active": false, "host": "10.0.0.3", "port": 6379 }, "puppeteerArgs": ["--no-sandbox"], "crawlerOptions": { "maxConcurrency": 50, "skipRequestedRedirect": true } }
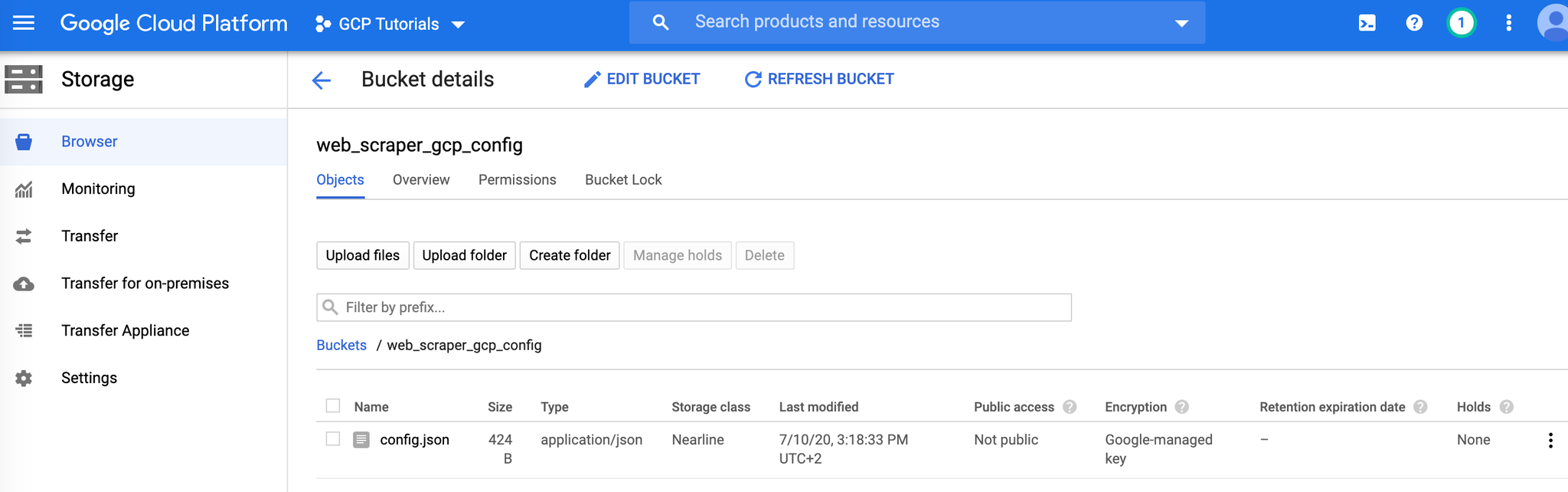
Stocker la config dans Google Cloud Storage
Aller dans l'interface GCS : https://console.cloud.google.com/storage/browser
Créer un nouveau bucket, et uploader le fichier config.json
Editer le script d'installation
Il s'agit du fichier gce-install.sh
Changer le nom du bucket. Par exemple :
shellbucket='gs://web_scraper_gcp_config/config.json'
Activer les différents services dans GCP
Créer l'instance VM Google Cloud Engine
Rentrer le code suivant :
shellgcloud compute instances create web-scraper-gcp \ --metadata-from-file=startup-script=./gce-install.sh \ --scopes=bigquery,cloud-platform \ --machine-type=n1-standard-16 \ --zone=europe-west1-b
Après 1 ou 2 minutes, on obtient un message comme celui-ci, qui indique que la VM a bien été initialisée :

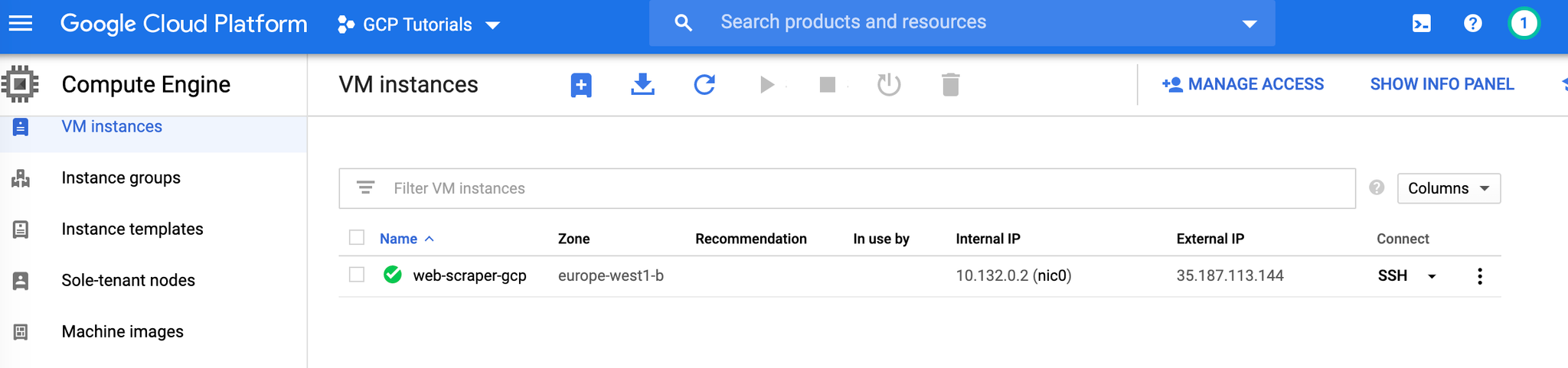
Aller vérifier le résultat
Dans la liste des instances (https://console.cloud.google.com/compute/instances), on voit bien notre instance qui a été créée ici :
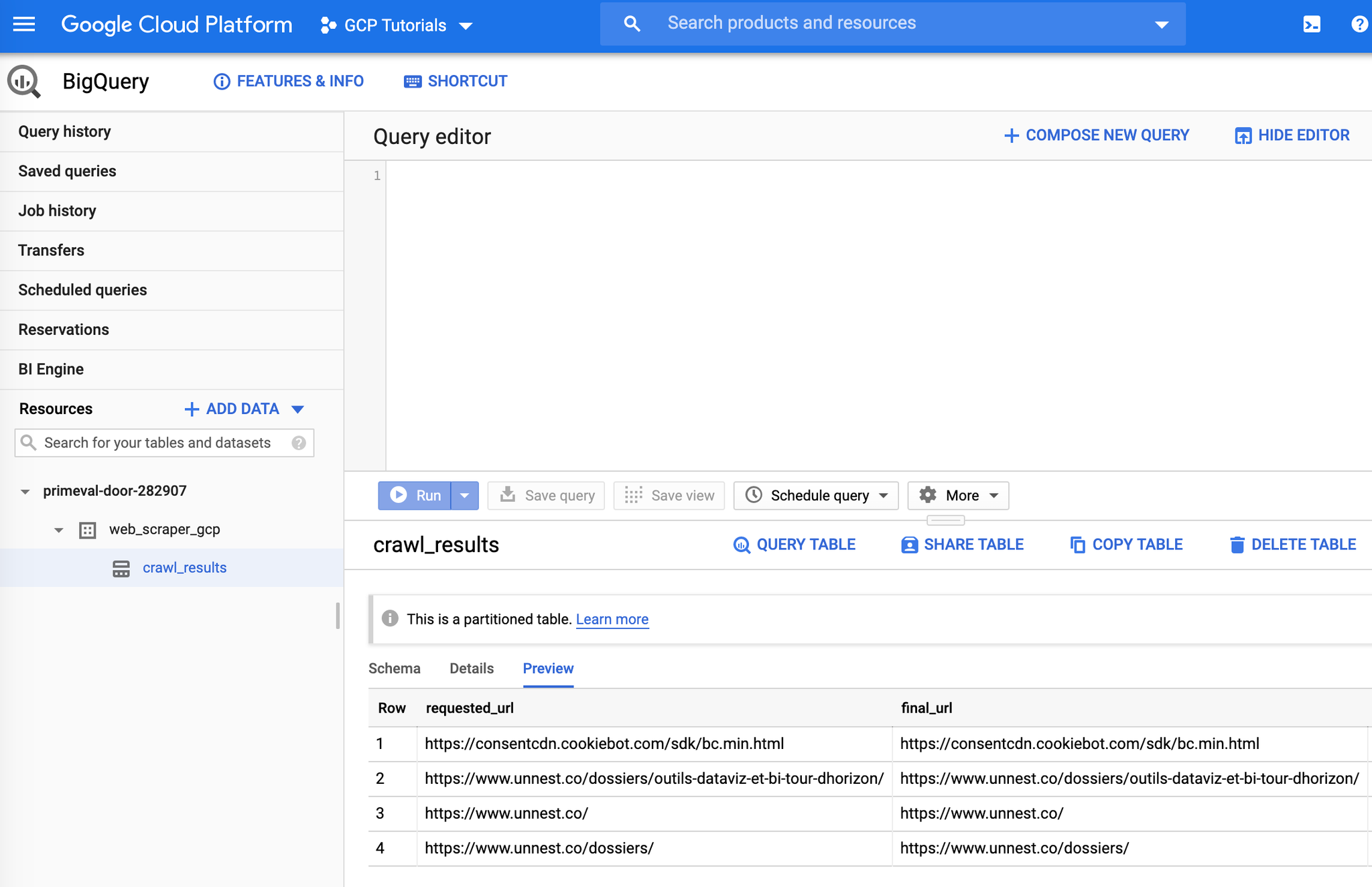
Et dans BigQuery, la liste des URLs crawlées :
Requêter la table
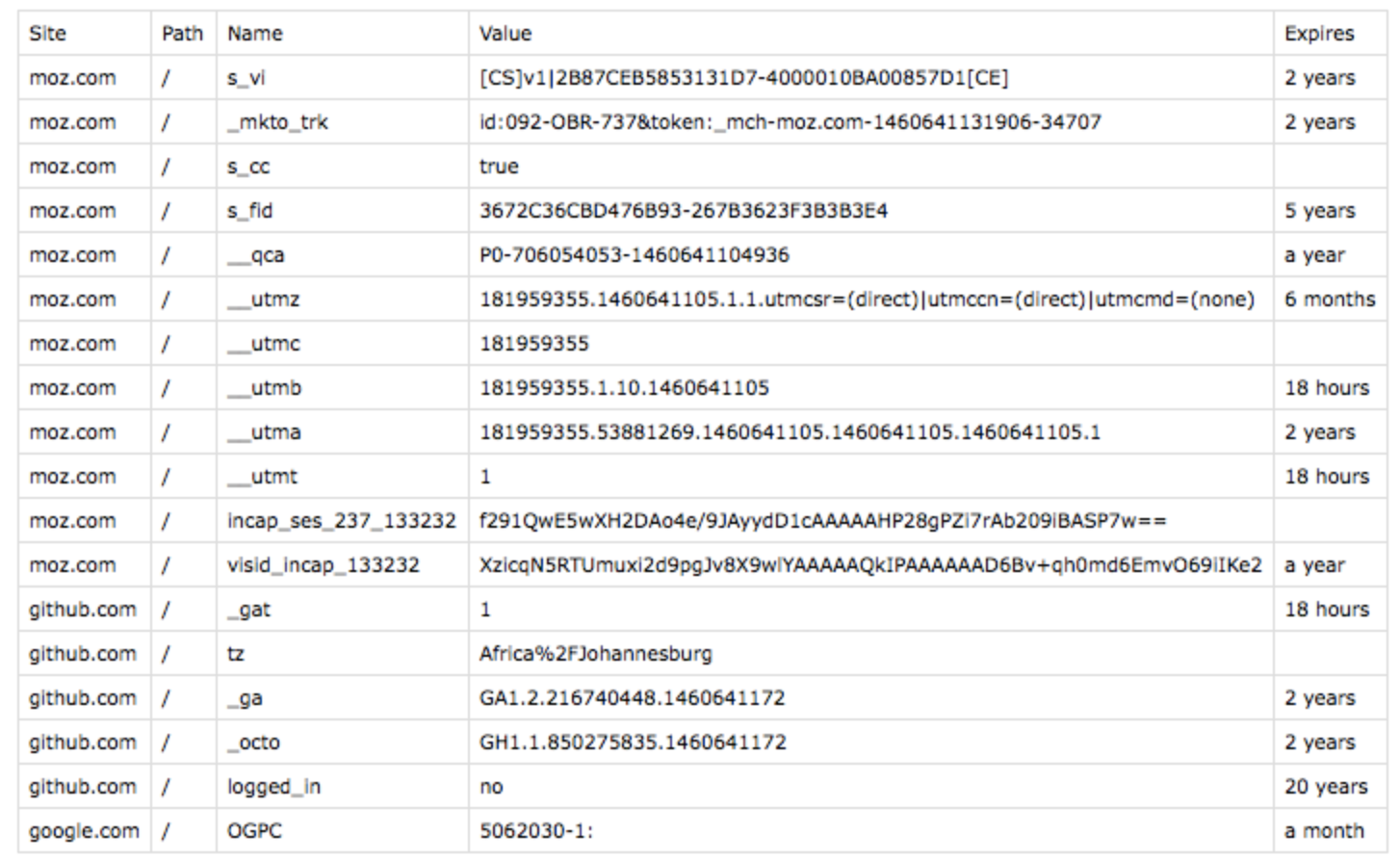
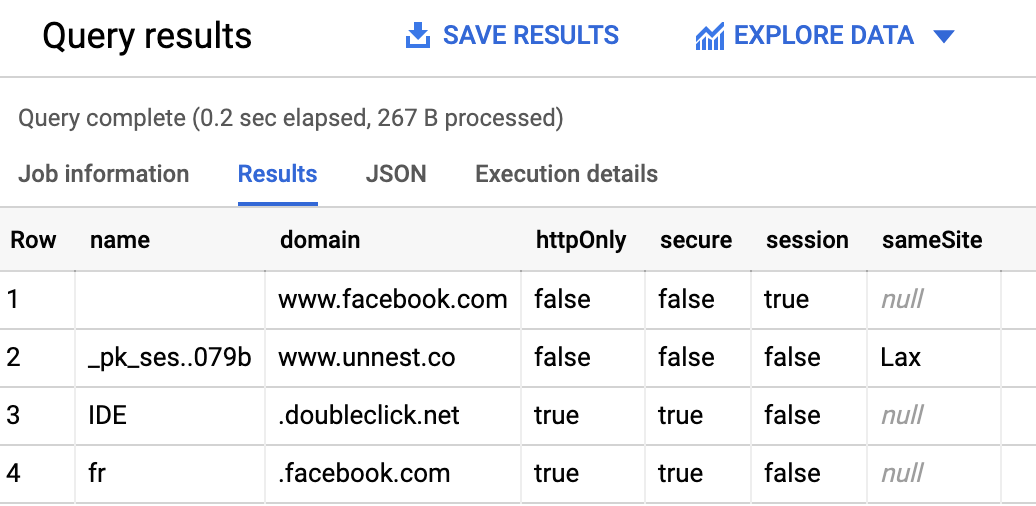
Vous pouvez maintenant requêter la table, par exemple pour afficher tous les cookies qui ont été appelés lors du crawl :
shellSELECT c.name, c.domain, c.httpOnly, c.secure, c.session, c.sameSite FROM `project.dataset.table`, UNNEST(cookies) AS c GROUP BY 1, 2, 3, 4, 5, 6 ORDER BY 1 ASC
Le résultat devrait ressembler à ça :
Méthode 2 : utilitaire CLI en node js, avec casper js
Certains packages sont nécessaires.
- Node js et npm
- Git
- Casper js
Ensuite tout est expliqué ici : https://github.com/fubralimited/cookie-crawler
Cloner le repo, puis se positionner dedans :
shellgit clone https://github.com/fubralimited/cookie-crawler.git cd cookie-crawler
Installer les dépendances :
shellnpm i
Editer le fichier sites.txt et ajouter les domaines et URLs que vous souhaitez tester.
lancer :
shellnpm start
Le script tourne, et stocke les résultats dans le fichier cookies.csv :