
Rappel: Cloud Run Functions kesako?
Les fonctions “serverless” (aussi connues sous le nom de Lambda chez AWS ou Azure Functions chez Microsoft) permettent aux développeurs de déployer et d'exécuter des portions de code (fonctions) déclenchées de diverses manières. Et ce, avec une gestion simplifiée du système de scaling et avec une facturation basée sur l'utilisation “réelle” des ressources, le principe étant de ne plus avoir d'infrastructure à gérer directement.
‣
‣
Sur GCP, le service “Cloud Function” est en cours de fusion avec le service Cloud Run, car leurs cas d’usage se recouvrent fortement. À l’heure actuelle, le service s’appelle Cloud Run Function, mais il sera totalement intégré à Cloud Run à terme. Dans le reste de cet article, on utilisera “Cloud Run” pour plus de simplicité.
Qu’est-ce que le language vient faire dans tout ça ?
Faisant suite à cet article :  Cloud Run Functions : Retour d’expérience FinOps où on cherchait à diminuer les coûts d’une fonction très sollicitée. Et dans le contexte du “serverless” où la facturation est basée sur l'utilisation réelle des ressources, une question clé se pose : le choix du langage de programmation a-t-il un impact significatif sur les coûts ?
Cloud Run Functions : Retour d’expérience FinOps où on cherchait à diminuer les coûts d’une fonction très sollicitée. Et dans le contexte du “serverless” où la facturation est basée sur l'utilisation réelle des ressources, une question clé se pose : le choix du langage de programmation a-t-il un impact significatif sur les coûts ?
Cloud Run Functions : Retour d’expérience FinOps où on cherchait à diminuer les coûts d’une fonction très sollicitée. Et dans le contexte du “serverless” où la facturation est basée sur l'utilisation réelle des ressources, une question clé se pose : le choix du langage de programmation a-t-il un impact significatif sur les coûts ?De manière native, Cloud Run supporte les languages de programmation suivants :

Il est possible de déployer des images basées sur d’autres languages (i.e. Rust) via Cloud Run mais cela n’était pas possible à l’époque des Cloud Functions.
Les langages de programmation font souvent l’objet de débats passionnés dans le monde de la tech. Certains vouent presque un culte à leur langage favori, vantant une soi-disant simplicité ou encore des performances inégalées.
En réalité, ce sont des outils, et par conséquent, se prêtent plus ou moins bien en fonction des applications. Le benchmark ci-dessous est donné à titre indicatif et n’est pas à prendre au pied de la lettre, mais il montre clairement que tous les langages ne se valent pas en termes de performance.
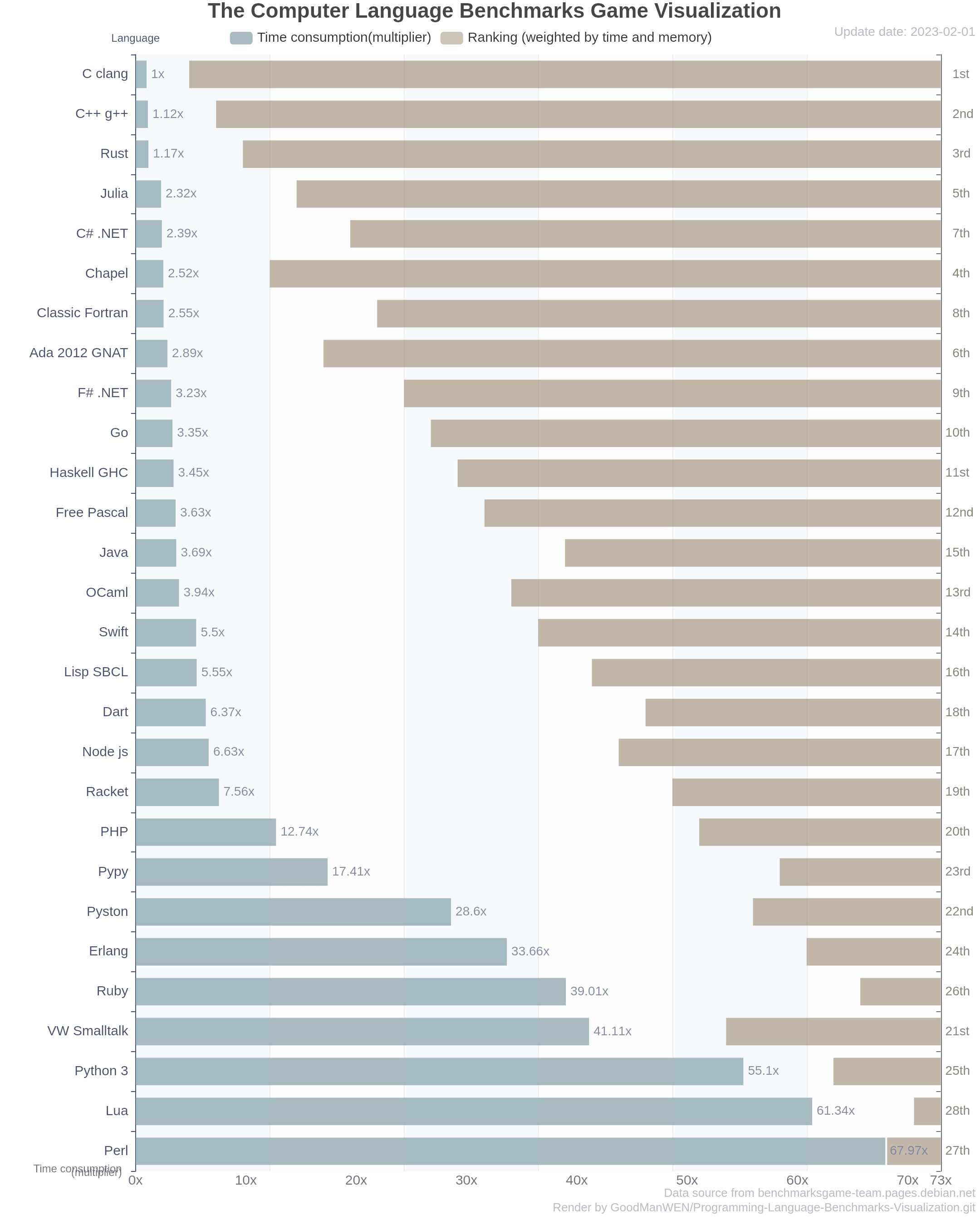
Contexte, test et résultats
Malgré les gains observés dans l’article précédent, le monitoring révèle que les pics de charge dépassent régulièrement la capacité d’une seule instance. L’autoscaling s’active fréquemment, augmentant ainsi le billable container instance time.
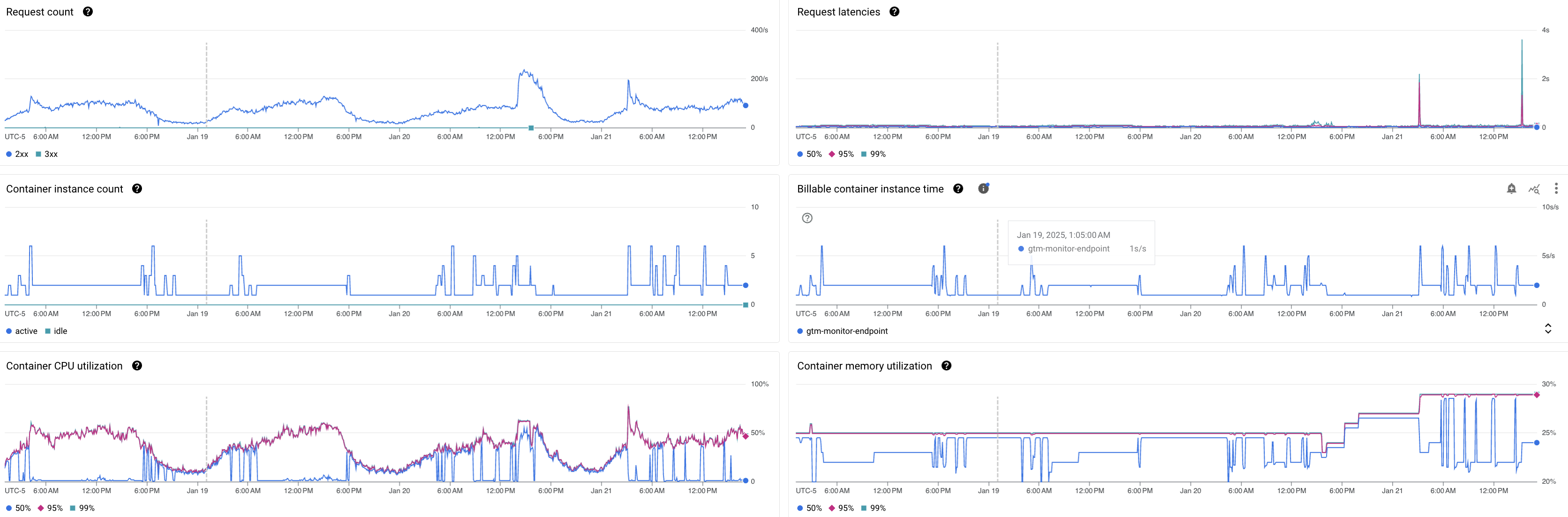
L'autoscaling, s'active lorsque l'utilisation CPU dépasse 60% (seuil non paramétrable actuellement), provoquant une augmentation du 'billable container instance time' (‣).
Comme l’instance flirte souvent avec ce seuil, on peut se demander si changer de langage permettrait d’améliorer suffisamment les performances pour que l’autoscaling ne se déclenche pas aussi souvent.
Go étant un langage qui m’intéresse, disponible sur Cloud Run et semblant offrir de meilleures performances que Python, j’ai converti le code existant (avec l’aide de mon ami Gemini) pour tester l’impact sur les coûts.
Code avant après (Python → Go) :
pythonfrom google.cloud import bigquery import datetime import logging from flask import Request # Add type hints for better readability PROJECT = 'me-gtm-monitoring' # Update to match your project name DATASET = 'src_gtm' # Update to match your dataset name TABLE = 'raw_data' # Update to match your table name # Initialize the BigQuery client globally to avoid re-initialization on each request client = bigquery.Client() def stream_bq(uri: str) -> None: """ Streams a single URI to BigQuery. Args: uri (str): The URI to be logged in BigQuery. """ try: table_ref = client.dataset(DATASET).table(TABLE) #table = client.get_table(table_ref) # Cache this to avoid unnecessary lookups # Insert the URI and current timestamp into the table rows_to_insert = [{ 'URI': uri, 'timestamp': datetime.datetime.utcnow().isoformat() # Use UTC for consistency }] errors = client.insert_rows_json(table_ref, rows_to_insert) # Use insert_rows_json instead of insert_rows if errors: # Log specific errors for better debugging logging.error("Errors while inserting rows into BigQuery: %s", errors) except Exception as e: logging.exception("An unexpected error occurred while streaming to BigQuery: %s", e) def gtm_monitor(request: Request) -> str: """ Cloud Function entry point. Processes an incoming request and streams the request URL to BigQuery. Args: request (flask.Request): The incoming request object. Returns: str: Response message indicating success or failure. """ try: if request and request.url: # Ensure request object and URL are valid logging.info("Received request with URL: %s", request.url) stream_bq(request.url) return 'Request URL has been successfully streamed to BigQuery.' else: logging.warning("No URL found in the request.") return 'No URL found in the request.' except Exception as e: logging.exception("An unexpected error occurred in gtm_monitor: %s", e) return 'An error occurred while processing the request.'
go// Package helloworld provides a set of Cloud Functions samples. package helloworld import ( "context" "fmt" "log" "net/http" "time" "cloud.google.com/go/bigquery" "github.com/GoogleCloudPlatform/functions-framework-go/functions" ) type LogEntry struct { URI string `json:"URI"` Timestamp time.Time `json:"timestamp"` } var ( projectID = "me-gtm-monitoring" // Update with your project ID datasetID = "src_gtm" // Update with your dataset ID tableID = "raw_data" // Update with your table name bqClient *bigquery.Client tableRef *bigquery.Table ) func init() { functions.HTTP("GTMMonitor", GTMMonitor) ctx := context.Background() var err error bqClient, err = bigquery.NewClient(ctx, projectID) if err != nil { log.Fatalf("Failed to create BigQuery client: %v", err) } tableRef = bqClient.Dataset(datasetID).Table(tableID) } func streamToBigQuery(uri string) error { ctx := context.Background() inserter := tableRef.Inserter() row := LogEntry{ URI: uri, Timestamp: time.Now().UTC(), } if err := inserter.Put(ctx, []*LogEntry{&row}); err != nil { return fmt.Errorf("failed to insert row into BigQuery: %v", err) } return nil } func GTMMonitor(w http.ResponseWriter, r *http.Request) { if r.URL == nil { http.Error(w, "No URL found in the request", http.StatusBadRequest) return } log.Printf("Received request with URL: %s", r.URL.String()) err := streamToBigQuery(r.URL.String()) if err != nil { log.Printf("Error streaming to BigQuery: %v", err) http.Error(w, "Failed to process the request", http.StatusInternalServerError) return } log.Printf("Successfully inserted URL: %s", r.URL.String()) w.WriteHeader(http.StatusOK) fmt.Fprintln(w, "Request URL has been successfully streamed to BigQuery.") }
🥁🥁🥁🥁🥁
Une fois déployé l’impact est immédiatement visible :
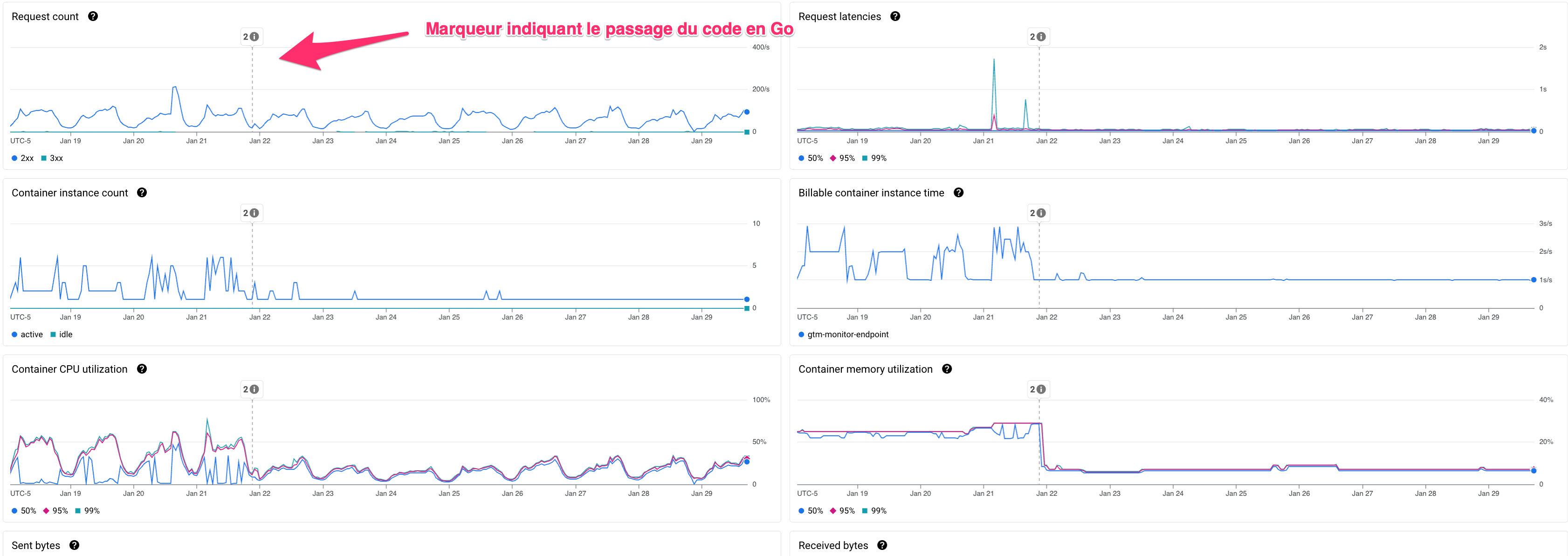
Le conteneur ne dépasse quasiment jamais le seuil de 60 % d’utilisation CPU. L’autoscaling ne s’active donc plus, et le billable container instance time reste désormais constant, ce qui permet de diminuer encore les coûts !
Conclusion
Bien que cette étude de cas ne prétende pas être un benchmark exhaustif de tous les langages proposés via les Cloud Run Functions, elle démontre clairement que le choix du langage peut avoir un impact significatif sur les coûts dans un environnement Cloud Run.
Dans notre cas d’usage, ce test montre que le langage utilisé a bel et bien un impact visible sur les coûts GCP à la fin du mois.