
IntroductionOverview de la méthodologie Version simple d’application de la méthodologiePourquoi c’est intéressant ? Y’a qu’à se baisser pour ramasser Parce que les outils qu’on utilise ont de grosses lacunes De nombreuses plus-valuesConclusion : Un premier use case intéressant sur la data x SEO
Introduction
On le sait bien, l’audience c’est le nerf de la guerre en SEO.
Pour beaucoup d’entre vous, c’est un objectif (qui vous est fixé ou que vous vous fixez à vous-mêmes). Pour d’autres, ça permet de faire des petits posts LinkedIn pour se faire mousser (sans échelle c’est encore mieux)… Mais dans tous les cas, c’est ce que l’on regarde et communique en priorité pour valoriser les actions SEO que l’on met en place.
Il est donc important d’être serein sur la donnée qu’on regarde afin d’éviter de se faire taper sur les doigts, de prendre des décisions éclairées par de la bonne lumière, de poster de vrais chiffres sur LinkedIn (même si personne n’ira vérifier…).
Dans cet article, j’avais donc dans l’idée de vous présenter ce que je fais systématiquement pour avoir confiance dans la donnée d’audience que je regarde et pourquoi c’est important de le faire.
Overview de la méthodologie
Dans l’idée, c’est super simple :
- On prend une source d’audience A (généralement la SearchConsole)
- Qu’on croise avec une source B (généralement son outil web analytics)
- Afin de les comparer l’une avec l’autre.
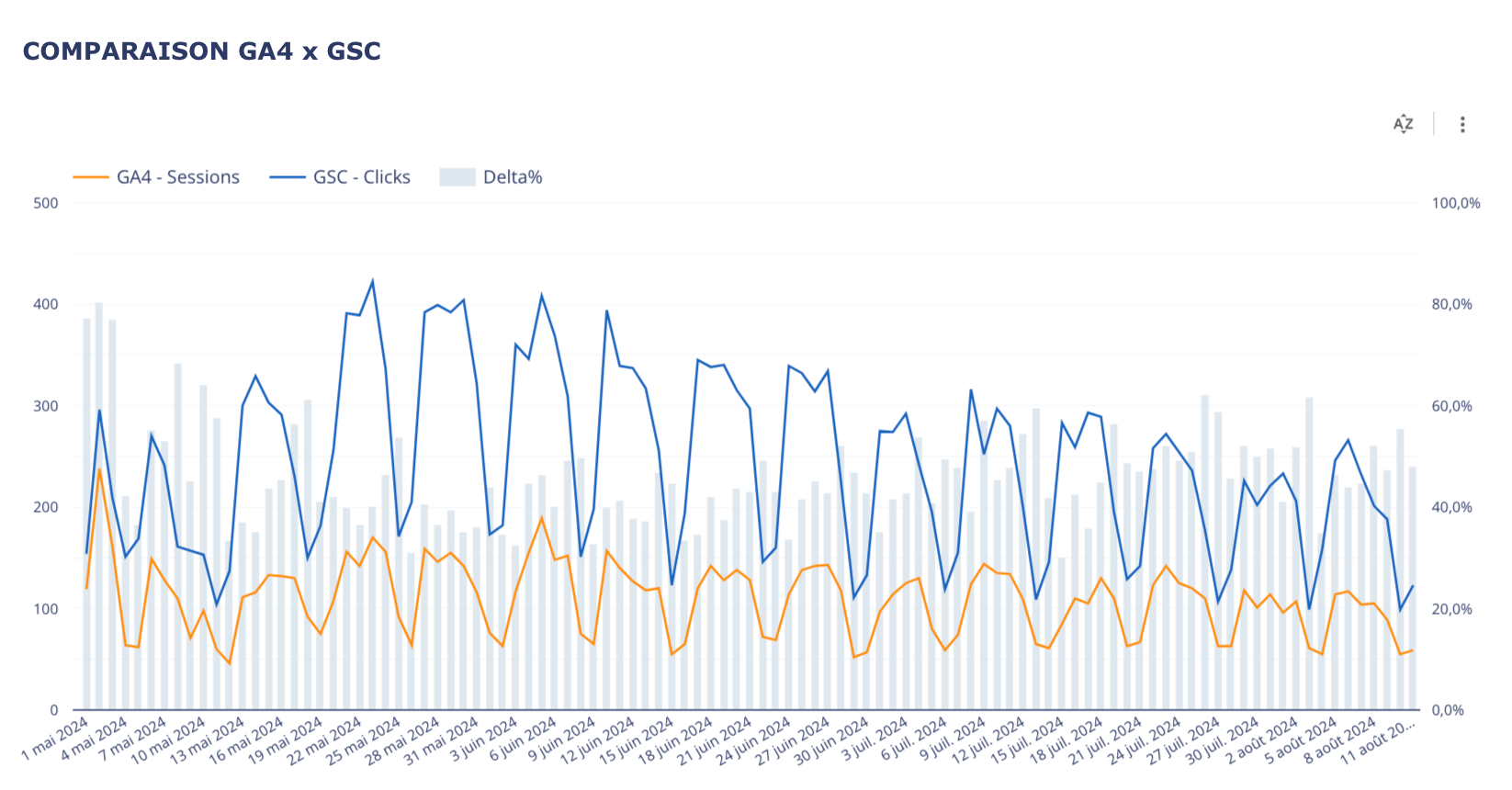
Ci-dessous, un exemple de ce à quoi ça peut ressembler.
Pour aller plus loin
On peut encore ajouter une troisième source (généralement ses logs serveur si on est capable de les récupérer).
Et ainsi de suite si on a encore des sources “fiables” sur lequel s’appuyer
La mise en place n’est pas beaucoup plus complexe, promis 😉
Version simple d’application de la méthodologie
Dans un premier temps, le plus rapide reste encore de passer par les connexions natives entre Looker et la GSC & entre Looker et les outils web analytics classiques.
Looker Studio permet très facilement de connecter ses sources de données et de faire un croisement (blend) assez basique entre les deux.
C’est d’ailleurs cette méthode que j’ai utilisée pour le use case présenté dans la partie overview.
Ci dessous, le blend que j’ai utilisé
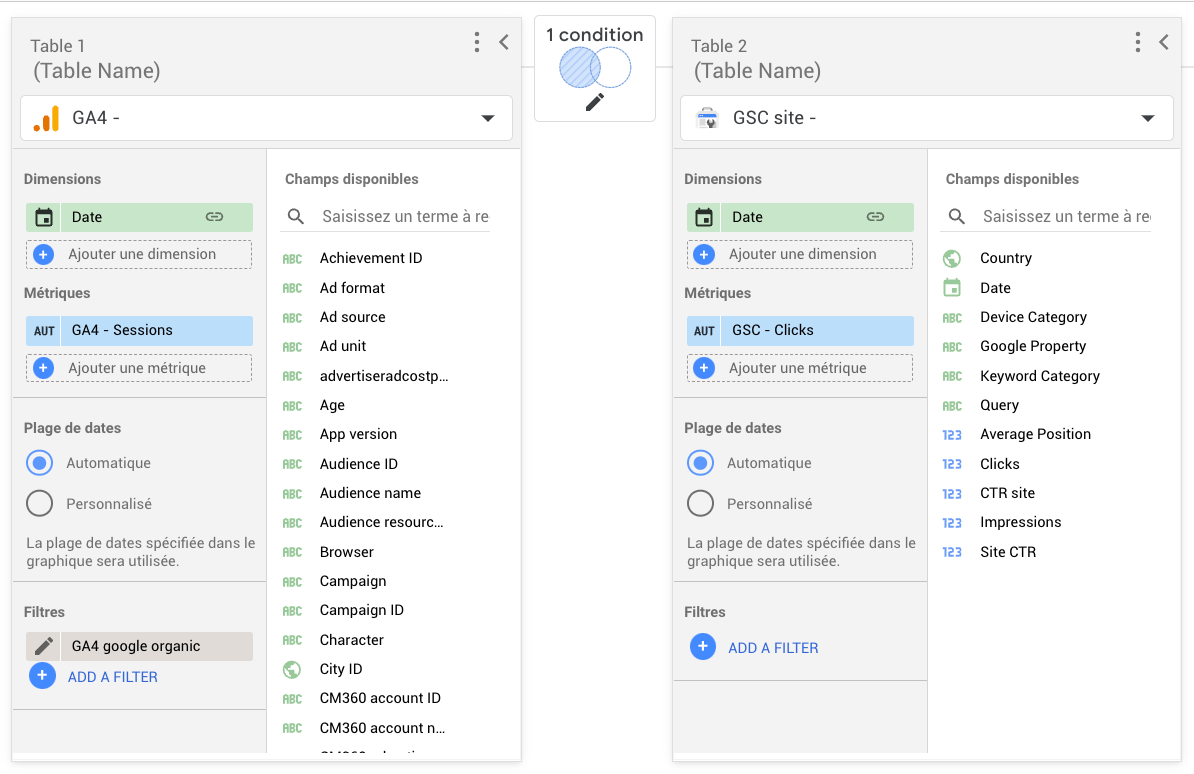
Une fois ce blend fait, il ne reste plus qu’à créer un champ pour calculer l’écart entre les deux sources et faire un beau graphique.
Pour aller plus loin
Une version plus “élaborée” serait de déverser sa donnée dans BigQuery.
Cette version permet plus facilement de faire des croisements et d’anticiper des besoins d’analyse à venir plus complexes.
Pourquoi c’est intéressant ?
Y’a qu’à se baisser pour ramasser
Je pense ne pas trop m’avancer en disant que la stack classique que l’on retrouve dans les équipes SEO c’est :
- Une SearchConsole
- Un outil web analytics comme GA4, Piano ou Matomo (souvent administré par une autre équipe, mais il a le mérite d’exister)
- Dans le meilleur des cas, on a les logs serveur sous la main mais, d’expérience, c’est pas vraiment le scénario le plus fréquent…
--End of Story
→ Et finalement, avec ça, on a tout ce qu’il faut pour commencer.
Parce que les outils qu’on utilise ont de grosses lacunes
SearchConsole :
- Outil administré par google (gratuit qui plus est) ⇒ On sent que ce n’est pas forcément dans leurs priorités même si on profite de temps en temps des nouvelles features…
- De plus en plus de bugs dans la récupération des données.
- Un échantillonnage qui peut être assez prononcé via l’interface selon la volumétrie.
- Le non-provided même si pour cet exemple c’est moins important.
- Les deux scopes qui rendent l’outil peu intuitif et sujet à des erreurs d’interprétations.
- Etc.
GA4 et autre outils web analytics :
(Est-ce que je dois vraiment lister les problèmes potentiels que l’on rencontre tout le temps sur ce genre d’outils ?)
- “Pourquoi j’ai plus rien qui remonte depuis le 30 du mois dernier ?”
- “Ah mais on on track deux fois toutes les sessions la non ?”
- “C’est qui qui a fait le setup du truc ?”
- C’est administré par google (dans le cas de GA4)
- Ça suffira comme ça, après je suis tendu pour la journée.
Globalement, tous les outils ont des lacunes et le fait de multiplier les sources permet de limiter les risques.
De nombreuses plus-values
En plus des aspects “techniques” mentionnés dans les deux premières sous-parties, on peut noter un certain nombre de plus-values, notamment :
- Renforcer la fiabilité de vos données En multipliant les comparaisons de sources, on limite les problèmes de fiabilités inhérents aux outils que nous utilisons.
- Alerting Rien de mieux qu’un exemple pour illustrer mon propos :
- Baisse des audiences reportées par GA4
- Maintien des audiences GSC
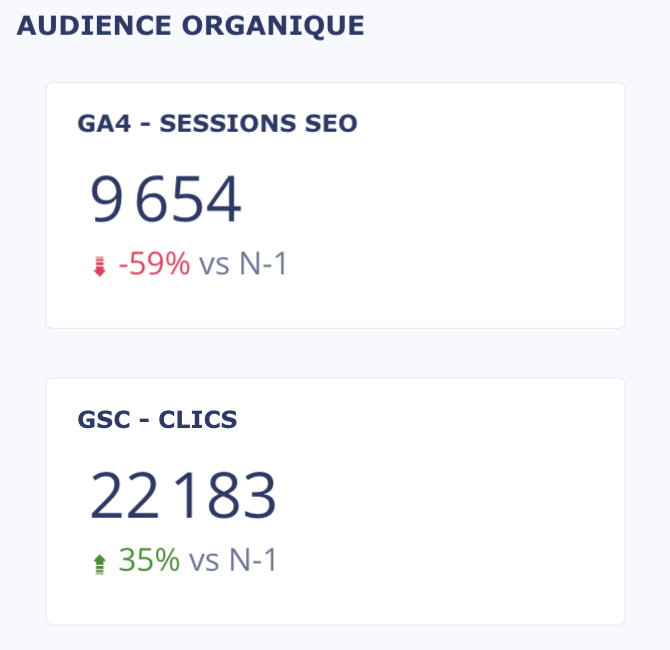
- Les GA4 qui passe de 110-125% des clicks GSC à environ 50%
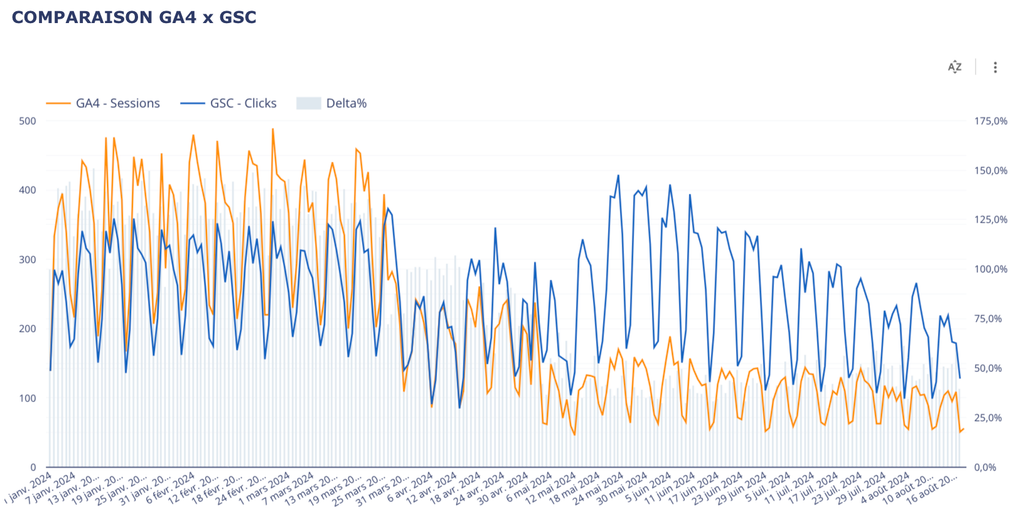
→ Sur ce screenshot, on observe un écartement des courbes d’audience SEO GA4 des clicks GSC.
Constats
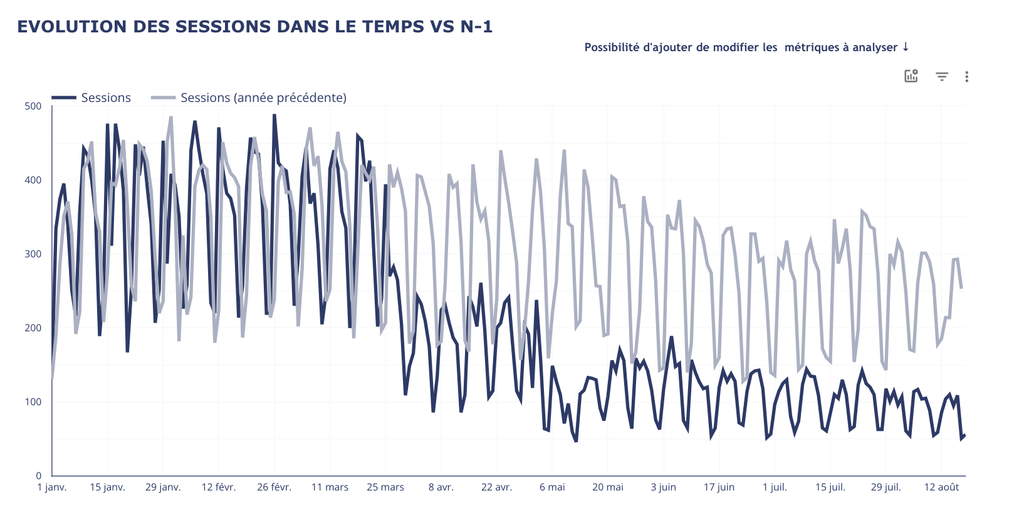
Si on ne regardait son audience uniquement par le prisme de GA4, on pourrait avoir un coup de chaud en regardant sa courbe d’audience.
→ Audiences GA4
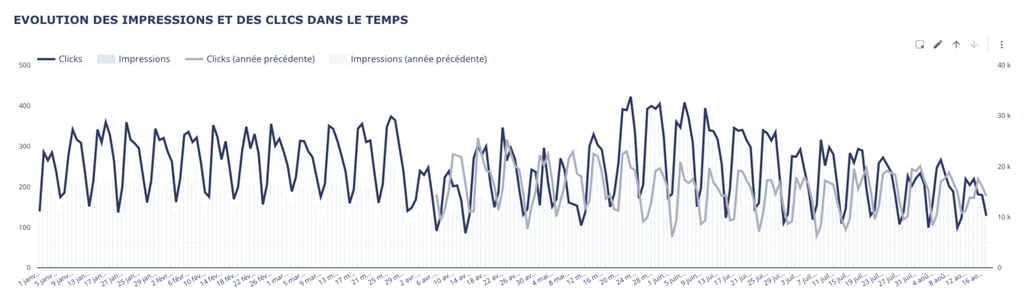
Mais en parallèle, on voit bien que les audiences SEO ne sont pas en baisse selon la SearchConsole.
Audience SearchConsole
A retenir
Le graphique combiné nous donne directement cette information et nous permet d’identifier immédiatement le problème de qualité sur la donnée GA4.
Dans la mesure ou on observe une baisse très subite et très marquée du côté des audiences GA4, on se doute que le souci est plutôt de ce côté.
Dans ce cas précis, la baisse GA4 est artificielle et vient simplement de la mise en place du consent mode.
L’idée est surtout d’identifier rapidement le problème et d’éviter la panique suite à la découverte (et de partir dans une analyse approfondie d’un problème qui n’existe pas…).
- Éviter les erreurs d’interprétations L’exemple précédent est un peu extrême et aurait dans tous les cas dû faire, à minima, l’objet d’une petite vérification… Mais on peut imaginer un cas moins extrême où on aurait pu prendre un raccourci et communiquer sur une baisse d’audience qui n’existe pas.
- Anticipation des besoins futurs (particulièrement dans le cas ou l’on passe par BigQuery et pas simplement par les connecteurs natifs) Commencer à centraliser ses données dans un DataLake pour les croiser ensuite via BigQuery + Looker est un passage quasi obligatoire si on veut aller plus loin dans ses analyses.
Conclusion : Un premier use case intéressant sur la data x SEO
Sécuriser son audience, c’est crucial pour un responsable SEO. En croisant plusieurs sources de données, on limite les risques d’erreurs, on fiabilise l’un des KPIs les plus critiques et on est plus serein sur la donnée que l’on regarde.
Cependant, le plus important selon moi c’est que ce use case constitue un premier pas simple vers des sujets de data SEO plus ambitieux. Un premier cas d’usage à la fois utile et complet qui allie centralisation, traitement et activation de votre donnée.
Si vous avez des questions ou des besoins sur vos sujets data SEO (ou vos sujets data tout court d’ailleurs, n’hésitez pas à me contacter sur linkedin pour en discuter.
Sur ce, Ciao !