
Prémices
Fin novembre, afin de comparer les performances de tracking server-side avec celles client-side, notre équipe tracking a eu l’idée de suivre cet article de Simo Ahava (lien ci-dessous). Le principe consiste à demander à GTM d’envoyer tous les hits vers BigQuery via une Cloud Function.
How To Build A Google Tag Manager Monitor
How to build a monitor system for Google Tag Manager, where the rate and success of tags firing on your website is logged into BigQuery for analysis and anomaly detection.
https://www.simoahava.com/analytics/google-tag-manager-monitor/#313-technology-of-choice-cloud-functions
Lors de l’implémentation, j’avais répondu à quelques questions vis-à-vis du déploiement des Cloud Functions, puis cela avait pu être rapidement mis en production.
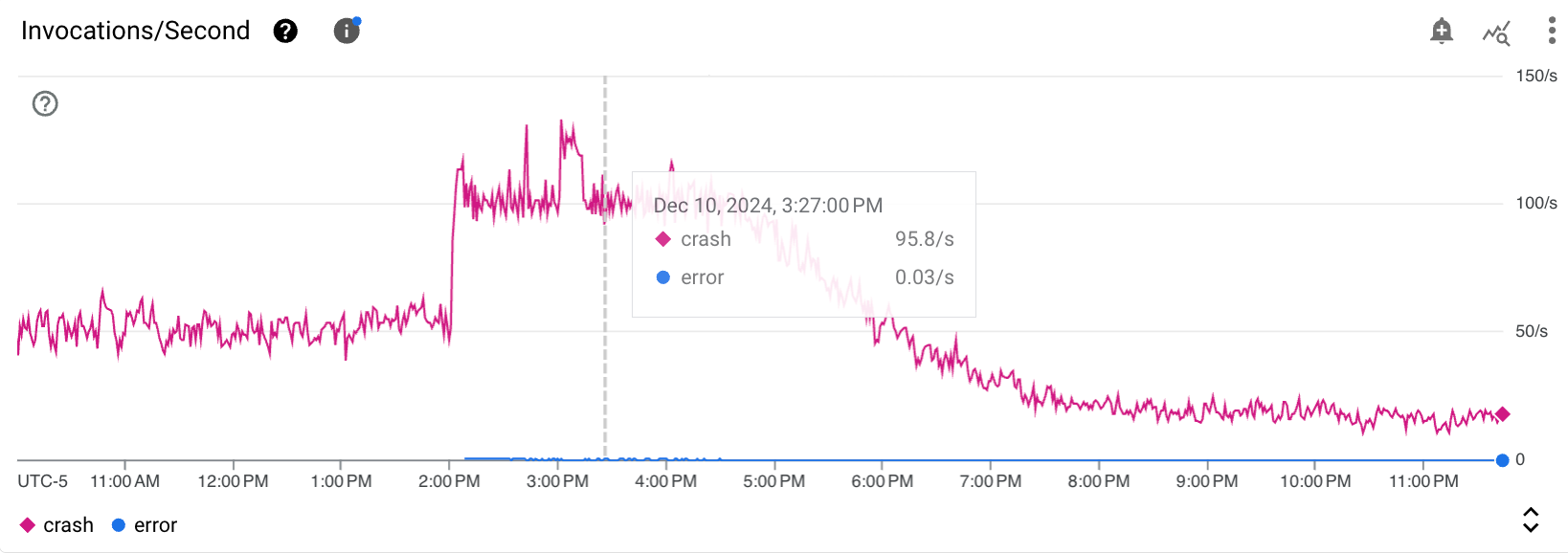
S’en est suivi une dizaine de jours sans nouvelles, mais lors d’un check routinier FinOps de notre organisation GCP, je remarque un pic de coût inhabituel et rapidement, le service Cloud Run Functions sur le projet en question est identifié comme la source de cette anomalie :
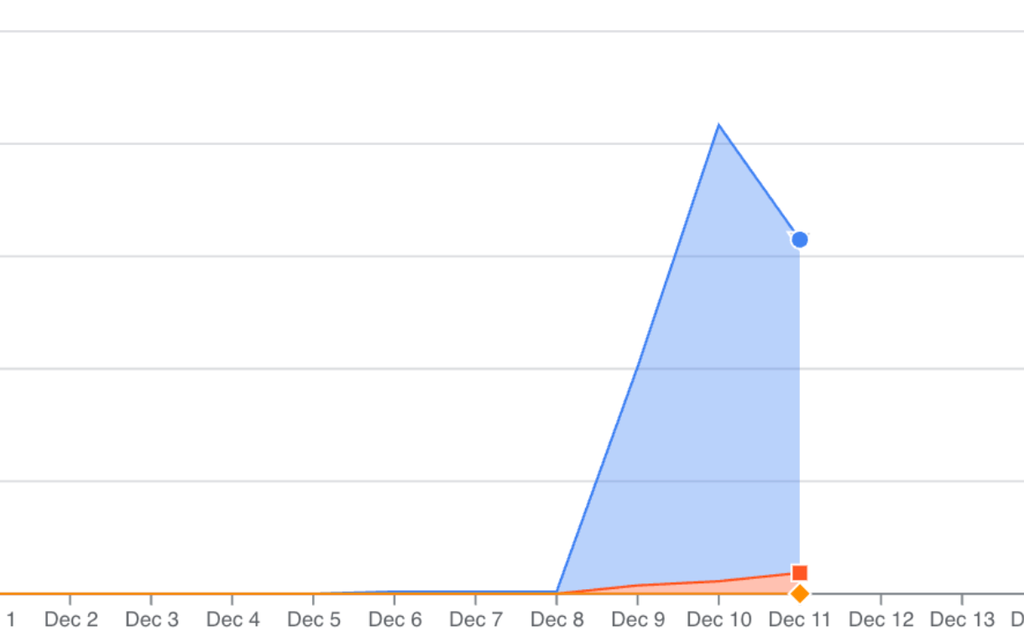
Bien que nous ayons très souvent recourt à ce service à différentes fins dans nos projets, son coût avait toujours été négligeable.
Mais le 9 décembre, l’outil implémenté par l’équipe tracking avait été déployé sur un client ayant un volume de traffic significativement plus important. Faisant subitement passer la Cloud Function d’une utilisation sporadique, à être sollicitée plusieurs dizaines de fois par secondes, jusqu’à même atteindre en période de pointe la limite de 100 instances que nous avions configuré.
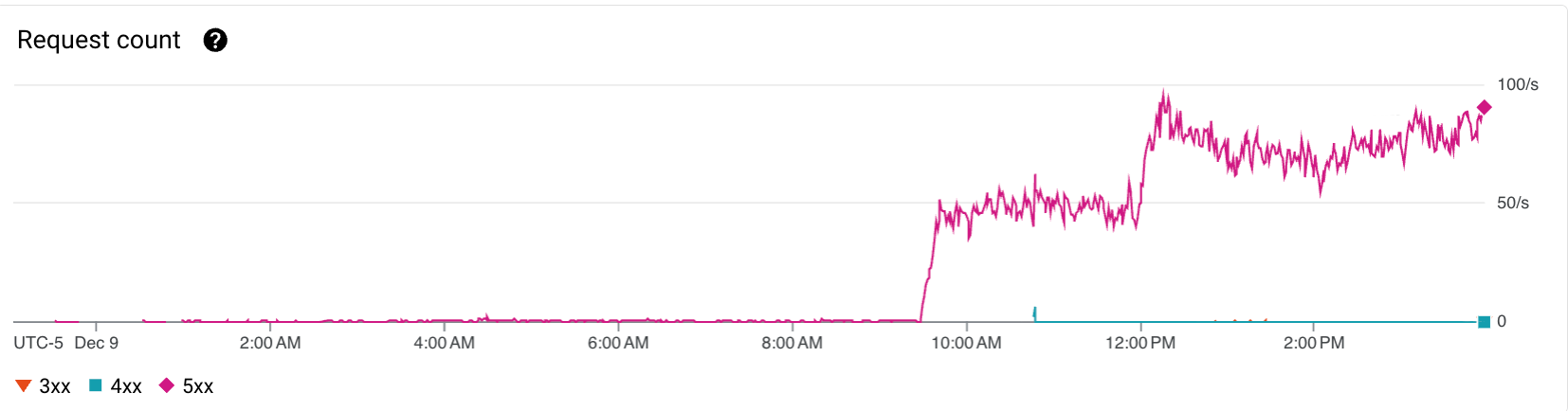
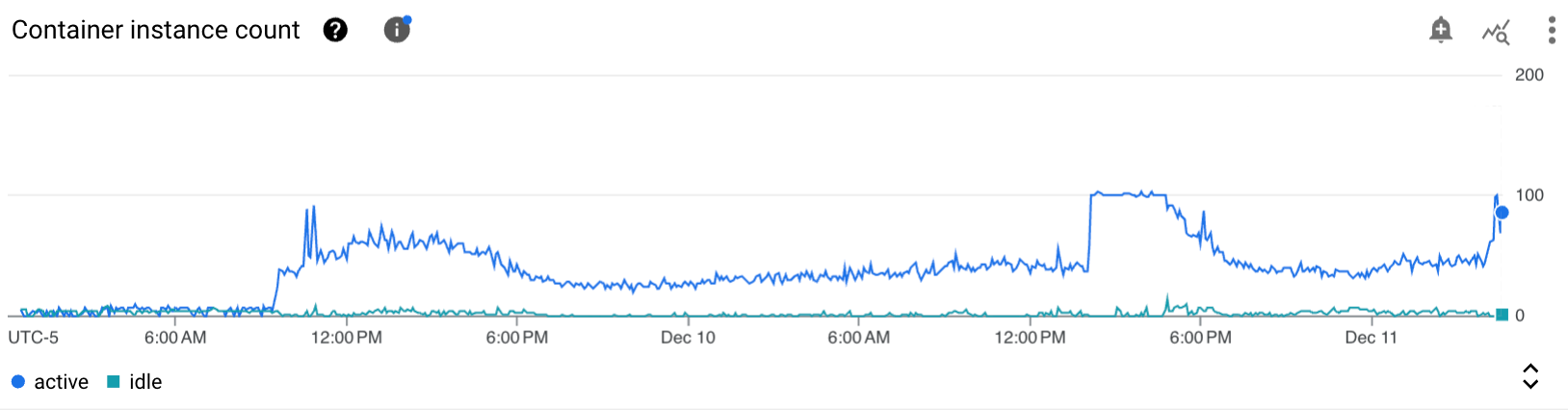
Avec une projection de 200 millions de requêtes par mois, il était évident qu’une réflexion sur des optimisations s’imposait, surtout si cela avait vocation à être déployé sur d’autres clients ayant un traffic important.
Solutions
Vu que l’outil était toujours au stade d’essai, une potentielle interruption de service n’était pas critique, nous avions donc la liberté de tester plusieurs modifications sans craindre que cela ne pose problème. Voici les changements faits lors de cette première phase d’optimisation “quick wins”, dans le but de faire rapidement des économies conséquentes avec de simples actions.
Batching côté GTM (Sans succès)
Dans un premier temps, nous avons exploré l’option où GTM serait configuré pour envoyer les requêtes par batch, c’est-à-dire de les regrouper, au lieu de les envoyer une par une.
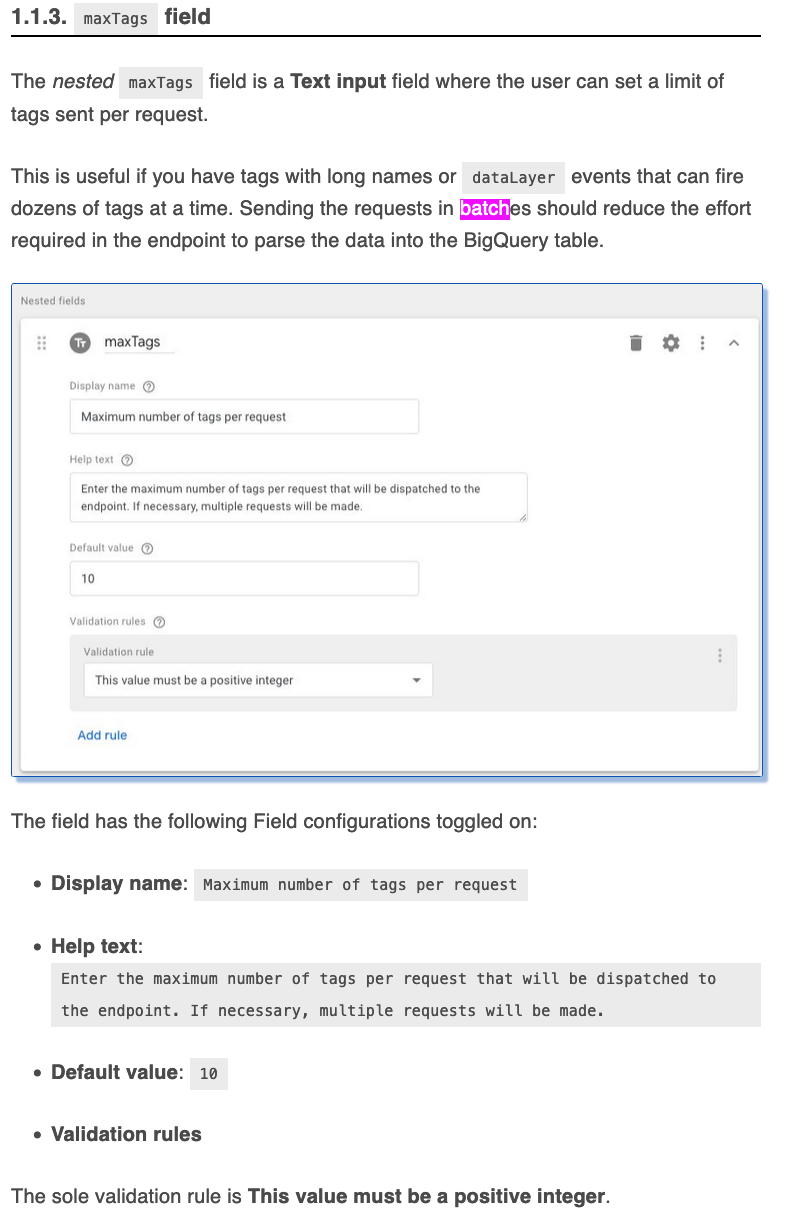
Cette option avait été évoqué dans l’article de Simo Ahava, avec les instructions pour faire en sorte que GTM fonctionne par batch.
Cependant cela n’a pas eu l’effet escompté :

Nous avons poussé en production deux tentatives, la première en passant d’un mode non-batché à un groupe de 20, puis en passant de 20 à 50 mais cela n’a eu aucun impact notable sur le nombre de requêtes par seconde reçue par la Cloud Function.
Cela a peut-être mal été configuré de notre côté, mais après relecture, en étant plus attentif, il semblerait que ce mode permet surtout de grouper des requêtes longues ou lorsque plusieurs tags sont déclenchés pour un event donné. Par contre cela ne groupe pas des events différents, ce qui après réflexion est plutôt logique compte tenu de fait qu’en client-side, les hits d’utilisateurs différents ne vont pas être regroupés.
Ajustement du code Python
L’article datant de 2019 et GCP ayant bien évolué depuis, certaines adaptations étaient nécessaires, par exemple le runtime Python 3.7 n’est plus maintenu et le package
google-cloud-bigquery==1.5.1 n’est plus tout à fait d’actualité.Par ailleurs le code fourni dans l’article est le suivant :
pythonfrom google.cloud import bigquery import datetime import logging PROJECT='me-gtm-monitoring' # Update to match your project name DATASET='gtm_monitoring' # Update to match your dataset name TABLE='raw_data' # Update to match your table name def stream_bq(uri): client = bigquery.Client() table_ref = client.dataset(DATASET).table(TABLE) table = client.get_table(table_ref) # Stream the URI of the request errors = client.insert_rows(table, [{'URI':uri, 'timestamp': datetime.datetime.now()}]) if errors: logging.error(errors) def gtm_monitor(request): if request.url: stream_bq(request.url)
Or les fonctions définies n’ont pas de “return” - ce qui fait que même si la donnée est correctement envoyée vers BigQuery, chaque fonction se termine par un crash donc aucune invocation ne se termine proprement !
Cela n’est clairement pas idéal et fait parti des aspect qui semble critique de corriger. Notre ami Gemini est d’accord avec ce constat, et suggère en plus d’utiliser insert_rows_json au lieu de insert_rows qui serait plus efficace. Voici donc la version mise à jour qui implémente ces modifications :
pythonfrom google.cloud import bigquery import datetime import logging from flask import Request # Add type hints for better readability PROJECT = 'me-gtm-monitoring' # Update to match your project name DATASET = 'src_gtm' # Update to match your dataset name TABLE = 'raw_data' # Update to match your table name # Initialize the BigQuery client globally to avoid re-initialization on each request client = bigquery.Client() def stream_bq(uri: str) -> None: """ Streams a single URI to BigQuery. Args: uri (str): The URI to be logged in BigQuery. """ try: table_ref = client.dataset(DATASET).table(TABLE) #table = client.get_table(table_ref) # Cache this to avoid unnecessary lookups # Insert the URI and current timestamp into the table rows_to_insert = [{ 'URI': uri, 'timestamp': datetime.datetime.utcnow().isoformat() # Use UTC for consistency }] errors = client.insert_rows_json(table_ref, rows_to_insert) # Use insert_rows_json instead of insert_rows if errors: # Log specific errors for better debugging logging.error("Errors while inserting rows into BigQuery: %s", errors) except Exception as e: logging.exception("An unexpected error occurred while streaming to BigQuery: %s", e) def gtm_monitor(request: Request) -> str: """ Cloud Function entry point. Processes an incoming request and streams the request URL to BigQuery. Args: request (flask.Request): The incoming request object. Returns: str: Response message indicating success or failure. """ try: if request and request.url: # Ensure request object and URL are valid logging.info("Received request with URL: %s", request.url) stream_bq(request.url) return 'Request URL has been successfully streamed to BigQuery.' else: logging.warning("No URL found in the request.") return 'No URL found in the request.' except Exception as e: logging.exception("An unexpected error occurred in gtm_monitor: %s", e) return 'An error occurred while processing the request.'
Les erreurs disparaissent aussitôt, le temps d’exécution, la latence, le nombre de containers baissent de manière visible, ce qui est très positif, ne serait-ce que pour éviter de spammer d’erreurs le système de logging des milliers de fois par minutes.
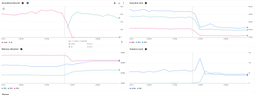
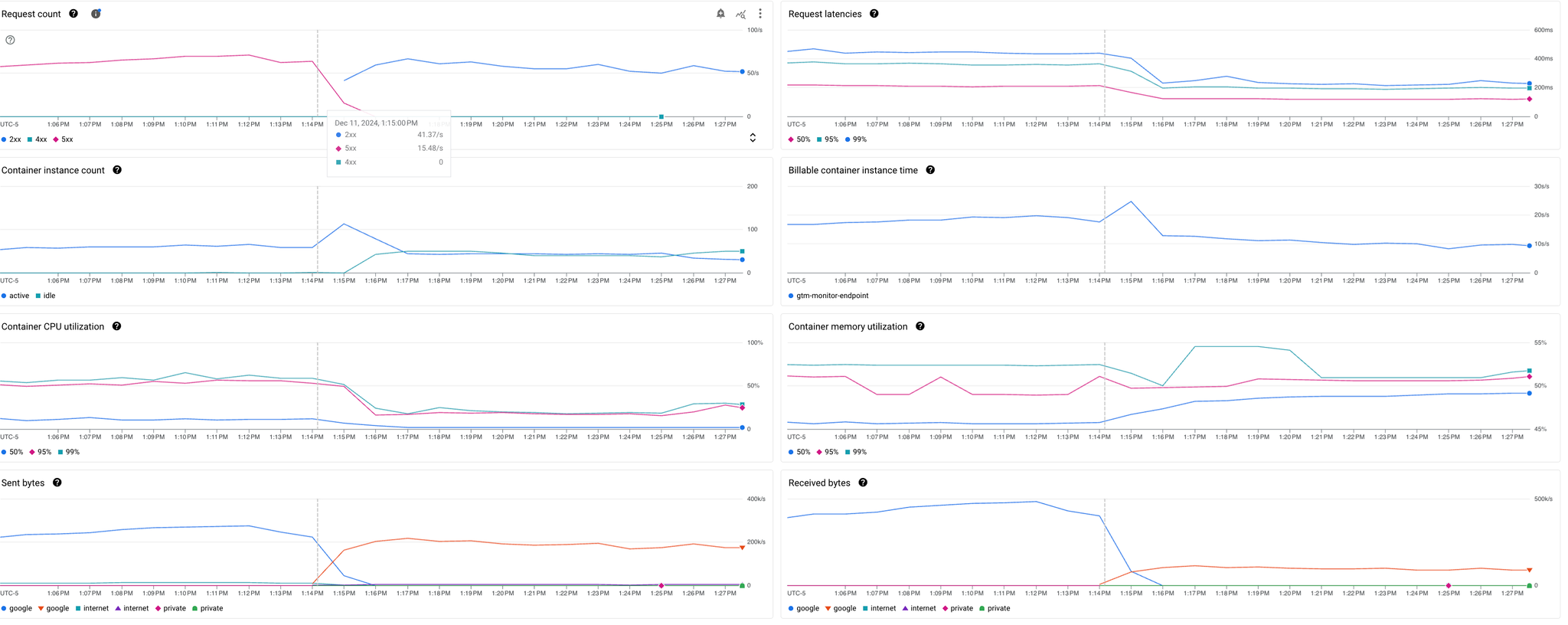
Je n’ai pas fait de test pour vérifier qui de l’utilisation de insert_rows_json ou l’arrêt des crash contribue le plus à ces gains de performances mais dans tous les cas l’impact est notable.
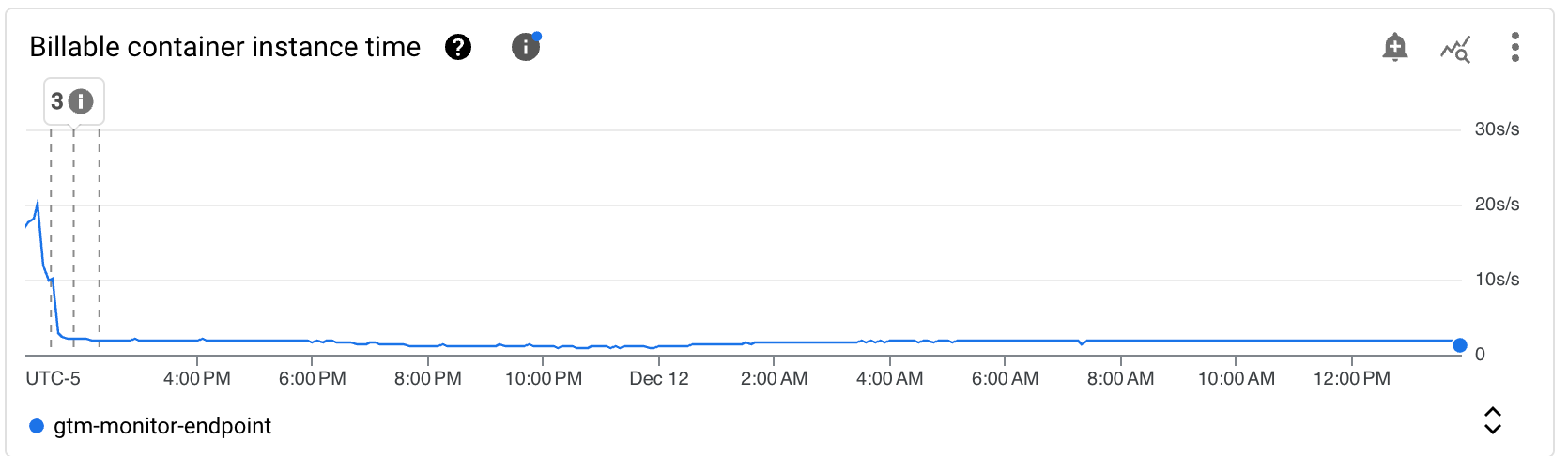
L’une des métriques en revanche, n’est “que” divisée par 2, et c’est celle que je cherche le plus à optimiser : Billable container instance time.
Modification des paramètres d’instance
Avant de songer à tout réécrire en Rust pour avoir un code qui tourne à la vitesse de la lumière, je voulais explorer la configuration des instances. Car l’optimisation du code est une chose, mais sur ce genre de services, certains aspects sont indépendants de cela : latence, cold start, concurrency, parallélisation, dimensionnement CPU/mémoire, etc.
L’option que je voulais tester en premier tellement c’est une évidence et d’augmenter la concurrency. Pourquoi utiliser plus d’instance que nécessaire si une seule peut gérer plusieurs requêtes en simultanées ?
Si ces notions ne vous sont pas familières, la documentation est assez fournie à ce sujet :
Configure Cloud Run functions | Cloud Run functions Documentation | Google Cloud
When you deploy or update a function created with the
Cloud Functions v2 API, you have access to
all of Cloud Run's configuration capabilities. Use this page to
understand a few of the configuration options that are available in
Cloud Run, how to control the behavior of your functions, and what the
best practices are for each type of configuration.
See Cloud Run documentation
for a full list of configuration options.
https://cloud.google.com/functions/docs/configuring/concurrency
Maximum concurrent requests for services | Cloud Run Documentation | Google Cloud
For Cloud Run services, each revision
is automatically scaled to the number of instances needed to handle
all incoming requests.
https://cloud.google.com/run/docs/about-concurrency
Concurrency vs. Parallelism
Concurrency and parallelism are two terms often used in relation to multithreaded applications. This tutorial explains the difference between concurrency and parallelism.
https://jenkov.com/tutorials/java-concurrency/concurrency-vs-parallelism.html
En utilisant une concurrence > 1, il est important de ne plus utiliser
table = client.get_table(table_ref) car chaque appel simultané augmente le temps d’exécution à cause de la latence de l’API. En cas de fort traffic, les instances vont bloquée une à une nécessitant d’en créer des nouvelles en générant des coûts supplémentaires. 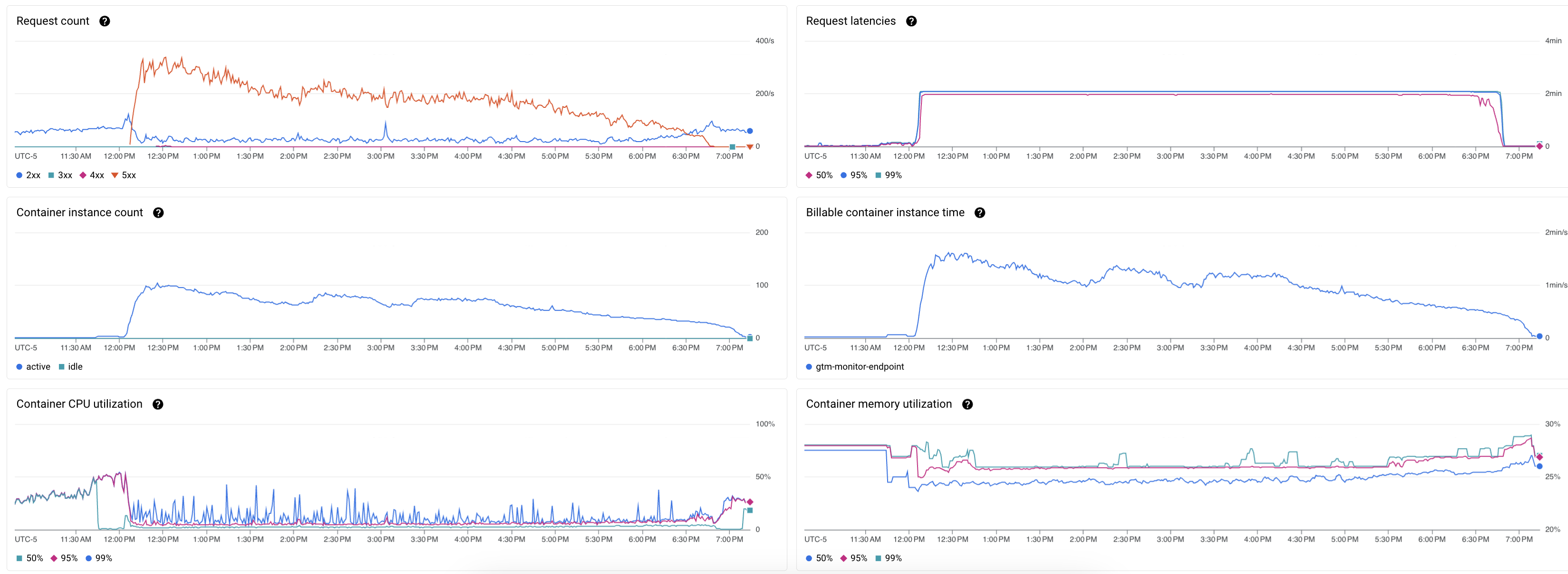
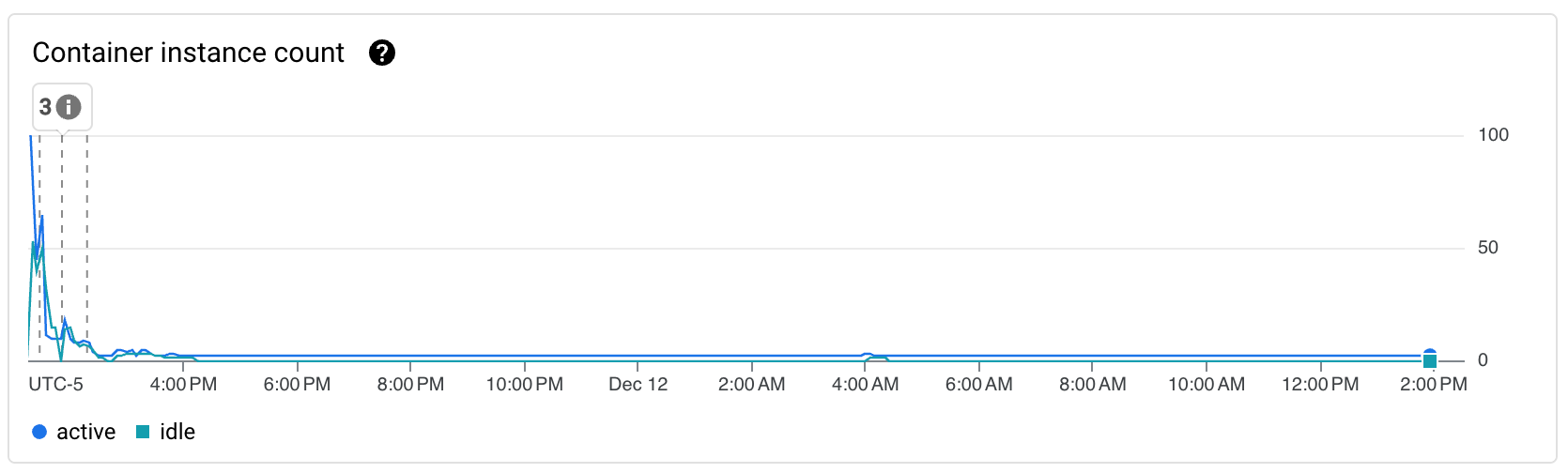
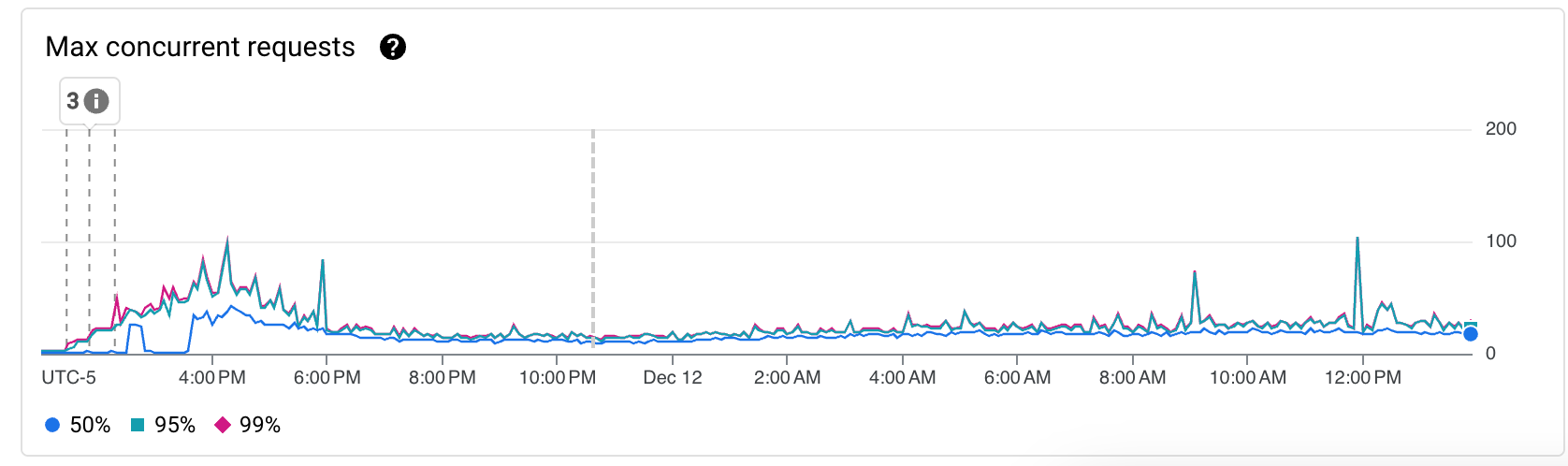
En rapide successions, j’ai donc déployé 3 révisions différentes (Les marqueurs différentiants étant affichés sur les graphs):
- Passage d’une concurrency de 1 à 10 (nécessitant le passage de 0.167 vCPU à 1 CPU) et réduction du timeout de 60s à 15s.
- Passage d’une concurrency de 10 à 20
- Passage d’une concurrency de 20 à 1000 (la limite)
En parallèle je regardais côté BigQuery pour vérifier que le nombre de lignes ingérées par minutes restaient cohérentes :
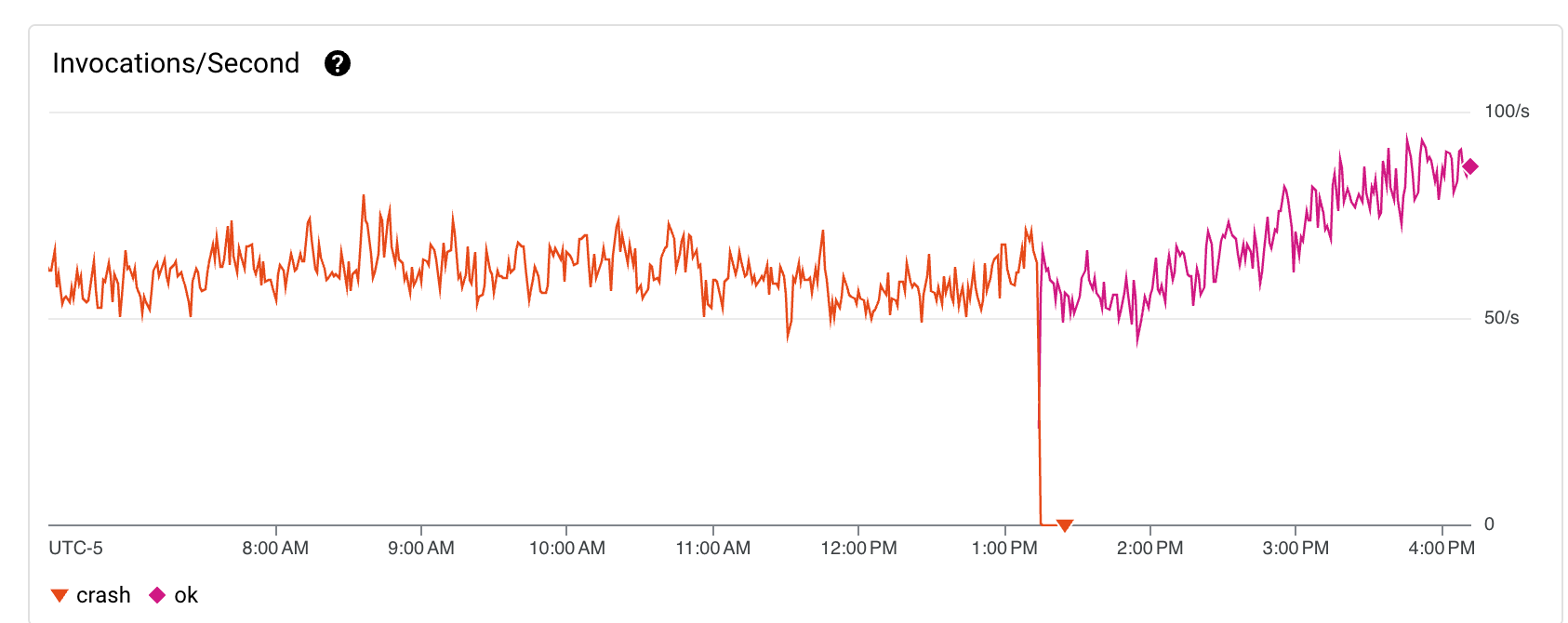
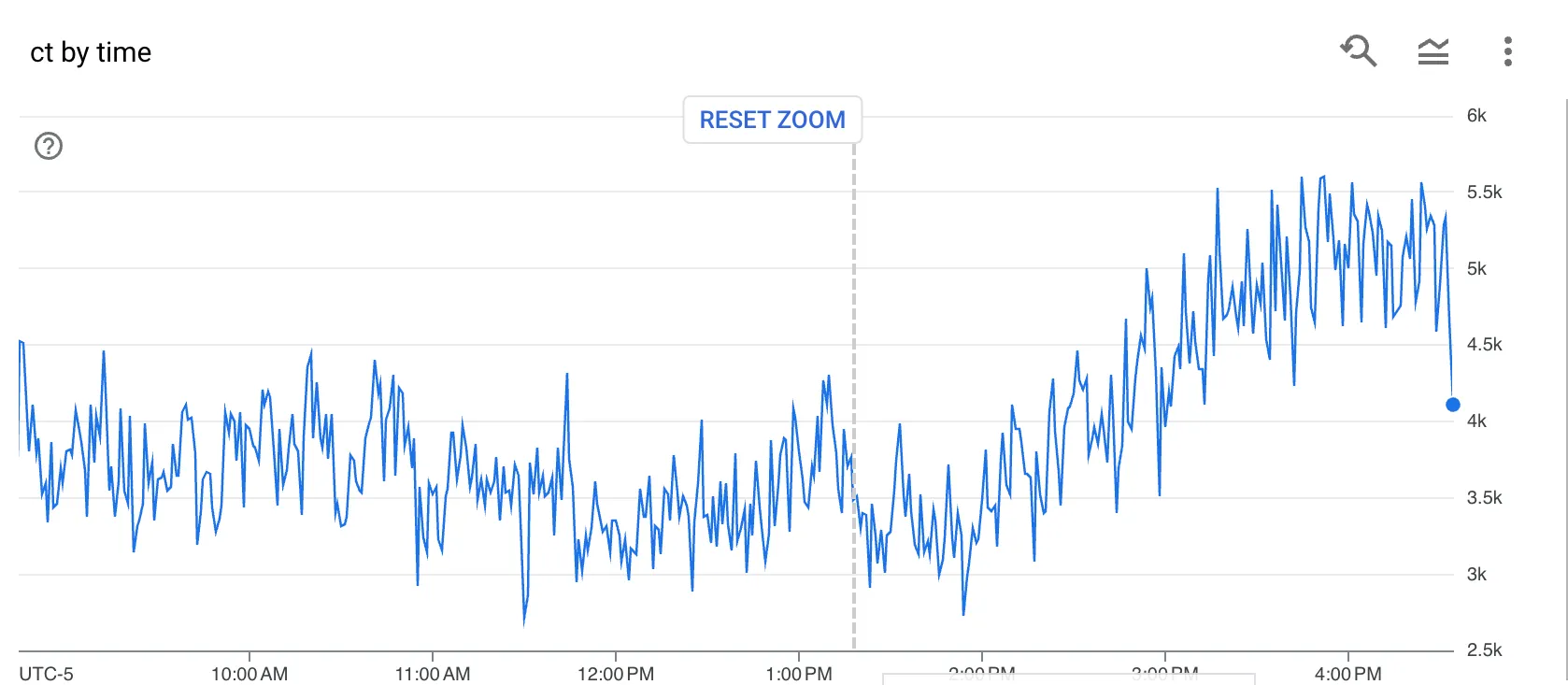
Et, encore une fois l’impact de ces changement est visible immédiatement alors même que le nombre d’invocations par seconde était sur une tendance croissante :
Impact sur les KPIs majeurs sur ces périodes
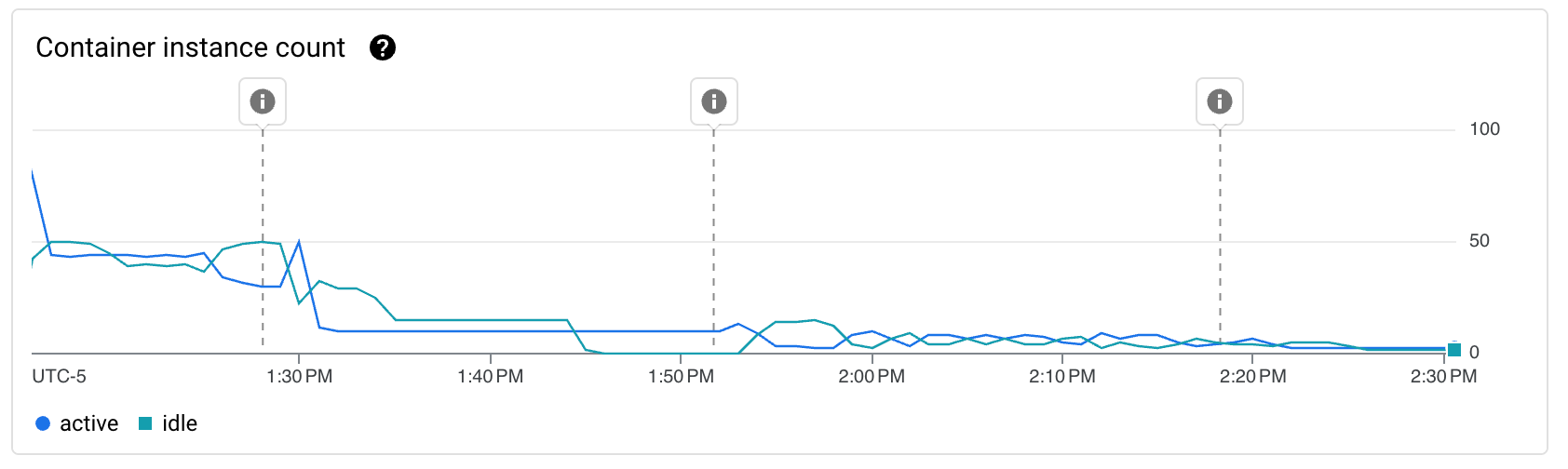
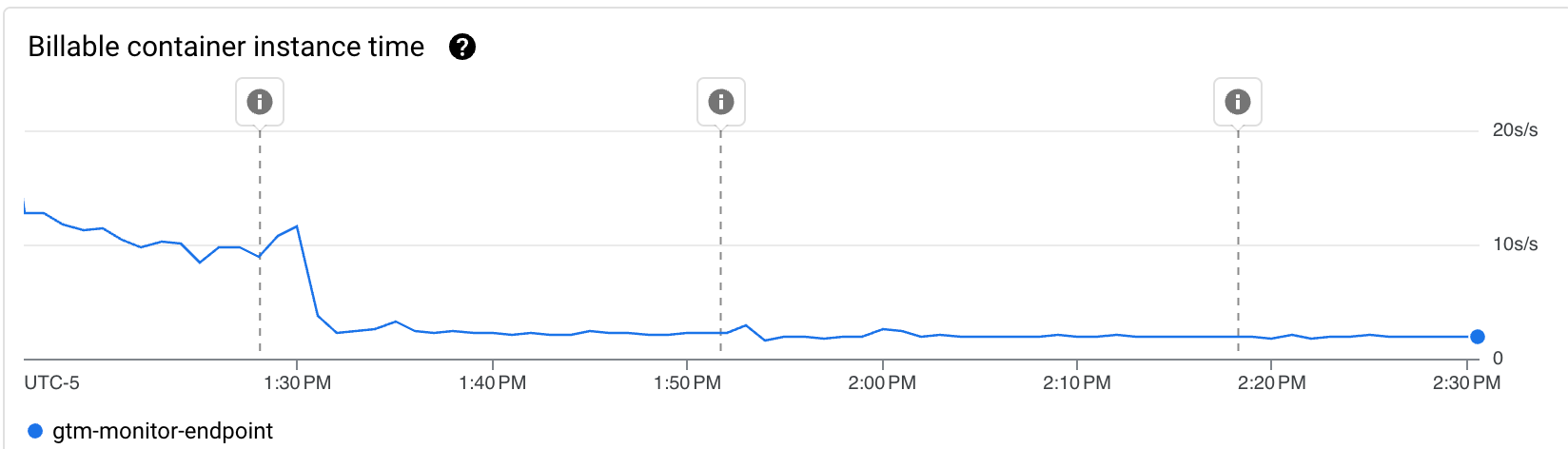

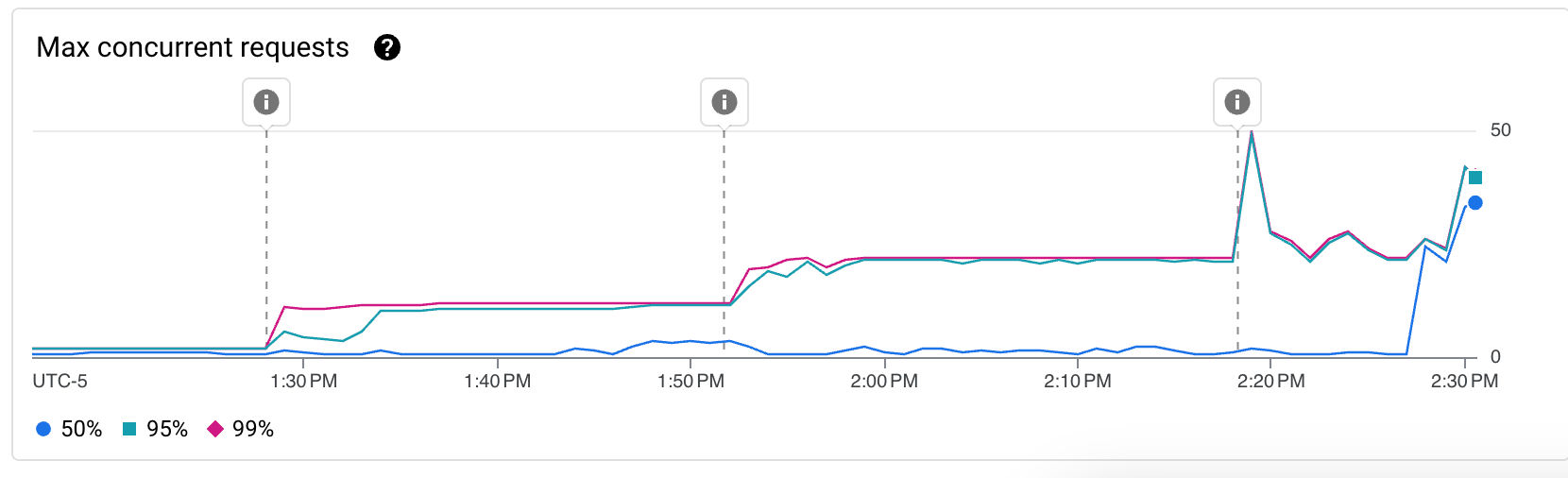
Suivi des KPI sur la journée suivante
Résultat
Globalement notre cher Billable container instance time est passé d’une moyenne de 20 s/s à moins de 2 s/s avec dans un premier temps l’optimisation du code qui l’a réduit d’un facteur 2, puis de l’autorisation du traitement des requêtes en simultané qui à permit une réduction d’un facteur 5 supplémentaire.
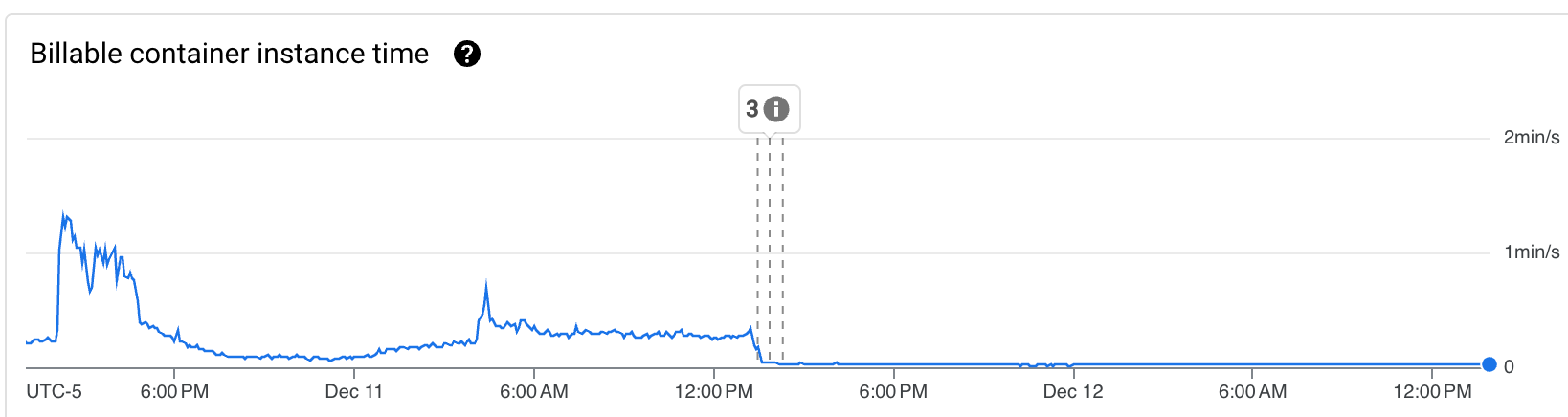
Cette division par 10 en quelques rapides ajustements nous est satisfaisant pour le moment et induit des coûts beaucoup plus raisonnables. Cependant certains tests sont prévus :
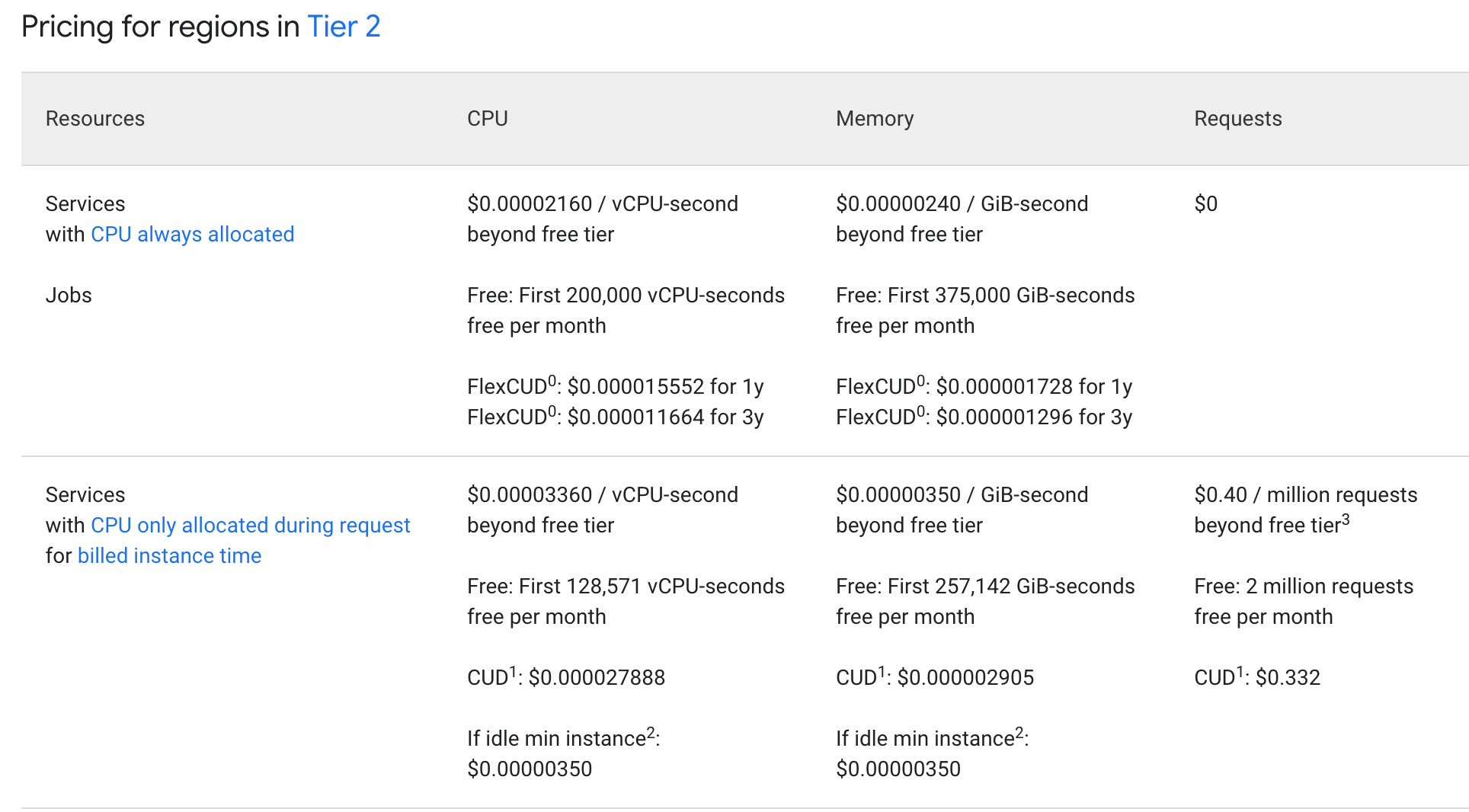
Vu qu’il y aura toujours un minimum de traffic sur les sites en questions, nous allons faire un test avec un “CPU always allocated”, cela pourra représenter environ 33% d’économies en plus. Mais surtout les requêtes sont gratuites - avec 200 millions de requêtes par mois cela ferait $80 d’économies supplémentaires chaque mois !
De plus, si le besoin est bien avéré et constant dans le temps, souscrire à un Commited Use sur 1 ou 3 ans permettrait d’avoir des réductions non-négligeables supplémentaires.
Enfin si un autre système de compute ou un autre language, nous parait plus judicieux à terme au vu d’un passage à l’échelle majeur nous considèrerons cette option.
Spoiler alert: Un article arrive à ce sujet ;)
Conclusion
Cette aventure nous a bien conforté dans l’idée qu’il est primordial d’avoir les bons réflexes FinOps pour piloter les usages et la consommation chez nos Cloud Providers préférés. Cela passe par la mise en place d’alertes, de quotas, d’outils de monitoring et de la formation.
Cela permet d’être alerté et de réagir rapidement, d’éviter les mauvaises surprises en fin de mois, d’anticiper les projets à surveiller, et de continuer à utiliser ces services en toute sérénité !