
GAP_FILL qu’est ce que c’est ?
GAP_FILL est une fonction de séries temporelles disponible en preview sur BigQuery. Elle sert à “combler les trous” pour avoir une série de temps continue.C'est super utile pour modéliser des données par jour, par exemple, pour éviter les trous lorsqu'aucune nouvelle donnée n'a été enregistrée pour un jour.
Pour illustrer cette idée, on peut envisager une métrique qui indique le nombre de profils publiés sur une plateforme. Le problème est qu'il n'y a pas de nouvelles publications tous les jours. Du coup, prendre simplement le jour de publication comme élément de date et supposer que si la date est supérieure à la publication, le profil compte comme publié, nous créerait des trous pour les dates où il n'y a pas eu de publication. Une solution pourrait être de créer un calendrier avec tous les jours en utilisant
GENERATE_DATE_ARRAY et en y joignant notre table avec la publication du profil. Ça fonctionne, mais ça nécessite d'indiquer une date de fin, donc il y a de la maintenance à prévoir et surtout, ça ajoute de la complexité inutilement.C’est pour ce genre de use case que
GAP_FILL est vraiment utile !Comment l’utiliser
Maintenant qu’on sait à quoi ça sert, on peut regarder comment ça s’utilise !
Pour que ça soit plus parlant, j’ai créé un faux dataset que j’ai appelé
fake_data_cleaned_gap_fill (en utilisant Faker : mode d’emploi dans cet article 👀) qui comporte ces colonnes :measured_at
name
country
emails_sent
pets
is_employed
sneak peek
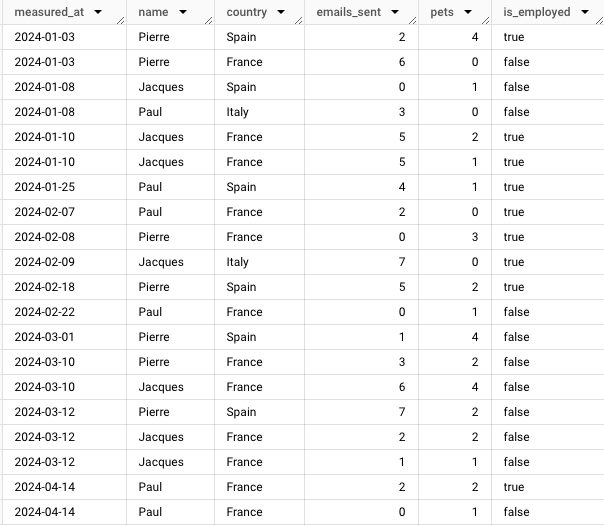
Pour que la fonction
GAP_FILL fonctionne, il faut :- Un champ date (ou datetime, timestamp). Dans mon exemple c’est
measured_at.
- En option, on peut avoir des dimensions pour partitioner tout ça (j’ai ajouté
nameetcountry)
- En option, des métriques ou dimensions à extrapoler aux dates qui n’existent pas, et ici on en utilise trois:
emails_sent,pets,is_employed.
GAP_FILL doit référencer une table et pas un CTE donc il n’est pas possible d’en utiliser en argument (par contre la fonction peut bien sûr être utilisée elle-même à l’intérieur d’un CTE !)Comme indiqué dans la documentation google, il y a plusieurs arguments qu’on peut spécifier dans la fonction
sqlGAP_FILL ( TABLE time_series_table, time_series_column, bucket_width, [, partitioning_columns=>value] [, value_columns=>value ] [, origin=>value] [, ignore_null_values=>value] )
time_series_table
Ici on a juste à notifier quelle est la table qu’on veut utiliser pour être la source de notre
GAP_FILL. Il y a deux possibilités : sqlTABLE `fake_data_cleaned_gap_fill`
sql(SELECT * FROM `fake_data_cleaned_gap_fill`)
time_series_column
Là on parle de notre champ de date, et pour moi c’est
measured_atsqlts_column => 'measured_at'
bucket_width
Pour spécifier l’interval de temps entre chaque bucket. Là encore ça peut être une date, datetime, ou timestamp. On peut choisir par exemple toutes les 5 minutes. Ici moi j’ai choisi tous les jours.
sqlbucket_width => INTERVAL 1 DAY
partitioning_columns(optionnel)
Il peut arriver qu’il y ai plusieurs critères sur lesquels on doive partitioner notre table finale. Ici j’aurais besoin d’avoir une table par jour, par nom, et par pays.
sqlpartitioning_columns => ['name', 'country']
value_columns(optionnel)null: si la ligne n’existait pas, la valeur sera nulllinear: si la ligne n’existait pas, une valeur est appliquée suivant la fonction linéaire (marche seulement pour les métriques, et pas les dimensions)locf(last observation carried forward): si la ligne n’existait pas, la dernière valeur qui existait est appliquée- Pour les
emails_sent, on veut qu’ils s’appliquent qu’au jour où ils ont été envoyé - Pour les
pets, on veut répercuter le nombre d’animaux pour les jours où il n’y a pas de données - Pour le booléen
is_employed, on part du principe que tant que le booléen ne change pas d’état, il faut reprendre la valeur précédente
Lorsqu’on choisit d’utiliser des métriques ou dimensions à extrapoler, on doit choisir comment remplir les lignes qui n’existent pas. Il y a trois choix :
Dans mon exemple,
sqlvalue_columns => [ ('emails_sent','null'), ('pets','locf'), ('is_employed','locf') ]
origin(optionnel)
Cet argument sert à spécifier le moment à partir duquel créer les buckets (date, datetime, ou timestamp, mais doit être du même type que la
time_series_column). Comme par défaut la valeur de time_series_column est utilisée et que ça correspond à ce qu’on recherche, je ne la spécifie pas.ignore_null_values(optionnel)
C’est un booléen qui indique si la fonction doit ignorer les valeurs nulles dans la table qu’on lui a donné. Sa valeur par défaut est à vrai, donc on ne va pas le spécifier ici non plus.
Au final, la fonction va ressembler à ça :
sqlSELECT * FROM GAP_FILL( TABLE `fake_data_cleaned_gap_fill`, ts_column => 'measured_at', bucket_width => INTERVAL 1 DAY, partitioning_columns => ['name', 'country'], value_columns => [ ('emails_sent','null'), ('pets','locf'), ('is_employed','locf') ] ) ORDER BY measured_at
output
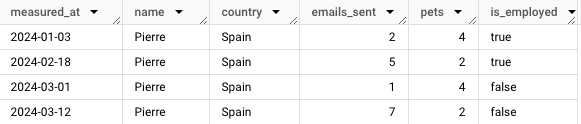
Mes données allaient du 2024-01-03 à 2024-04-14 et avant si on recherchait ce qu’on avait pour Pierre en Espagne on se retrouvait avec ça ⬇️
Après le
GAP_FILL, si on fait la même requête on obtient ça ⬇️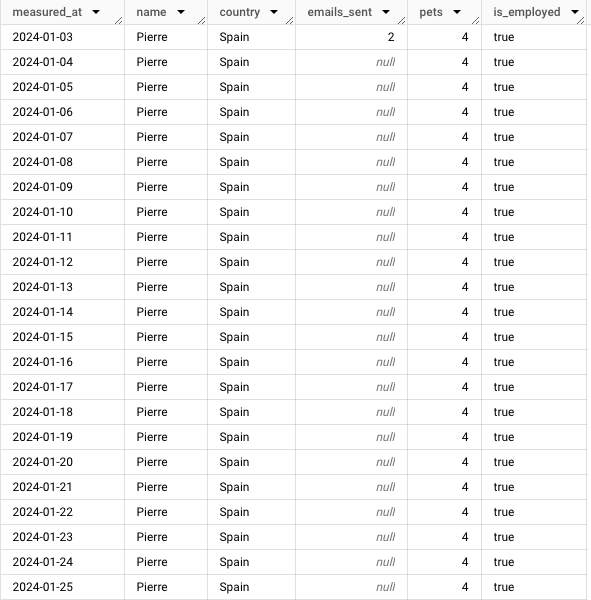
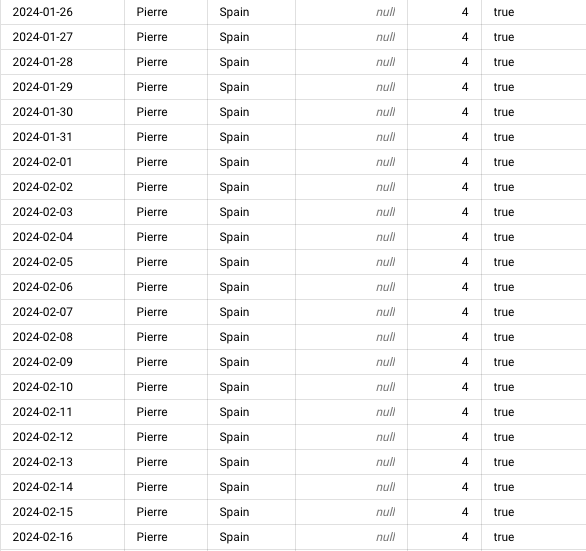
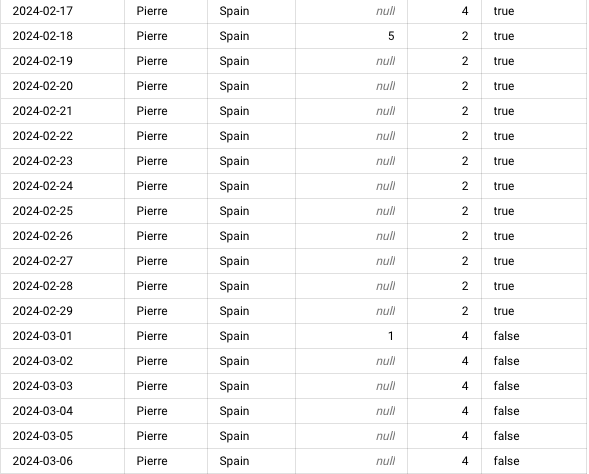
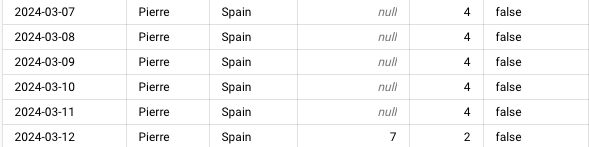
Maintenant tout est prêt pour analyser données ! 🚀
Resources
Time series functions | BigQuery | Google Cloud
GoogleSQL for BigQuery supports the following time series functions.
https://cloud.google.com/bigquery/docs/reference/standard-sql/time-series-functions#gap_fill
L’auteure : Eva Despesse

BI Engineer chez unnest, Eva est en charge des sujets de modélisation de la donnée et du dashboarding, notamment sur Tableau et Power BI.
Ayant commencé dans une start-up, j’ai pu toucher aux flux de données de bout en bout. J’apprécie particulièrement faire les modélisations en bout de chaine avec le dashboarding pour suivre toute la chaine de transformation de données en information.
✉️ Me contacter : eva.despesse@unnest.co