Par Nicolas le ‣
Objectif
L'objectif est de segmenter une table entre un groupe de traitement (lignes sur lesquelles nous allons réaliser une action), et un groupe de contrôle (lignes sur lesquelles nous n'allons rien faire).
Pourquoi faire cela me direz vous ? Dans ce cas précis, voici ce que je souhaitais faire :
- Importer les données CRM dans BigQuery (c'est à dire tous les contacts de l'entreprise)
- A partir de ces données, créer des segments d'utilisateurs
- Pousser ces segments vers différentes plate-formes, afin de diffuser des publicités ou emails personnalisés (par exemple Facebook Ads, Google Ads, ou un outil d'emailing).
Dans le cadre de ce projet, je souhaite créer un groupe de contrôle, afin de mesurer l'impact de mes publicités : ce groupe de contrôle est constitué d'un pourcentage des utilisateurs (15% ici), que je ne vais pas inclure dans mes listes d'audience.
💡 Je pourrai ainsi mesurer l'impact de ma publicité (remarketing) via ce groupe de contrôle, en comparant par exemple le taux de réachat entre les deux groupes, ou le taux de transformation.
Problématique
L'enjeu est d'avoir quelque chose qui soit :
- Le plus aléatoire possible
- Le plus reproductible possible
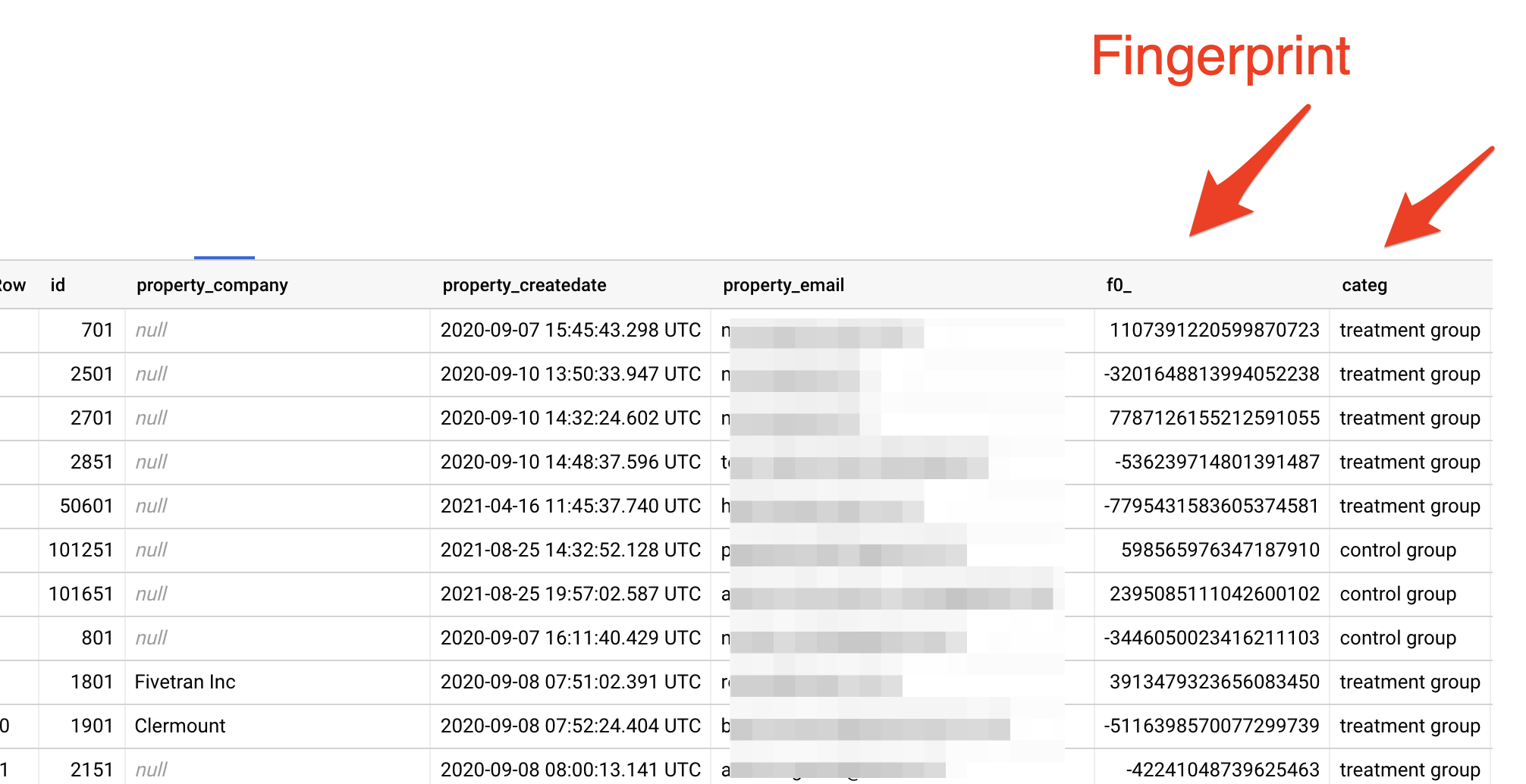
Pour cela, nous allons utiliser la fonction farm_fingerprint, qui génère un chiffre aléatoire à partir d'une chaîne de caractère, qui sera ici l'adresse email (que l'on conseille préalablement de "hasher" pour des raisons de protection des données).
Ce chiffre étant aléatoire, il y a donc statistiquement 15% de chance que le reste de sa division par 100 soit... inférieure à 100. C'est donc ce que nous allons utiliser :
sqlSELECT //Je sélectionneles champs que je vais utiliser par la suite id, property_company as company, property_createdate as createdate, property_email as email, property_lifecyclestage as lifecyclestage, // J'ajoute ma colonne "control group" CASE WHEN MOD(ABS(farm_fingerprint(property_email)), 100) < 15 THEN 'control group' ELSE 'treatment group' END AS categ FROM `reporting-digital.hubspot_unnest.contact`
Ce qui est intéressant ici, c'est que pour une adresse email donnée, j'aurai toujours le même résultat.
Résultat
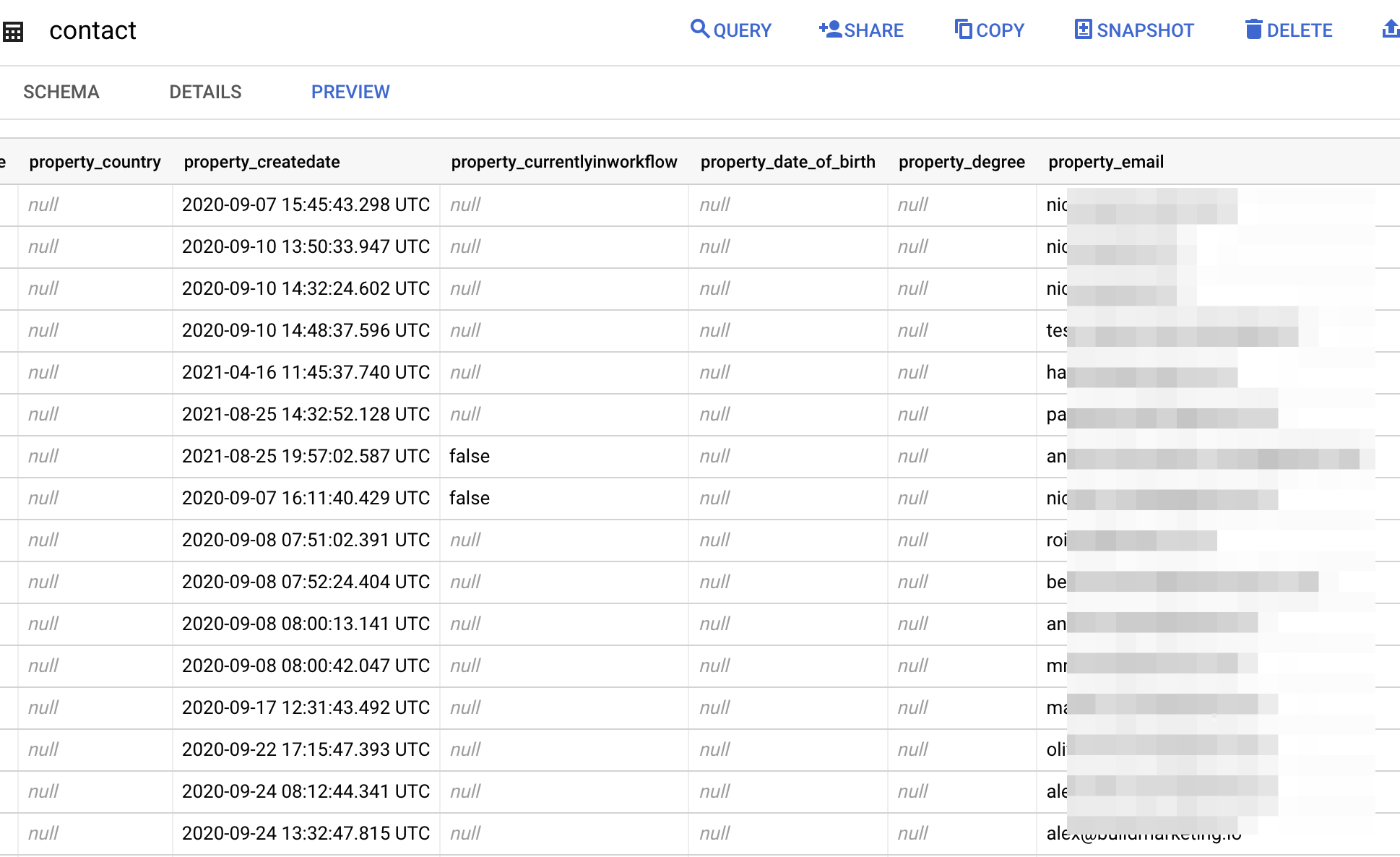
- En entrée, une table avec mes emails :
- En sortie, une table avec la colonne prenant une valeur aléatoire : "control group" dans 15% des cas :