
Dans la version 2024.2 (sortie en juin 2024) de Tableau Desktop est apparue une nouveauté : les
relations portant sur plusieurs faits (ou comme je vais les appeler par la suite, les multi-facts relationships). Dans cet article je vous présente les différentes manières de combiner des sources de données directement dans Tableau 👩🏫, et je vous montre un exemple pratique de comment on peut se servir des multi-facts relationships 🔍.
👩🏫 Les liaisons de sources dans Tableau
Dans Tableau, il y a plusieurs manières de lier des sources de données :
- Les jointures & unions
- Les relations
- Les combinaisons (ou blending 🎩),
- Et depuis juin 2024, les multi-facts relationships
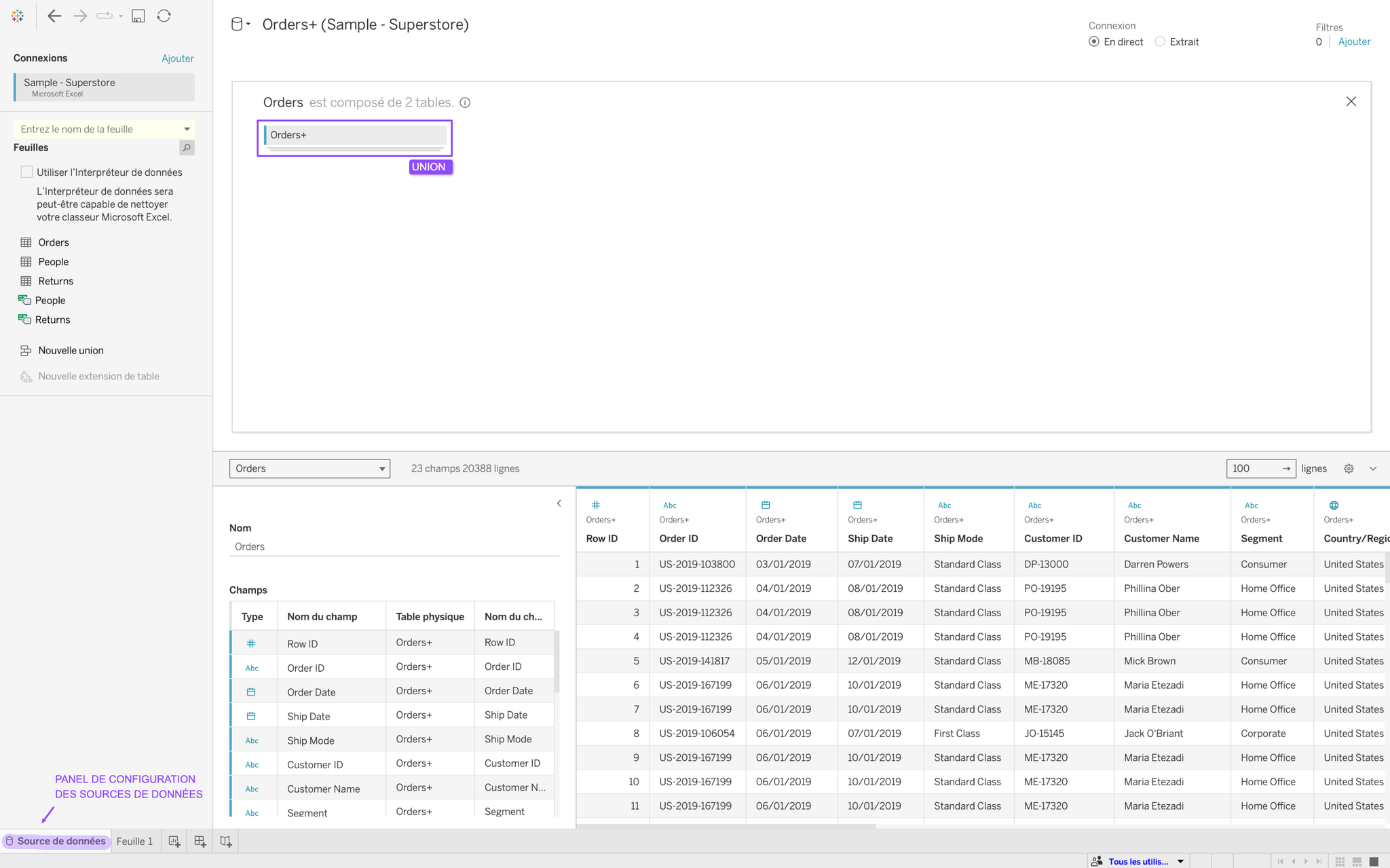
1. Jointures & Unions
C’est exactement pareil que
JOIN et UNION en SQL. Pour les configurer, il faut avoir mis une première source de données dans le panel de configuration des sources de données et de double cliquer dessus. C’est ici qu’on peut réaliser des jointures (en amenant la nouvelle table à droite de la table présente) et des unions (en amenant la nouvelle table juste en dessous de la table présente). Ensuite, c’est possible de faire des relations additionnelles sur cette table.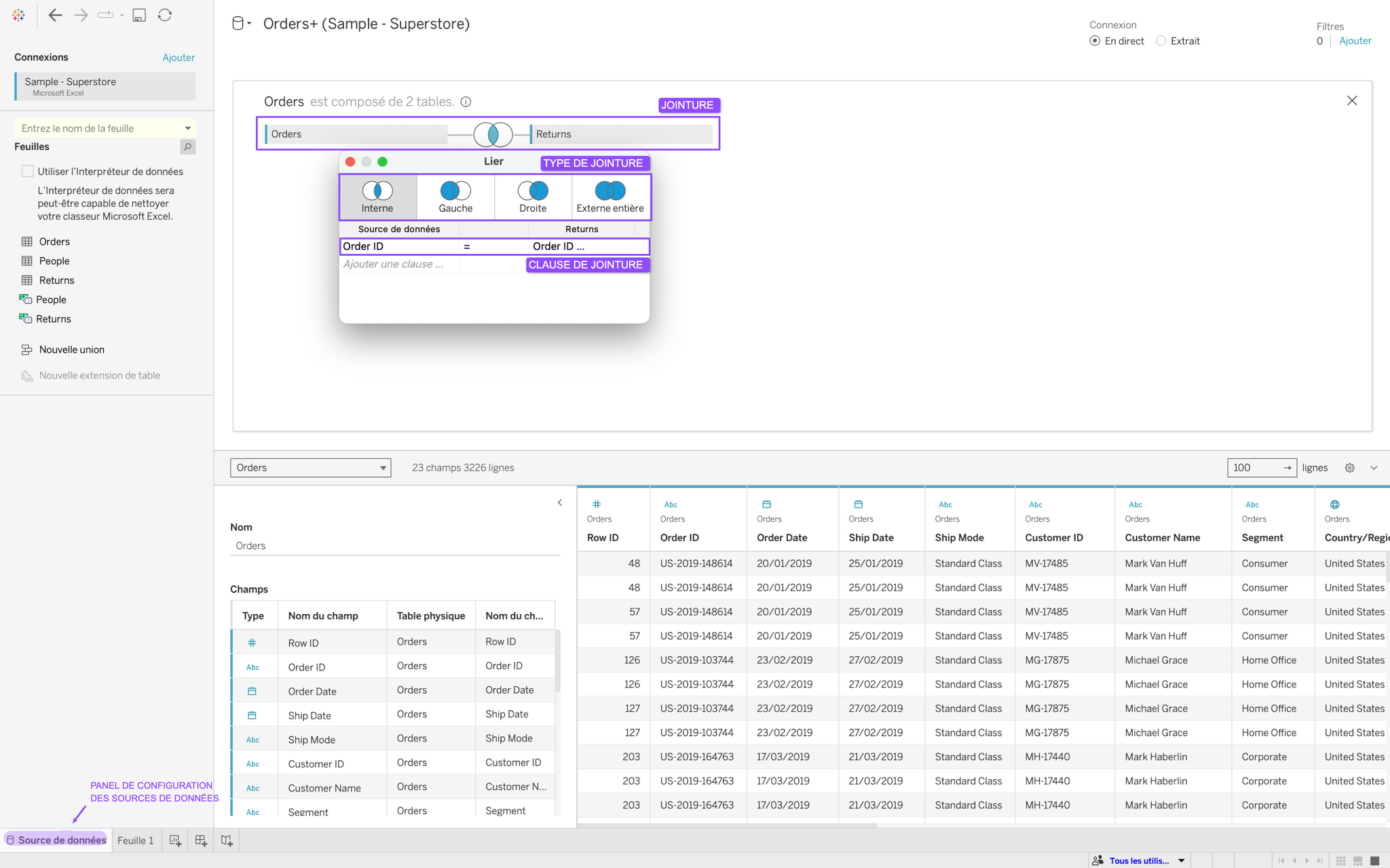
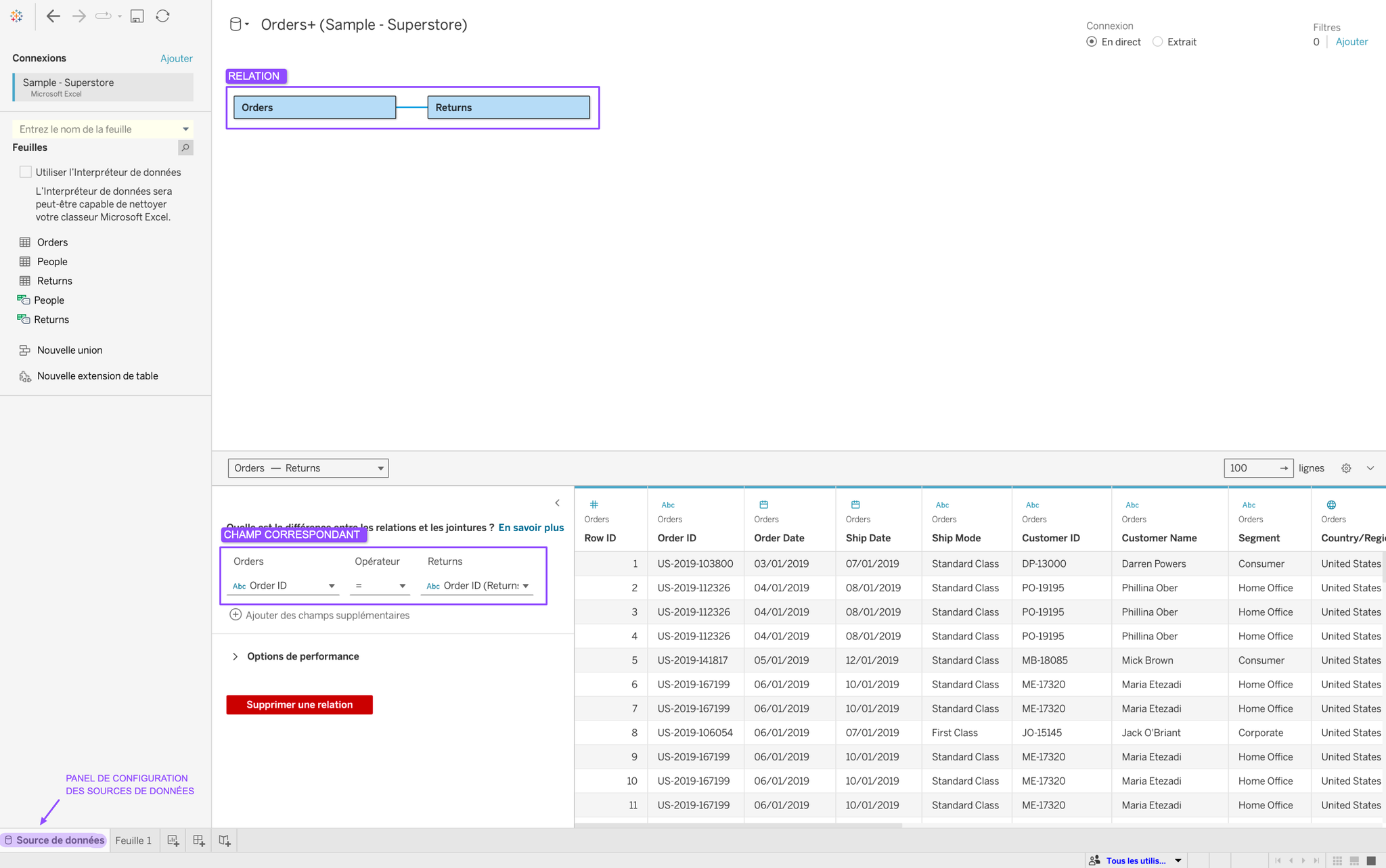
2. Relations
C’est une manière dynamique de lier plusieurs sources de données. Il n’y a pas de jointure à proprement parler, c’est Tableau qui, sous le capot, utilise la bonne table et la bonne granularité lors de la création de visuels en fonction des champs amenés dans la feuille.
Il faut sélectionner les champs qui correspondent dans les tables qui composent la relation.
3. Combinaisons
Ici, les source de données ne sont pas directement reliées. Du coup, le niveau de détail peut être différent. On a deux sources de données séparées qui sont seulement visualisées ensemble dans les feuilles de calcul où on les appelle. La source de données principale de la feuille à une coche verte et la secondaire, une coche orange. Le ou les champ(s) utilisé(s) pour lier les deux sources a/ont le symbole d’une chaine (🔗) dans le panel de gauche. Il faut donc s’assurer qu’il y a au moins un champ commun entre les deux sources.
Cette façon de lier des données n’est pas très utilisée car elle n’est pas du tout flexible (la relation se fait tout à fait en fin de chaine) et il y a des limitations par rapport aux agrégations qui rend les combinaisons inutilisables par moment.
4. Multi-facts relationships
Déjà, on peut répondre à la question : Pourquoi ce nouveau type de liaison a-t-il été créé ?
Parce que le relations, c’est bien, mais ça a des limitations. On ne peut pas lier des tables à plusieurs tables de base (ps : celles sur la gauche du diagramme).
Avec les multi-facts relationships, on peut avoir plusieurs tables de base qu’on peut connecter avec les autres tables. Et surtout, on peut lier des sources qui ont des dimensions en commun (par exemple, la date) mais qui ne sont cependant pas reliées entre elles. Par exemple, Tableau a pu utiliser l’exemple des ventes de crèmes glacées et la météo (là, les champs communs sont la localisation et la date).
Pour pouvoir créer une visualisation qui mélange les données des tables de base, il faut que la dimension commune que l’on veut utiliser vienne d’une table partagée.
Dans la section juste en dessous, je mets ce concept en pratique !
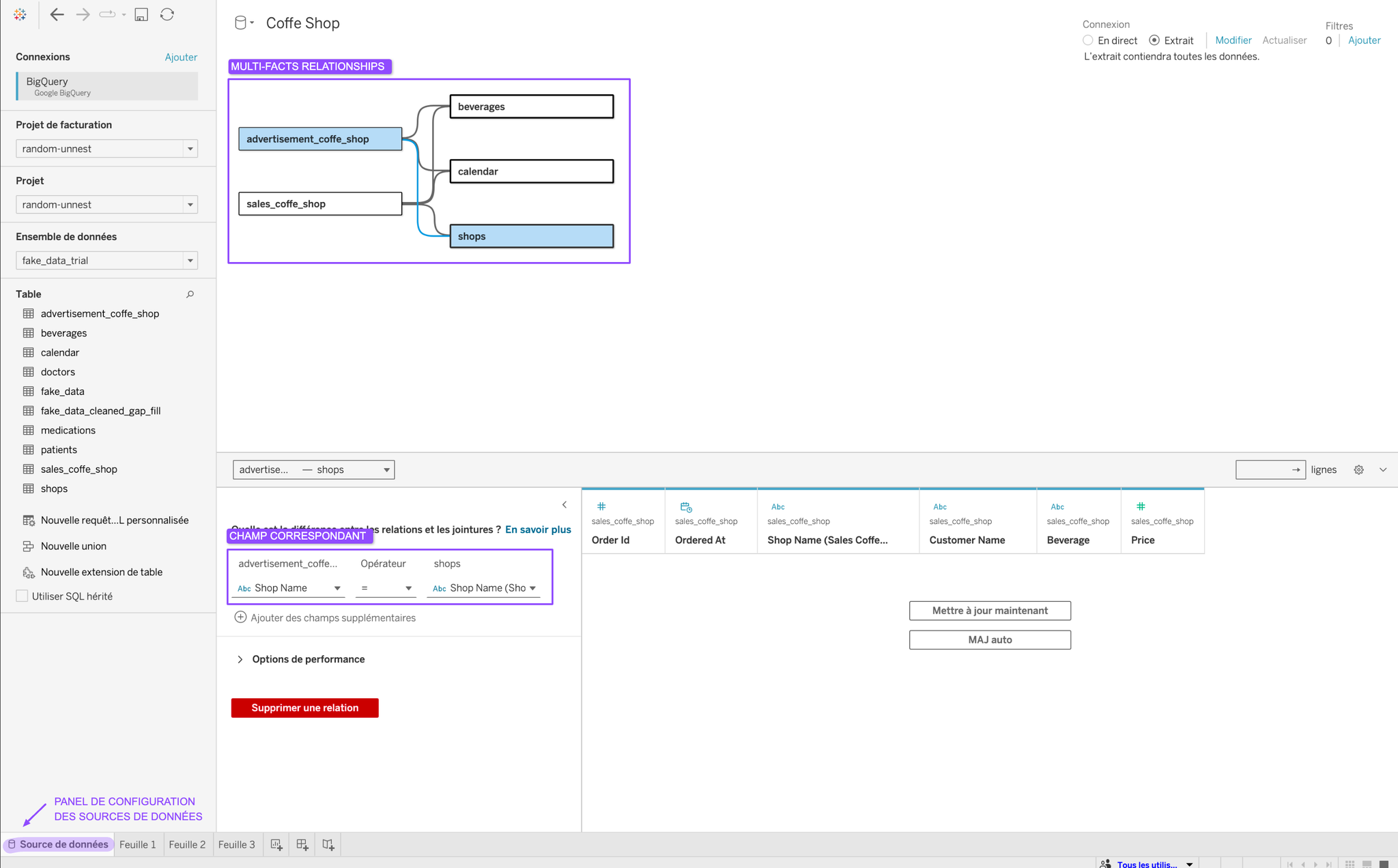
🔍 Les multi-facts relationships, en pratique
Pour mieux comprendre comment ça fonctionne, on va utiliser les multi-facts relationships dans un exemple concret.
J’utilise deux sources de données principales qui ne sont pas liées entre elles, mais qui partagent des dimensions :
sales_coffee_shop: Les ventes d’un café
Colonnes
advertisement_coffee_shop: Les données des campagnes média
Colonnes
⬆️ Ce sont mes deux tables de base.
Pour les relier, j’utilise trois tables partagées :
beverages: contenant le nom des boissons et leur id
calendar: contenant des dates
shops: contenant le nom des cafés et leur id
Ces trois dimensions sont partagées dans mes deux tables de base.
Pour avoir ces données, j’ai généré toutes les tables avec de fausses données dans BigQuery en utilisant la library python Faker. Si vous voulez en savoir plus sur comment j’ai fait, voici l’article que j’ai rédigé précédemment à ce sujet ➡️ ‣
On commence par créer une relation comme on a l’habitude dans tableau avec
advertisement_coffee_shop (on aurait tout aussi bien pu commencer avec sales_coffee_shop). Ensuite, on ajoute la deuxième table de base (sales_coffee_shop) et on relit celle-ci avec les tables partagées !Maintenant, il y a plus qu’à utiliser notre source de données nouvellement créée ! Pour cela, on peut facilement prendre les champs des tables partagées et ajouter les champs des tables de bases pour construire des graphiques qui mélangent les informations.
Pour illustrer tout ça, je vais faire un graphique qui présente le nombre de visites liées aux campagnes avec le montant des ventes pour voir s’il y a une relation entre les deux variables (ps : comme ce sont des fausses données, les chiffres n’ont pas de logique).
Le résultat est disponible sur Tableau Public si vous souhaitez télécharger le dashboard (➡️ ‣) et naviguer dedans.
💬 Conclusion
Et voilà ! Maintenant vous avez toutes les clés en main pour maitriser la liaison des sources de données dans Tableau 🔑.
Selon moi, les multi-facts relationships c’est bien pratique pour des analyses ad-hoc/rapides, mais ça ne remplace pas la création d’un modèle solide en amont lorsque l’on souhaite pérenniser des analyses.
Ce que j’en tire 🙋♀️ On peut se servir des multi-facts relationships pour des phases exploratoires et pour mieux comprendre les données que l’on veut exploiter, mais une fois ce travaille fait, on peut passer à la modélisation pour créer un modèle qui contient une logique réutilisable par tous et indépendante d’un tableau de bord singulier.
🔗 Resources
Pour aller plus loin ⬇️
L’auteure : Eva Despesse

BI Engineer chez UnNest, Eva est en charge des sujets de modélisation de la donnée et du dashboarding, notamment sur Tableau et Power BI.
Ayant commencé dans une start-up, j’ai pu toucher aux flux de données de bout en bout. J’apprécie particulièrement faire les modélisations en bout de chaine avec le dashboarding pour suivre toute la chaine de transformation de données en information.
✉️ Me contacter : eva.despesse@unnest.co