
Dans le premier article de cette série, on a posé les bases : IA, LLM, GEO, GSO, ce que recouvrent ces concepts, comment les outils comme ChatGPT explorent le web, et pourquoi cela change profondément les règles de la visibilité en ligne.
👉 Le constat était simple : l’enjeu n’est plus seulement d’être bien positionné sur Google, mais d’être présent dans les réponses générées par les IA.
Reste une question clé : comment savoir si on y arrive ?
Contrairement au SEO, il n’existe pas encore de “Search Console” des IA.
→ Pas de métriques standardisées, peu de données de marché, et des outils encore en construction.
Pourtant, il est déjà possible de mesurer, analyser et piloter sa présence dans ces environnements, à condition de croiser plusieurs sources de données.
Dans cet article, on va voir concrètement ce qu’on peut mesurer, comment, et pourquoi ça compte, à travers trois angles complémentaires :
• L’audience on-site : ce que vos outils analytics captent déjà
• Les logs serveurs : comment les robots IA consomment vos contenus
• La visibilité dans les réponses IA : ce que les modèles disent réellement de vous
Trois briques, trois niveaux de lecture, qui, combinés, permettent de passer d’une vision partielle à une lecture réellement exploitable de votre présence dans les environnements IA.
1. L’audience on-site : ce que vos analytics vous disent déjà1.1. Un nouveau canal apparaît dans vos dashboards1.2. Un trafic petit en volume, mais différent en qualité1.3. Mais si le visiteur arrive ici… c’est que quelque chose s’est passé avant2. Les logs serveurs : comprendre comment les IA consomment votre contenu2.1. Rappel : les logs, c’est quoi ?2.2. Ce qu’on peut y trouver.2.3. Les User-Agents à isoler2.4. Les prérequis pour que les robots IA viennent (et reviennent)2.5. Présentation d’un exemple2.6 En définitive3. La visibilité dans les réponses IA : suivre ce que les outils disent de vous3.1. Une nouvelle source de données3.2. Premier pas : constituer ses bases de prompts3.3. Et ensuite - comment on monitore tout ça ?3.4. Présentation d'un exemple de monitoringConclusion — Croiser les 3 briques pour avoir une lecture complète
1. L’audience on-site : ce que vos analytics vous disent déjà
1.1. Un nouveau canal apparaît dans vos dashboards
Bonne nouvelle : vous n’avez pas besoin d’un outil révolutionnaire pour commencer.
Vos outils analytics habituels (GA4, Piano, etc.) captent déjà le trafic référent depuis les plateformes IA : chatgpt.com, perplexity.ai, gemini.google.com, copilot.microsoft.com…
Certains outils, comme Piano, le catégorisent même automatiquement dans un canal dédié (“Generative AI”).
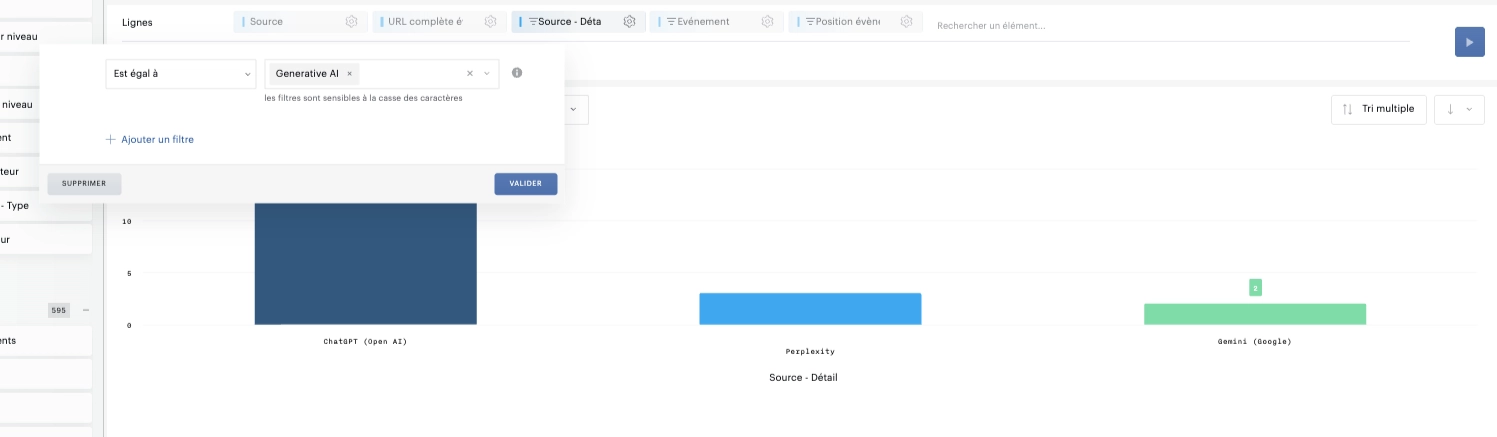
Sur GA4, il faudra créer un segment ou un canal personnalisé en filtrant sur les domaines IA.

Ce trafic reste généralement modeste en volume — les plateformes IA représentent encore moins de 2 % du trafic web global.
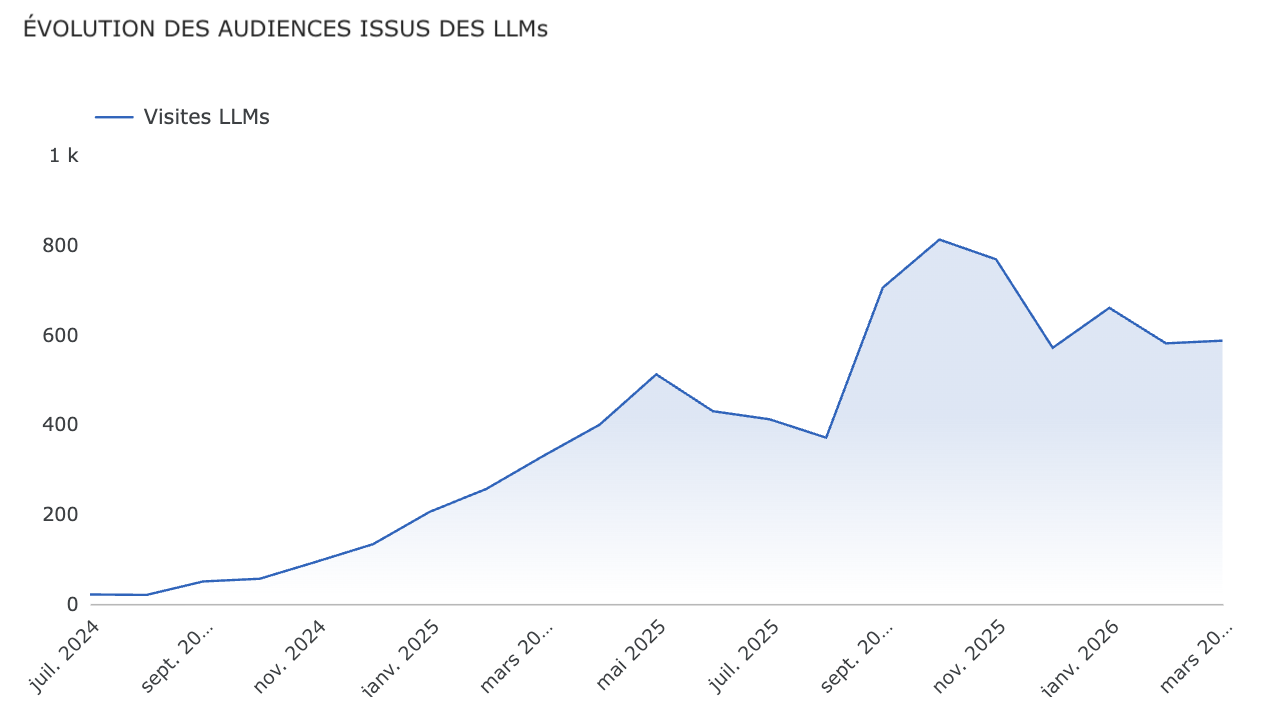
Cependant, il croît rapidement, et surtout, il se comporte différemment.
1.2. Un trafic petit en volume, mais différent en qualité
Une fois ce canal isolé, on peut le mesurer l’ensembles des KPIs classiques, comme on le ferait pour le SEO ou le Paid : audience, pages vues, taux de rebond, taux de conversion…
Et c’est là que les choses deviennent intéressantes.
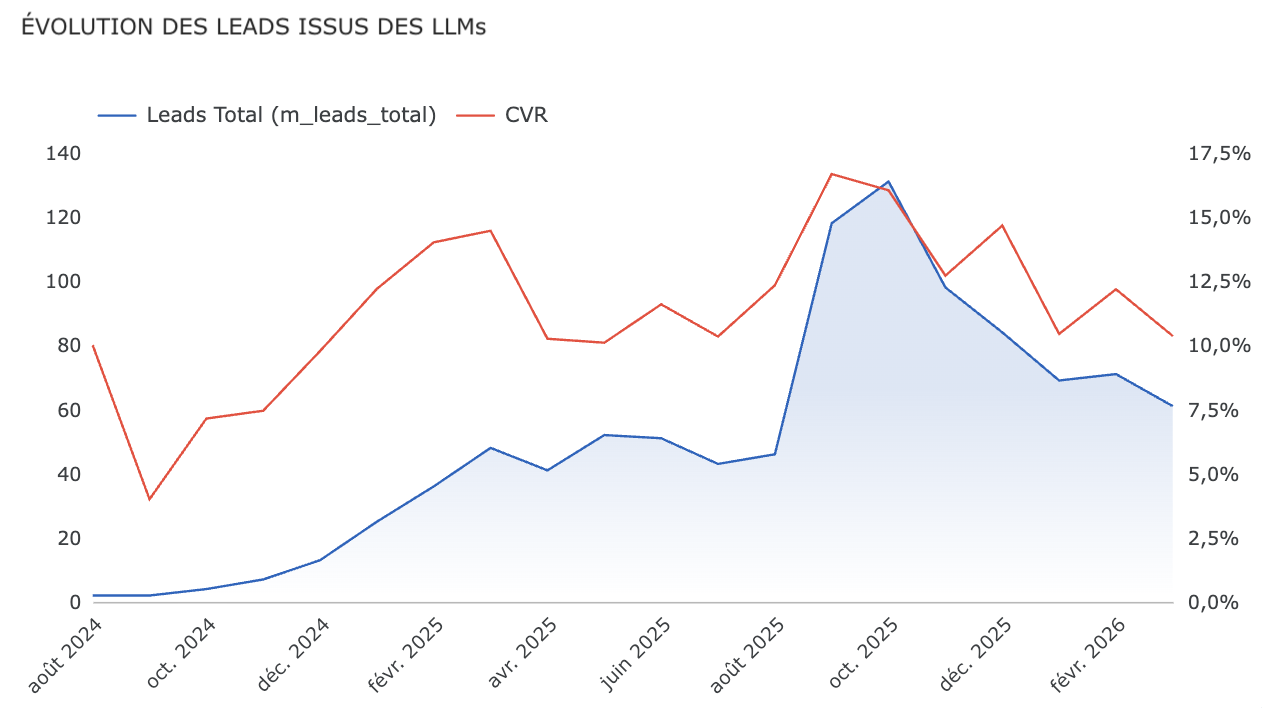
👉 Retour d’expérience : Chez un de nos clients, le trafic référé par les IA affiche un taux de conversion presque 2 à 3 fois supérieur au SEO classique — sur un volume encore faible, mais en croissance constante.
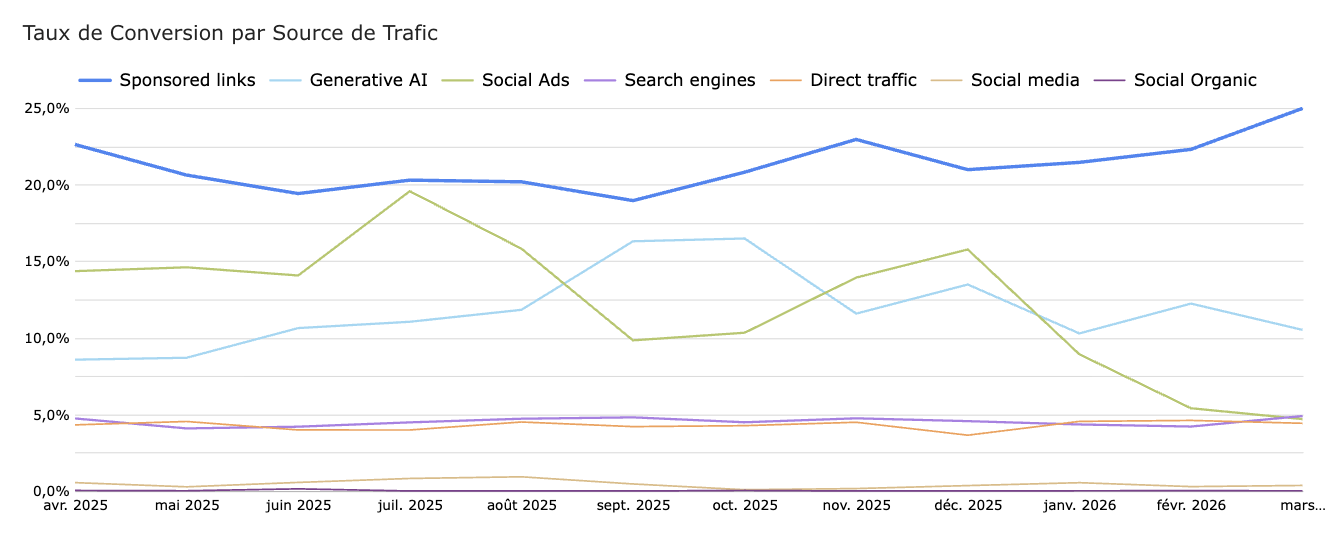
Ces observations sont également corroborées par un certains nombre d’études sur le sujet :
- SimilarWeb : “Ecommerce websites are attracting a small but fast growing and important share of traffic from AI chatbots like ChatGPT. Similarweb estimates the conversion rate for visits referred by ChatGPT is 11.4%, compared with 5.3% for organic search. https://ir.similarweb.com/news-events/press-releases/detail/132/similarwebs-3rd-annual-global-ecommerce-report-growth-shifts-to-apps-and-ai
- Ahref : “AI search visitors convert at a 23x higher rate than traditional organic search visitors for Ahrefs” https://ahrefs.com/blog/ai-search-traffic-conversions-ahrefs/
- Seerinteractive : “ChatGPT had a conversion rate of 16% compared to Google Organic’s 1.8%” https://www.seerinteractive.com/insights/case-study-6-learnings-about-how-traffic-from-chatgpt-converts
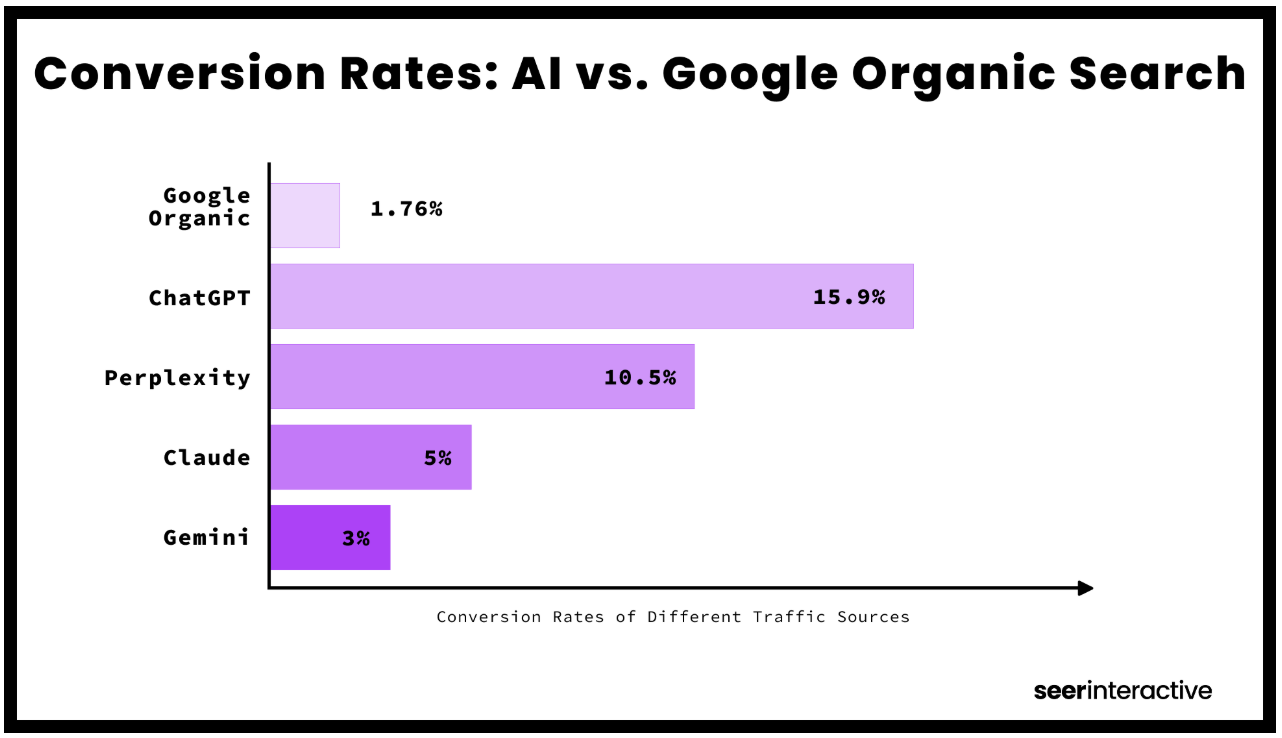
→ Le trafic IA n’est pas (encore) un canal de volume mais c’est un canal de qualité.
1.3. Mais si le visiteur arrive ici… c’est que quelque chose s’est passé avant
Ces visiteurs qui convertissent si bien ne tombent pas du ciel. S’ils arrivent sur votre site via ChatGPT ou Perplexity, c’est qu’en amont :
- votre contenu a été trouvé par les robots IA,
- il a été exploré par ces derniers
- il a été jugé suffisamment pertinent pour être utilisé dans une réponse
- et l’utilisateur a choisi de cliquer sur votre lien plutôt qu’un autre.
La donnée site-centric ne mesure que la dernière étape. Pour comprendre ce qui se passe en amont — et s’assurer que vos contenus sont bien consommés par les LLMs — il faut combiner cette vue avec d’autres sources de donnée.
2. Les logs serveurs : comprendre comment les IA consomment votre contenu
2.1. Rappel : les logs, c’est quoi ?
Pour mes collègues du SEO, vous connaissez déjà les logs serveurs — pour les autres, on en a parlé dans le premier article.
TLDR ; chaque fois qu’un visiteur — humain ou robot — accède à une page de votre site, le serveur enregistre une empreinte. Consignée dans une ligne de log.
Cette empreinte contient des informations simples mais précieuses : quelle page a été demandée, à quelle heure, par quel type de visiteur (vous, Googlebot, robot ChatGPT…), comment la page a répondu , etc.
👉 En gros, c’est la boîte noire de votre site.
2.2. Ce qu’on peut y trouver.
À partir de ces empreintes, on peut reconstituer pas mal de choses :
- Quels robots IA visitent votre site — et lesquels ne viennent pas
- Quelles pages les intéressent — et à quelle fréquence ils vont les voir
- Si vos contenus sont accessibles pour eux — ou si des erreurs les bloquent
- Comment évolue leur intérêt dans le temps
C’est de la donnée brute, côté serveur — pas de problème de consentement. Et c’est un outil de pilotage puissant pour comprendre comment les LLMs consomment réellement vos contenus.
2.3. Les User-Agents à isoler
OnCrawl à fait un gros travail de consolidation que vous pouvez trouver sur leur helpdesk :
https://help.oncrawl.com/en/articles/12556120-oncrawl-log-analyzer-supported-bots-list
→ Vous y retrouverez l’ensemble des UA communément trouvés dans vos logs (pas seulement ceux des robots IA d’ailleurs).
Voici un tableau d’exemple centré sur les principaux outils IA avec leur rôle :
Éditeur | Bot (User-Agent) | Type |
OpenAI | GPTBot | 🧠 Entraînement |
OpenAI | OAI-SearchBot | 🔍 Recherche |
OpenAI | ChatGPT-User | 👤 Action utilisateur |
Anthropic | ClaudeBot | 🧠 Entraînement |
Anthropic | Claude-SearchBot | 🔍 Recherche |
Anthropic | Claude-User | 👤 Action utilisateur |
Perplexity | PerplexityBot | 🔍 Recherche |
Perplexity | Perplexity-User | 👤 Action utilisateur |
2.4. Les prérequis pour que les robots IA viennent (et reviennent)
Avant même de monitorer les bots IA dans vos logs, encore faut-il qu’ils puissent accéder à vos contenus.
Quelques pré-requis à vérifier :
- Crawlabilité : vos pages ne doivent pas être bloquées aux robots IA dans le robots.txt. Un
Disallowsur GPTBot ou OAI-SearchBot et vous disparaissez de leur radars.
- Accessibilité : les bots IA ne sont pas aussi sophistiqués que Googlebot. Si votre contenu nécessite l’exécution de JavaScript pour s’afficher, la plupart des crawlers IA ne le verront pas. Même chose pour les contenus derrière un paywall ou un login.
- Indexation : C’est un point que nous avons notamment détaillé dans le premier article. Aujourd’hui, les moteurs de recherches servent aux outils IA pour pré-qualifier les documents (bonne position SEO ⇔ Pertinence/Qualité).
Certains robots utilisent les moteurs de recherche pour explorer les contenus et générer leurs réponses ; l’indexation et le positionnement SEO sont donc des quasi pré-requis.
- Réponse serveur : une page qui retourne une erreur 403, 404 ou 5xx au bot IA, c’est une page invisible.
Attention aux CDN/WAF : Cloudflare inclut les crawlers IA dans les "Verified bots" par défaut, mais l'option "Block AI bots" peut les bloquer. Certaines autres solutions peuvent également les bloquer par défaut.
👉 En résumé : les règles de base du SEO technique s’appliquent aussi aux bots IA, avec une exigence encore plus forte sur l’accessibilité et la configuration des accès robots.
2.5. Présentation d’un exemple
Je vois bien que vous trouvez toujours ça un peu flou…
J’ai donc récupéré un extract de logs d’un de nos clients unnest pour aller un peu plus dans le concret. Vous trouverez ci-dessous quelques éléments d’analyses :
Volume de hits mensuels (comparé aux hits GBot) :
Mois | Googlebot | AI Search | AI User | AI Training | AI Total | Ratio AI / Google |
Jul 2025 | 96 142 | 17 999 | 12 110 | 2 115 | 32 224 | 0.34x |
Aug 2025 | 298 171 | 9 928 | 30 511 | 4 772 | 45 211 | 0.15x |
Sep 2025 | 205 853 | 17 759 | 36 211 | 13 549 | 67 519 | 0.33x |
Oct 2025 | 112 637 | 21 760 | 44 809 | 24 294 | 90 863 | 0.81x |
Nov 2025 | 96 636 | 39 997 | 49 427 | 13 509 | 102 933 | 1.07x |
Dec 2025 | 189 272 | 25 715 | 55 533 | 22 711 | 103 959 | 0.55x |
Jan 2026 | 97 743 | 8 165 | 25 797 | 7 729 | 41 691 | 0.43x |
- Un volume sensiblement comparable à Google Bot
- AI User est le segment principal du trafic Gen AI (52% du total). → C’est le trafic qui se traduit directement en citations dans les réponses IA.
- AI Training reste modeste : mais malgré tout, non négligeable. → Les outils continuent de les utiliser pour l’amélioration continue des modèles. → Correspond à la part “dispensable” du trafic des bots, que l’on peut couper sans risque de perdre en visibilité dans les LLMs.
- OpenAI représente à lui seul plus de 80% du crawl Gen AI sur ce site. Anthropic (Claude) arrive second avec ~14%, principalement via son bot d'entraînement. Perplexity complète le podium à ~5%
Marque | Bots | Hits | % du total Gen AI |
OpenAI | ChatGPT-User, OAI-SearchBot, GPTBot | 394 656 | 81,5% |
Anthropic (Claude) | ClaudeBot, Claude-User | 65 974 | 13,6% |
Perplexity | PerplexityBot, Perplexity-User | 22 894 | 4,7% |
Autres | MistralAI-User, Gemini-Deep-Research, DeepSeek | 386 | < 0,1% |
Catégorie | AI Search | AI User | AI Training | Visites ref. Gen AI | Visites / 1 000 hits AI User |
Homepage | 1 499 | 14 215 | 6 605 | 542 | 38,1 |
Recherche d’adoption | 2 173 | 7 569 | 18 486 | 179 | 23,6 |
Engagement / Bénévolat / Emploi | 1 991 | 16 574 | 2 217 | 173 | 10,4 |
Pages refuge / dispensaire | 2 417 | 54 989 | 5 948 | 340 | 6,2 |
Guide adoption | 2 432 | 30 890 | 5 320 | 183 | 5,9 |
Institutionnel | 946 | 17 759 | 1 893 | 102 | 5,7 |
Aides & services | 389 | 8 729 | 338 | 21 | 2,4 |
Guides pratiques – Chats | 5 720 | 28 996 | 2 975 | 32 | 1,1 |
Guides pratiques – Chiens | 3 869 | 25 661 | 4 011 | 27 | 1,1 |
Guides pratiques – Autres | 495 | 5 041 | 928 | 4 | 0,8 |
Autre | 110 226 | 38 794 | 152 935 | 381 | 9,8 |
👉 Plusieurs constats/conjectures :
- Les guides pratiques sont le cas d’école du “content-answer” : 54 700 hits AI User cumulés (Chats + Chiens + Autres), 63 visites referrer seulement. Taux de conversion ~1 pour 1 000 hits AI User. L’IA aspire le contenu pour répondre directement dans sa réponse et ne renvoie quasiment jamais.
- La Homepage est à l’opposé : 38 visites pour 1 000 hits AI User — 35× mieux que les guides.
- Les pages “actionnables” (adoption search, bénévolat) surperforment aussi (10–24 visites / 1 000 AI User). Quand l’utilisateur a une intention concrète, l’IA dirige vers le site parce qu’elle ne peut pas satisfaire l’action elle-même.
- Les pages refuge individuelles ont un volume énorme d’AI User mais un taux de conversion moyen (6,2). L’IA les lit beaucoup (infos locales précises : adresse, horaires, animaux disponibles) mais ramène peu — elle sert l’info directement dans la réponse.
- La corrélation entre la partie Search et la partie User est significative. Plus une URL est crawlée fréquemment, plus elle est utilisée comme source potentielle dans les réponses. → le volume de crawl AI Search est un bon prédicteur du volume de citation
- Pour ce qui est de la corrélation entre Hits et Audience :
- Au niveau macro, une corrélation existe mais est modérée (0.57)
- C’est en allant au plus fin que cette corrélation prend tout son sens.
- La corrélation s'effondre à 0,2–0,4 sur les guides pratiques (où l'IA aspire le contenu pour répondre sans rediriger)
- Elle monte à 0,7–0,8 sur les pages refuge, institutionnelles et actionnables (où l'IA redirige parce qu'elle ne peut pas satisfaire l'action)
2.6 En définitive
- Les logs nous donnent donc une vision de ce qui se passe côté serveur : quels bots passent, à quelle fréquence, sur quelles pages, et si ces visites se traduisent (ou non) en trafic réel.
- On peut en tirer des KPIs concrets — volume de crawl par bot, évolution dans le temps, corrélation entre le passage des différents robots, la citation potentielle et la visite des utilisateurs.
Cependant, quoi qu’on fasse, on a un angle mort. Pour aller au bout de l'analyse, il faudrait pouvoir répondre à plusieurs questions que les logs ne couvrent pas :
- Quand l'IA utilise nos guides, cite-t-elle la source ? Ou se contente-t-elle d'aspirer le contenu ?
- Quand elle cite, est-ce qu’elle le fait avec un lien cliquable ou juste une mention textuelle ?
- Comment formule-t-elle la réponse ? Reprend-elle nos arguments fidèlement, ou les reformule-t-elle (au risque d'altérer le message) ?
- Est-ce que le comportement outil change réellement selon l'intention, ou est-ce que la corrélation s’explique uniquement par une logique user ?
👉 Pour répondre à ces questions, il faut aller voir concrètement comment les IA traitent les questions de nos utilisateurs, comment elles construisent leurs réponses, et quelle place elles donnent (ou non) à votre marque selon le type de question posée.
3. La visibilité dans les réponses IA : suivre ce que les outils disent de vous
3.1. Une nouvelle source de données
Avec l’audience on-site et les logs serveurs, on commence à y voir plus clair. Mais il manque encore une pièce au puzzle : qu’est-ce que les IA disent réellement de vous dans leurs réponses ?
C’est une donnée qui n’existait tout simplement pas il y a deux ans. Aujourd’hui, c’est tout un tas de nouvelles métriques à analyser :
- Citations : combien de fois votre marque ou votre domaine est utilisé comme source dans les réponses.
- Mentions : mention textuelle de la marque — avec ou sans lien vers votre site
- Sentiment : la mention est-elle positive, neutre ou négative ? → Est-ce que les points négatifs qu’elle dit de vous sont pertinents & justifié ?
- Position dans la réponse : suis-je cité avant mes concurrents ?
- Share of Voice IA : votre part de visibilité par rapport à vos concurrents, sur une thématique donnée.
Mais soyons honnêtes : pour l’instant en termes de data, c’est pas foufou.
Contrairement au SEO où les données de volume de recherche, de trafic et de positionnement sont (plus ou moins) disponibles et standardisées, le GEO ne dispose pas encore de données de marché fiables & Les éditeurs d’outils ne communiquent pas (encore) grand-chose.
ndlr : Pas de paid, pas de data
Pour avancer, on utilise surtout des proxys — exactement ceux qu’on a vus dans les briques précédentes (les logs, l’audience référente) — et les compléter avec de la donnée existante (De la donnée SEO et/ou SEA par exemple) pour construire un premier cadre d’analyse.
3.2. Premier pas : constituer ses bases de prompts
Tous les outils de monitoring GEO fonctionnent sur le même principe : on envoie des prompts aux LLMs, et on regarde ce qu’il se passe.
La qualité du monitoring dépend donc entièrement de la pertinence de la base de prompts que nous constituons.
Voici quelques approches complémentaires pour y parvenir :
On se pose et on réfléchit un peu à son business, à son site
👉 Qu'est-ce qu'un utilisateur pourrait chercher à savoir ou à faire, et pour lequel je devrais être pertinent ?
Concrètement :
- Lister des scénarios et des intentions : "je veux adopter un chaton", "mon chat est malade la nuit", "quel refuge près de chez moi"…
- Penser en personas : un primo-adoptant ne pose pas les mêmes questions qu'un propriétaire expérimenté.
- Solliciter vos clients et vos équipes : le support client, les commerciaux, les FAQ — ce sont des mines d'or de questions réelles.
→ Dériver tout ça en prompts — soit vous-même, soit avec l'aide d'une IA d’ailleurs.
Le plus simple : utiliser ce qu’on a déjà.
Sur la même logique que celles décrite dans le 1. , vous pouvez aller chercher de la données sur ce qui intéressent vos utilisateurs :
- Vos mots-clés SEO, vos requêtes Search Console, vos données SEA — tout ça peut être converti en prompts.
- "Stérilisation chat prix" → "Combien coûte la stérilisation d’un chat ?"
- Les People Also Ask sont un pont naturel entre les deux mondes — elles sont déjà formulées en questions.
- C’est la méthodo qu’à notamment utilisé Ahref pour constituer sa base de prompts.
Des plateformes spécialisées construisent des bases de centaines de millions de prompts réels, issus de panels consommateurs ou de données de navigation.
Elles permettent d’aller rapidement chercher du volume sur un business, des intentions précises. Dans certains cas, ça permet même de découvrir les questions que les utilisateurs posent réellement aux IA dans votre thématique.
→ C’est un raccourci puissant, mais souvent réservé aux budgets enterprise.
Quelques exemples de tools :
- Profound disposent de bases de 400M+ conversations réelles issues de panels consommateurs.
- SEMRush propose une base de 100M+ prompts
- Ahrefs 250M+ dérivés des PAA.
Reddit, Quora, forums spécialisés, FAQ clients, tickets support : c’est là que le langage naturel des utilisateurs est capturé.
Et c’est aussi là que les IA vont chercher : Reddit apparaît dans environ une réponse IA sur cinq. En croisant ces sources avec vos thématiques, vous obtenez des prompts ancrés dans la réalité.
👉 Dans tous les cas, la base doit vivre : on itère, on ajoute des variantes, on supprime, etc.
3.3. Et ensuite - comment on monitore tout ça ?
Une fois la base de prompts constituée, il faut les envoyer aux LLMs et analyser ce qu’on trouve dans les réponses.
Là encore, plusieurs options s’offrent à nous.
- Outils de monitoring dédiés : ils envoient automatiquement vos prompts aux principaux LLMs, trackent vos mentions dans le temps, et comparent avec les concurrents.
- Modules IA dans les suites SEO existantes : les éditeurs traditionnels (comme SEMRush ou Ahref) ajoutent des briques “AI visibility” à leurs plateformes. → Avantage : intégration plus directe/facile avec vos données/outils SEO.
Pour ceux qui veulent garder la main, il y a une approche plus technique mais qui dispose de beaucoup d’avantages :
- Lister les prompts — commun à n’importe quelle méthodo anyway.
- Interroger les API des LLMs en direct — envoyer les prompts via les API de ChatGPT, Claude, Perplexity, Gemini et collecter les réponses de manière automatisée
- Modéliser — structurer les réponses : extraire les citations, la position, les URLs mentionnées, en analyser le sentiment, etc.
- Visualiser et analyser — construire des dashboards de suivi (Looker Studio, BigQuery, etc.)
- maîtrise totale de la méthodologie et des données
- limite les dépendances à des outils tiers
- disposer facilement de sa donnée pour faire des consolidations & des croisements
L’avantage de cette approche :
→ Notamment avec l’ensemble des données listées dans les deux premières briques.
3.4. Présentation d'un exemple de monitoring
Comme pour les logs, le mieux pour rendre tout cela concret, c'est de regarder un dashboard réel.
Voici donc un exemple de monitoring GEO que nous avons mis en place pour un de nos clients (anonymisé ici sous le nom telefr.fr, opérateur télécom B2C, fake data), avec environ 1 200 prompts trackés sur ChatGPT, Perplexity, Claude et Gemini.
Première chose qu'on regarde : où en est-on globalement ?

Exemples de questions à se poser :
- Share of Voice : quelle est ma part de voix sur mes thématiques stratégiques ? Comment elle évolue dans le temps ?
- Source Visibility vs Brand Visibility : est-ce que les IA parlent de moi (mention de la marque) ou est-ce qu’elles utilisent réellement mon contenu comme source (citation d’URL) ?
- Sentiment : quand l'IA parle de moi, est-ce positif, neutre, négatif ? Est-ce que le message véhiculé est aligné avec mon messaging ?
- Évolution : est-ce que ces métriques progressent ou régressent ? Une baisse de SoV peut signaler un concurrent qui monte ou un changement de modèle qui redistribue les cartes.
Se comparer à ses concurrents sur la même base de prompts.
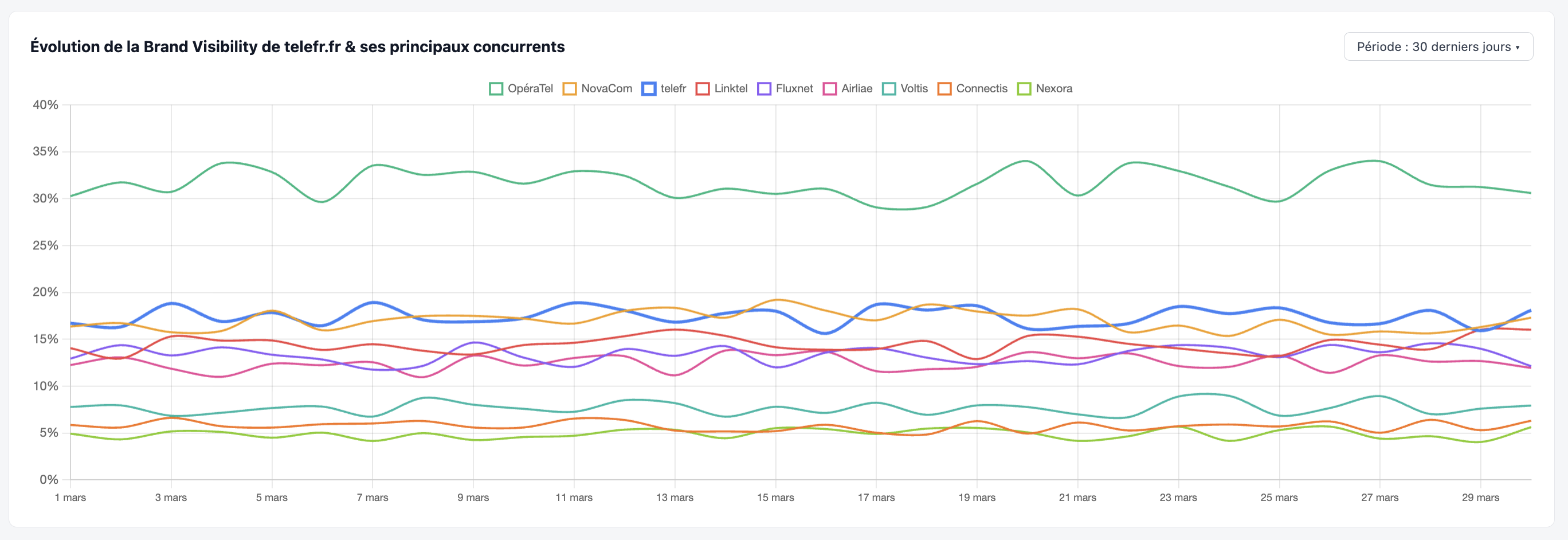
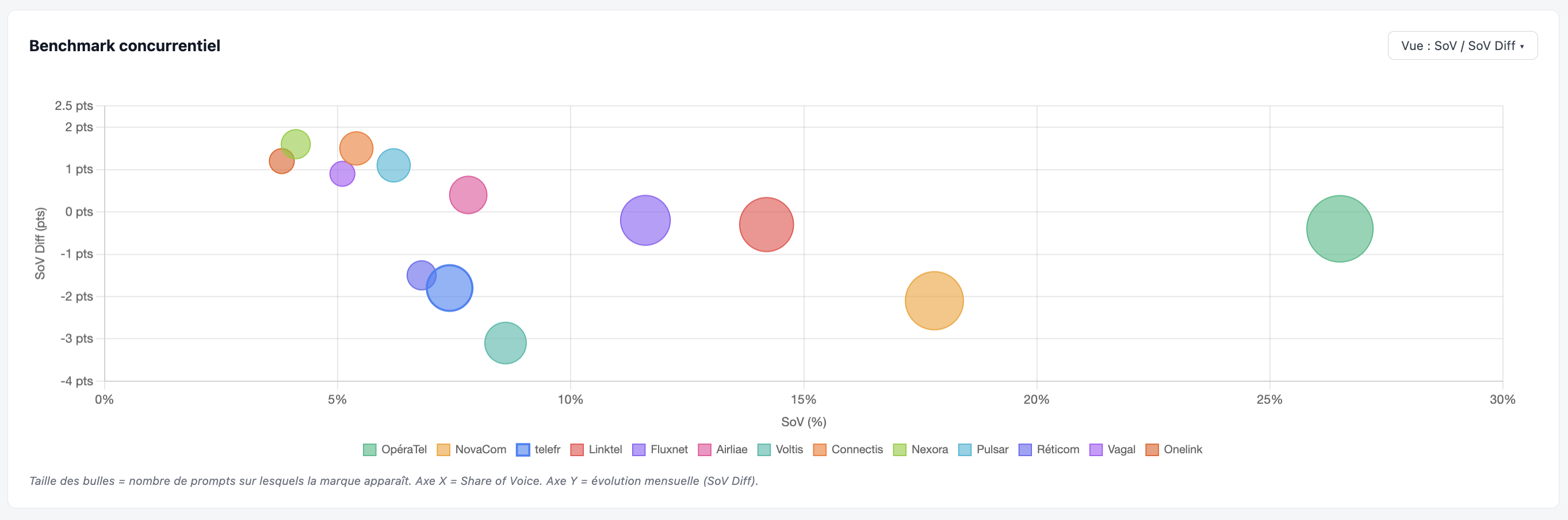
Exemples de constats :
- Quel acteur domine ?
- Comment cette répartition évolue dans le temps ?
- Qui sont les leaders en croissance (cadran haut-droit) — à surveiller de près.
- Qui sont les leaders en perte de vitesse (cadran bas-droit) — opportunités potentielles.
- Les challengers en progression (cadran haut-gauche) — souvent des acteurs qui ont activé un levier GEO efficace.
- Est-ce que cette répartition se tient sur toutes les intentions, toutes les thématiques ?
- Etc.
Un autre angle utile : sur l'ensemble des prompts trackés, quelles sont les sources que les IA mobilisent pour construire leurs réponses ?
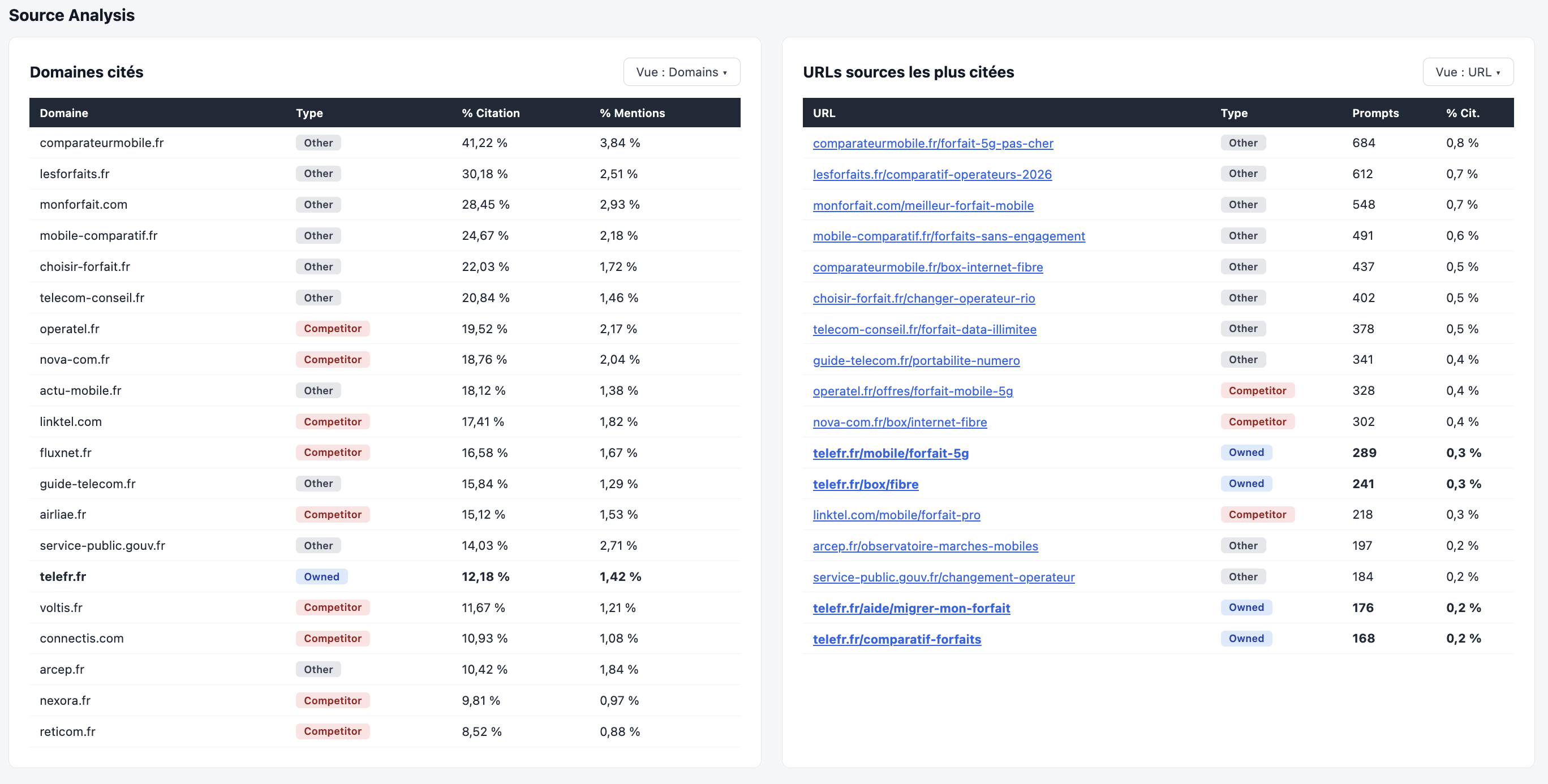
Exemples de constats / analyse :
- Acteur x est énormément cité sur x ou y typologie d’intention.
- Quelles pages sont citées ?
- Existe-t-il des éléments différenciants entre ces pages et les miennes ?
- Simple corrélation avec le positionnement SEO ?
- Ils ne citent jamais mes pages produits ?
- Sont-elles correctement accessible ?
- Va-t-il les visiter ?
- Biais dans ma base de prompts ?
- Est-ce qu’on observe des corrélation similaire entre les citation et l’audience générée par ces URLs ?
- Etc.
C'est ici qu'on rentre vraiment dans le concret.
Pour chaque prompt envoyé, on récupère : le libellé exact, les catégories (intention + thématique), le moteur sollicité, l'URL telefr citée le cas échéant, la présence ou non d'un lien cliquable, la position dans la réponse, et le sentiment associé.
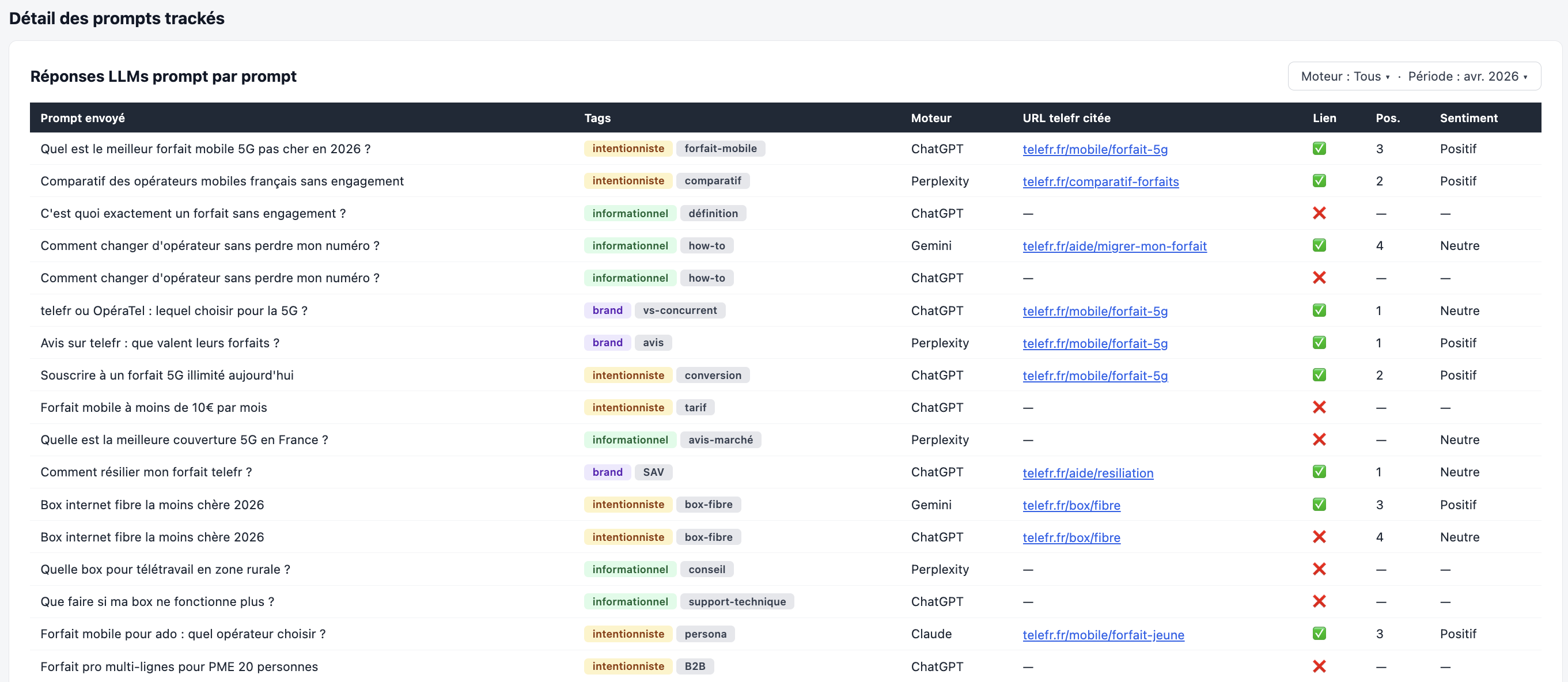
C'est cette granularité qui permet de valider — ou invalider — certaines conjectures formulées en 2.6 :
- Sur les prompts informationnels ("C'est quoi un forfait sans engagement ?", "Comment changer d'opérateur ?")
- Est-ce que l’IA cite ?
- Le fait-elle avec un lien ?
- Sur les prompts intentionnistes ?
- Sur les prompts brand ?
Quand un prompt mérite une analyse fine, on peut descendre au niveau de la réponse elle-même : voir le texte complet généré par le LLM, où la marque est mentionnée, comment elle est positionnée vs les concurrents, et quelles sources ont été mobilisées.
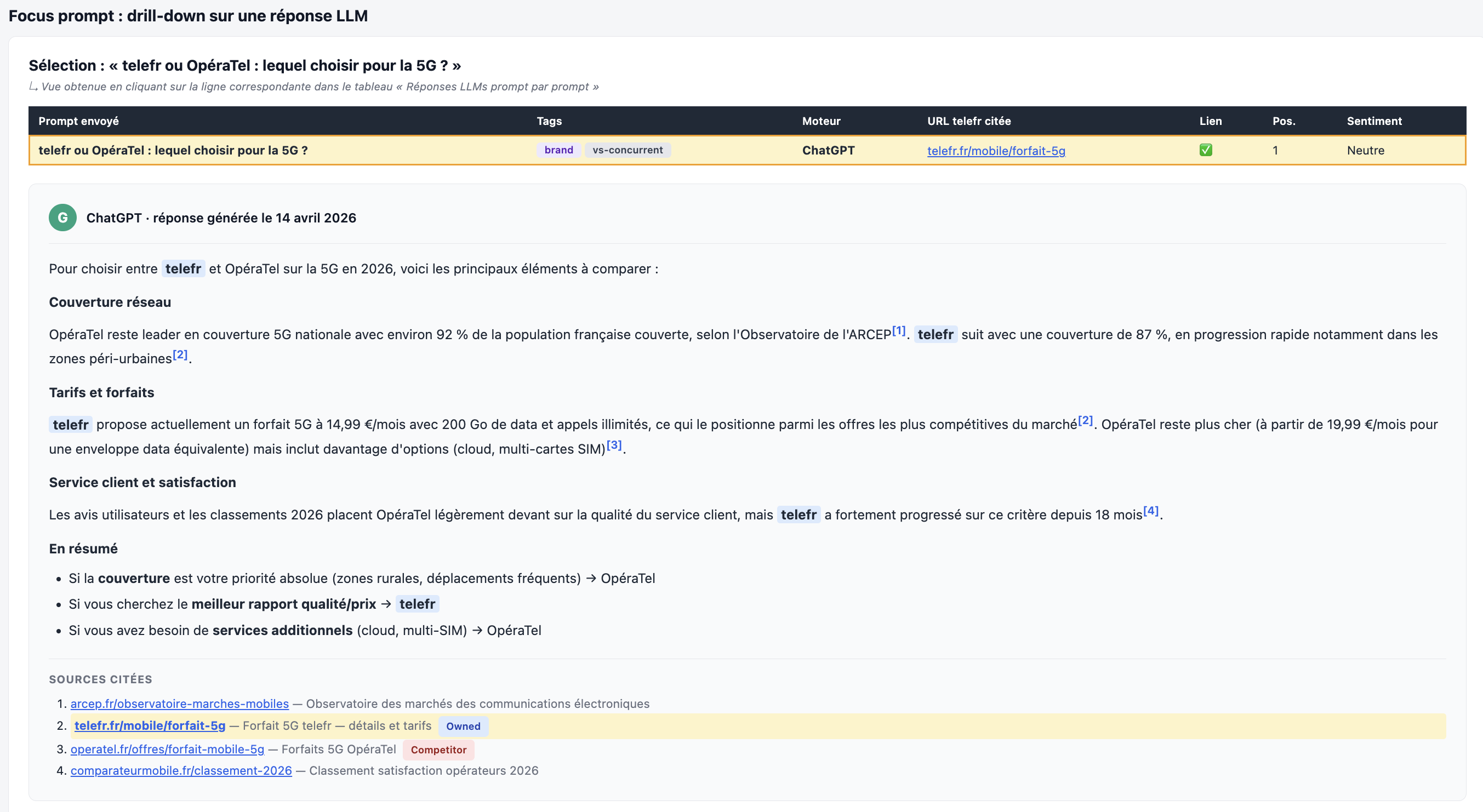
- Qui est mentionné ?
- À quelle position ?
- Mention seule ? Mention + lien ?
- Comprendre quelles pages servent de source — et donc lesquelles optimiser en priorité
- Mentionne-t-il aussi la concurrence ?
- Quel est son sentiment & ses arguments en ma faveur ?
- Identifier les arguments concurrents que les IA reprennent contre vous
- Le ton est neutre/légèrement positif sur les tarifs, neutre sur la couverture
- Est-ce pertinent ?
- etc.
Ce niveau de détail est également précieux pour :
Vérifier que la narration IA est aligné avec ce que vous voulez véhiculer (l'IA reformule, et peut altérer le sens)
Conclusion — Croiser les 3 briques pour avoir une lecture complète
C’est en combinant ces trois sources de données qu’on commence à avoir une vision réellement exploitable.
Aucune de ces briques ne suffit prise individuellement. C'est leur croisement qui fait la différence : comprendre pourquoi une page massivement crawlée ne génère aucune citation, pourquoi une citation ne se traduit pas en trafic, ou sur quelles thématiques on est absent face aux concurrents.
J’espère que c’est plus clair pour vous maintenant que ça ne l’était au début.
Dans le prochain article de ce triptyque, nous aborderons un sujet très important : Qu’est ce que je fais avec toute cette data ? Comment j’optimise mon site & mes contenus ? Quelles sont les best practices (pour l’instant), les écueils ?
En attendant, si vous avez des questions concernant ces sujets, n’hésitez pas à me contacter directement sur LinkedIn ou sur mon mail pro : xavier.s@unnest.co
Rendez-vous au prochain épisode !