
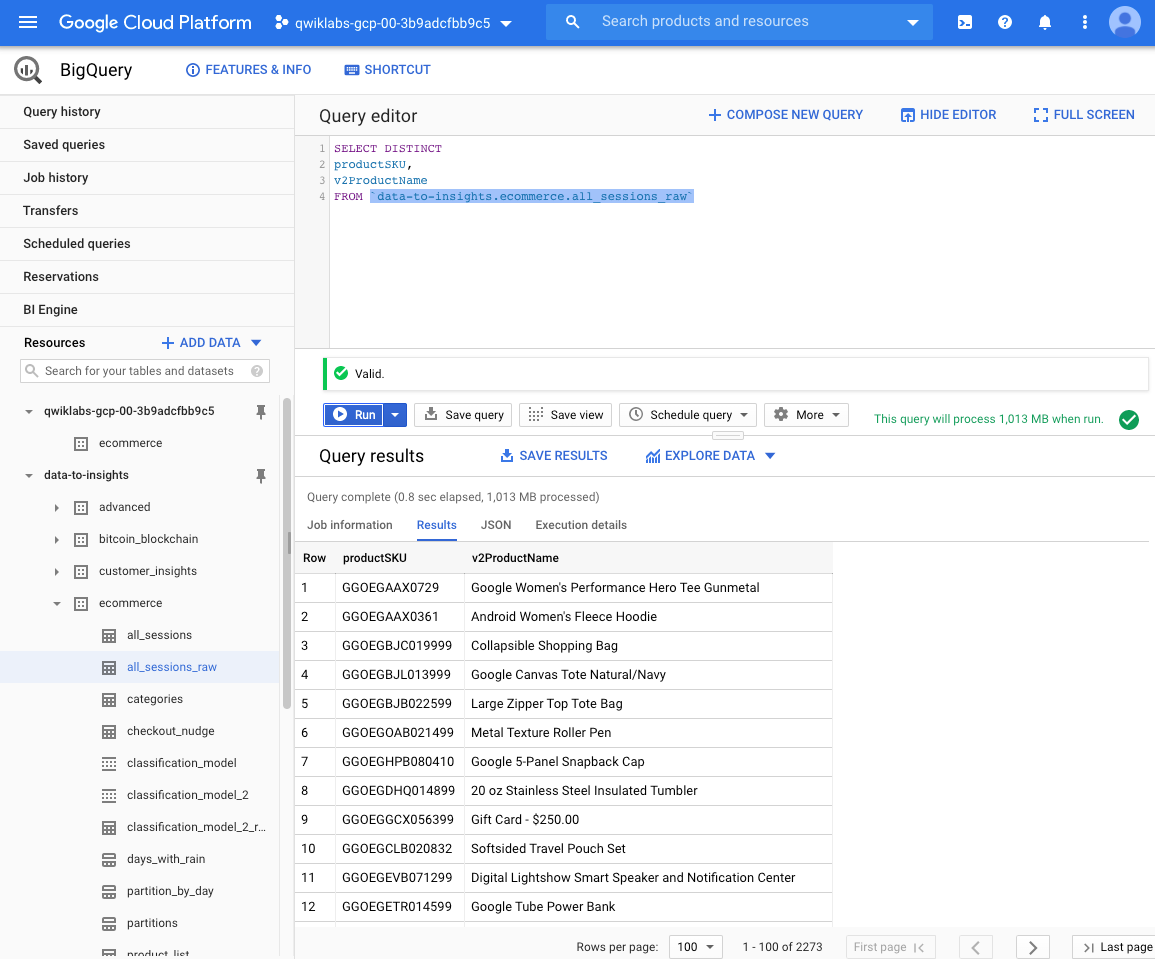
Google Big Query est l'élément central de la plupart des projets data sur Google Cloud Platform. Il s'agit du "Cloud Data Warehouse" de Google.
L'un des intérêts de Google Big Query, est qu'il dispose d'une interface web permettant d'explorer la donnée de manière relativement simple (pour celui qui sait faire des requêtes SQL bien entendu). Idéal donc pour un data analyst.
Google Big Query : présentation de l'interface web
L'accès à l'interface de Big Query se fait dans Google Cloud Platform. Dans le menu, on peut y accéder directement (dans la section "Big Data").
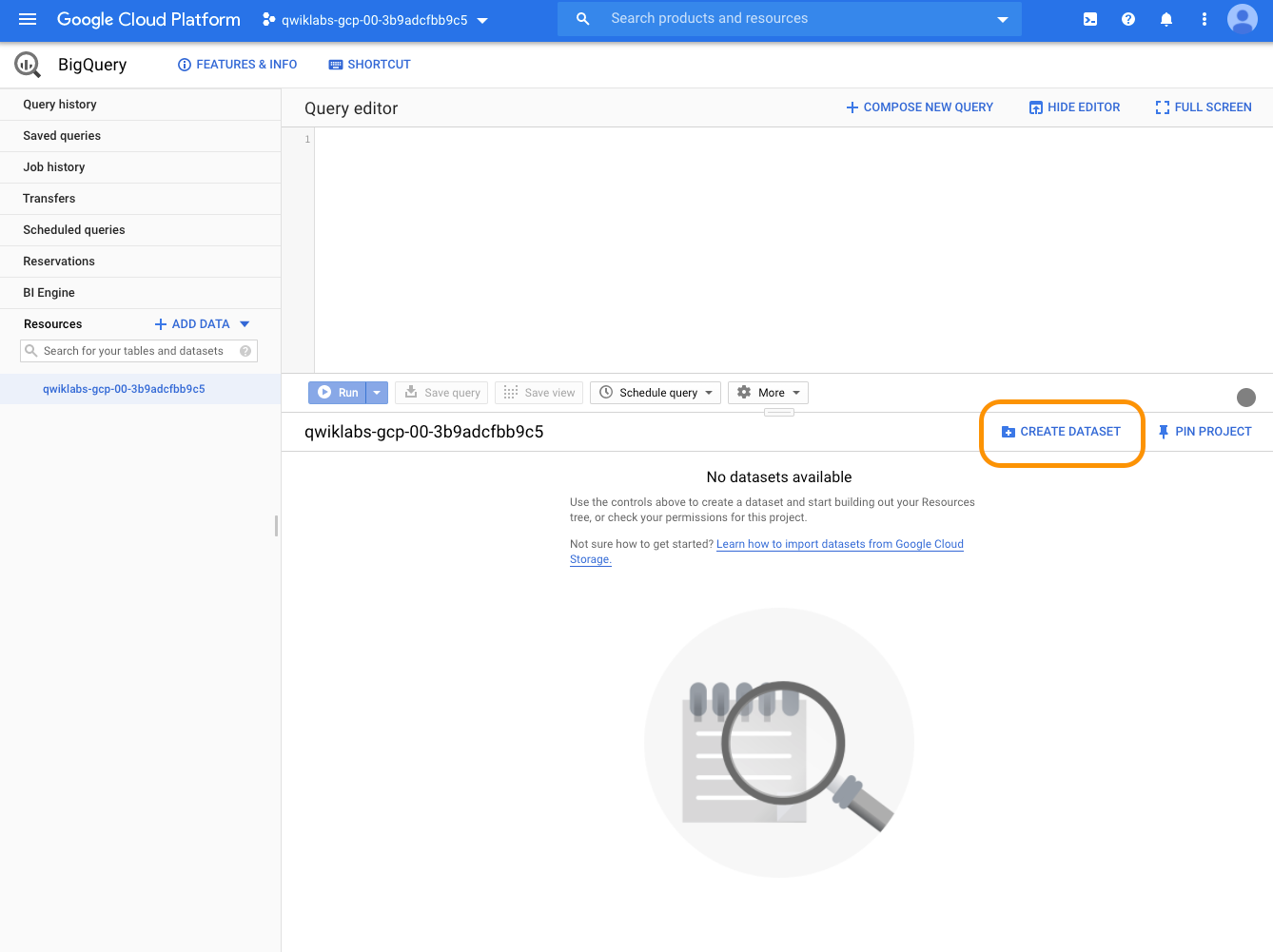
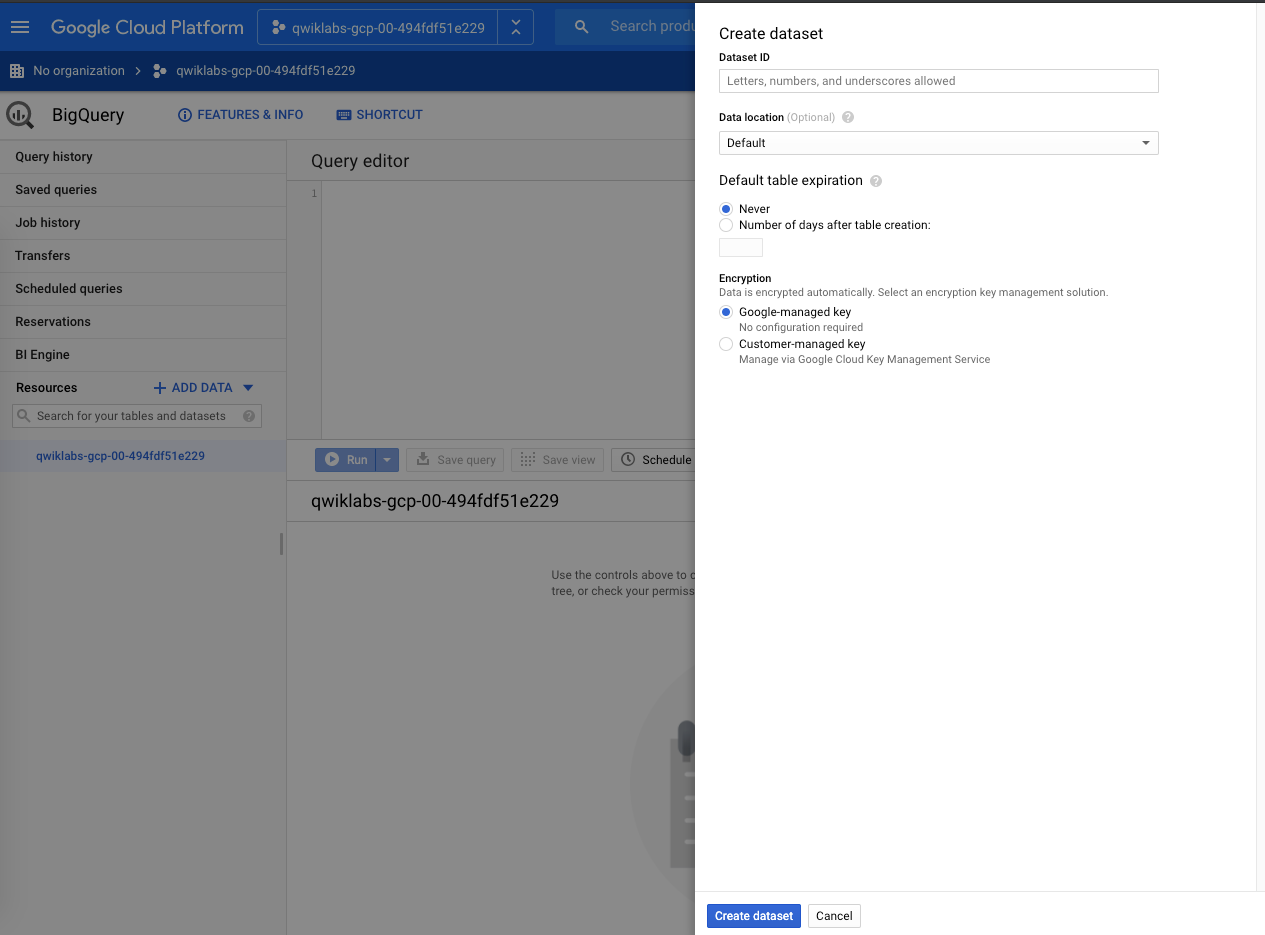
A la première connexion, l'interface apparaît d'abord vide. En sélectionnant votre projet, vous pouvez créer un premier Dataset :
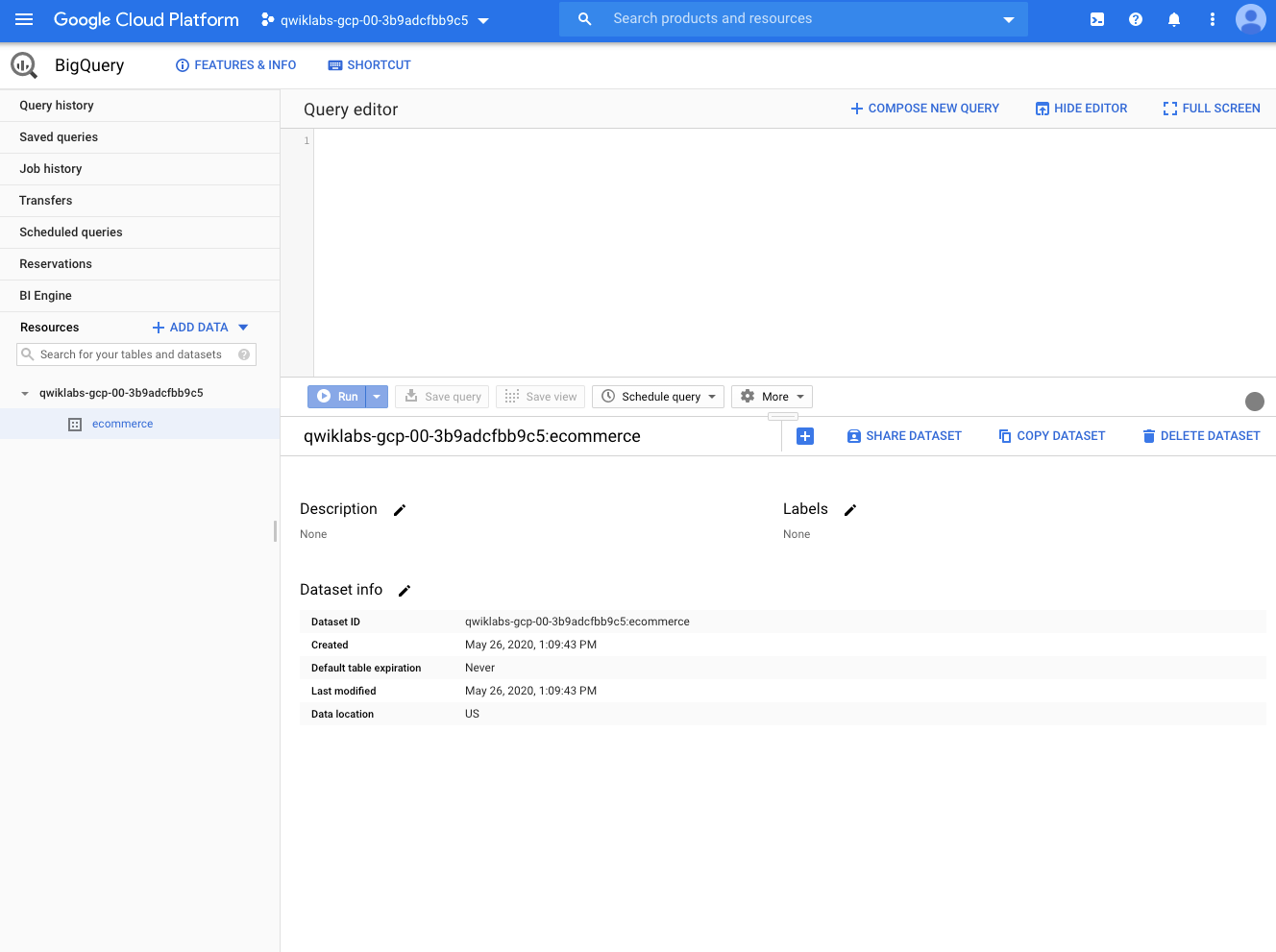
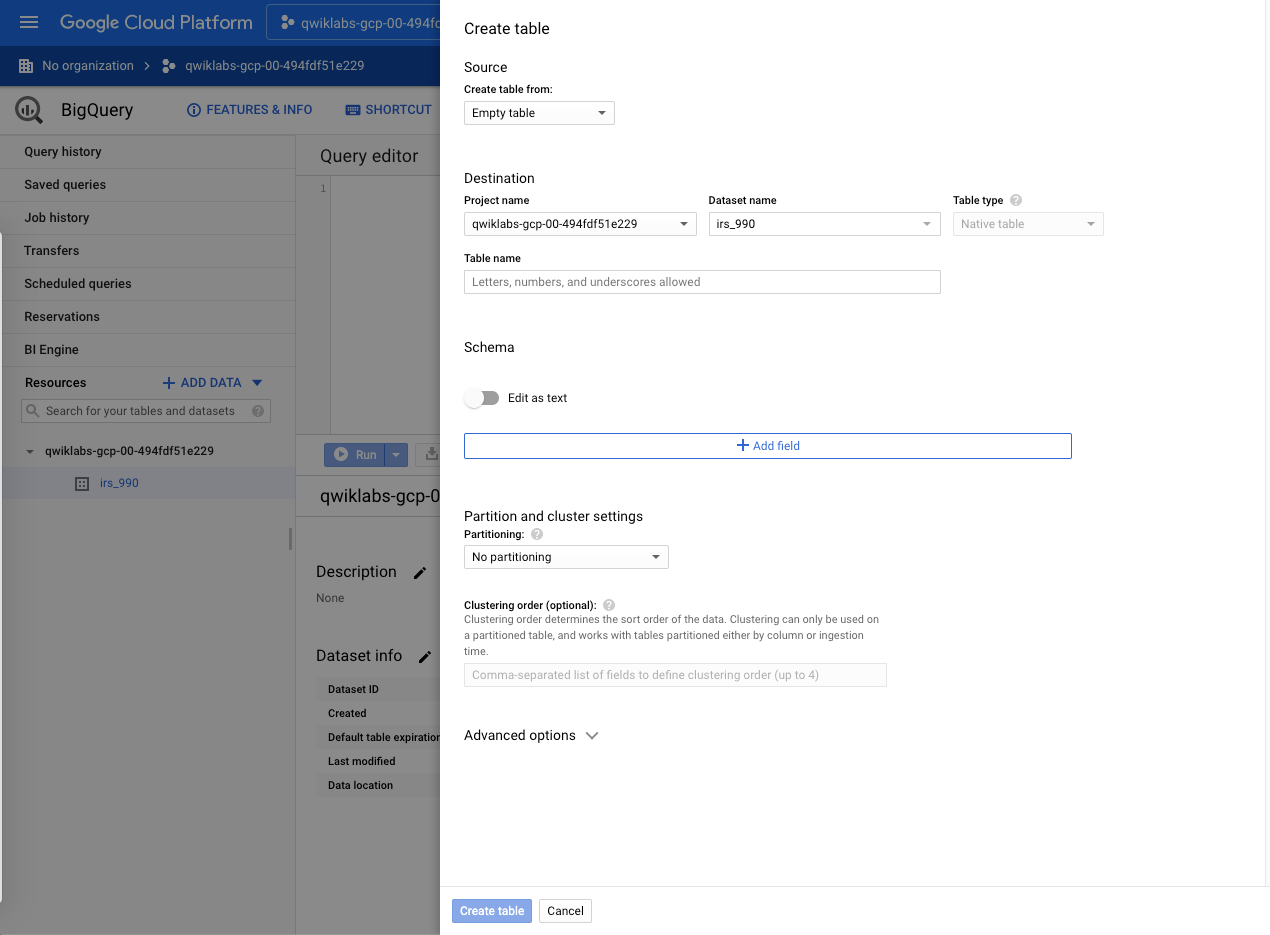
Il va maintenant falloir le peupler, en créant ou en important des tables
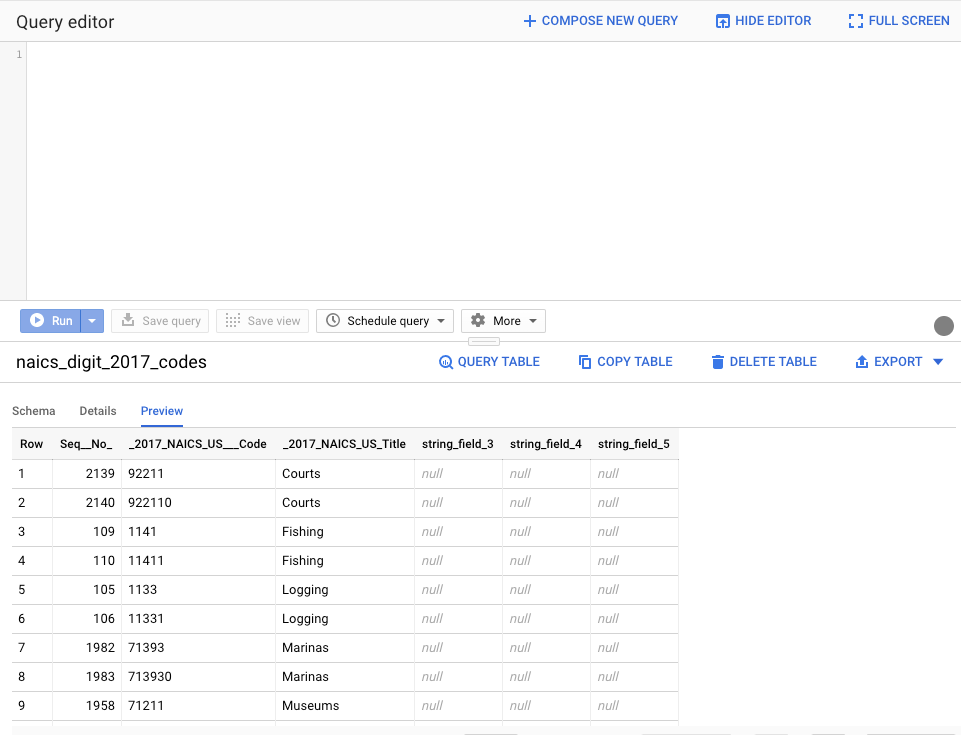
Vous pouvez ensuite accéder à l'ensemble des tables de vos projets. Naviguer à l'intérieur, visualiser le schéma, des tables, ou encore pré-visualiser un échantillon de donnée.
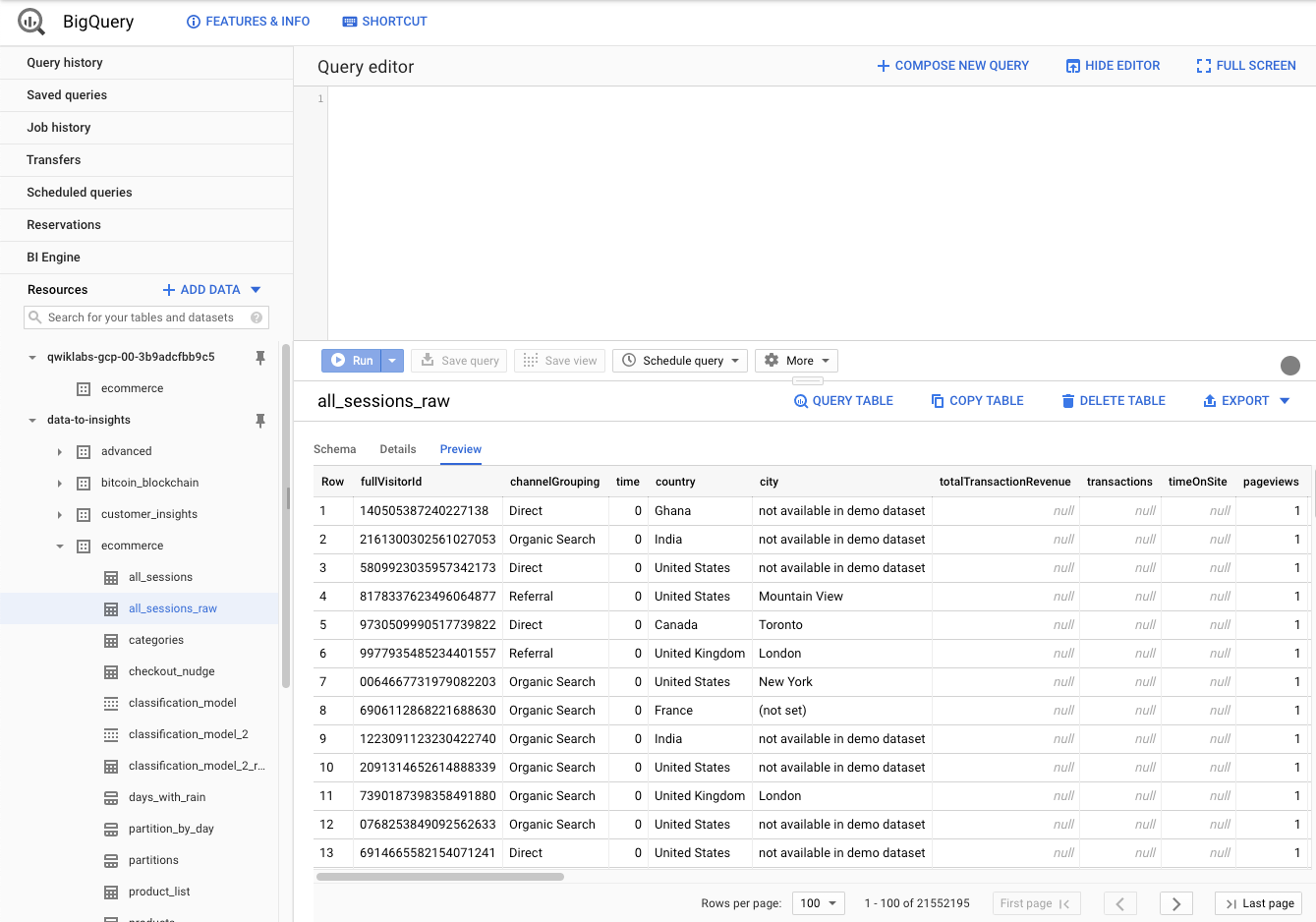
Et vous avez bien entendu accès au "Query Editor", qui permet d'exécuter des requêtes en SQL directement depuis l'interface, et d'afficher le résultat (ou de le stocker dans une table).
Uploader et requêter un Dataset en csv
Créer un Dataset :
A partir de votre dataset, cliquer sur "Create table"
Choisir comme source "Upload" :

Pour visualiser la table chargée, cliquer sur "Preview" :
Uploader et requêter un dataset via Google Cloud Storage
Dans votre Dataset, cliquez sur "Create table", et choisir "Google Cloud Storage". Dans le champs "GSC bucket", copiez le lien vers votre "bucket" GSC. Pour en savoir plus,
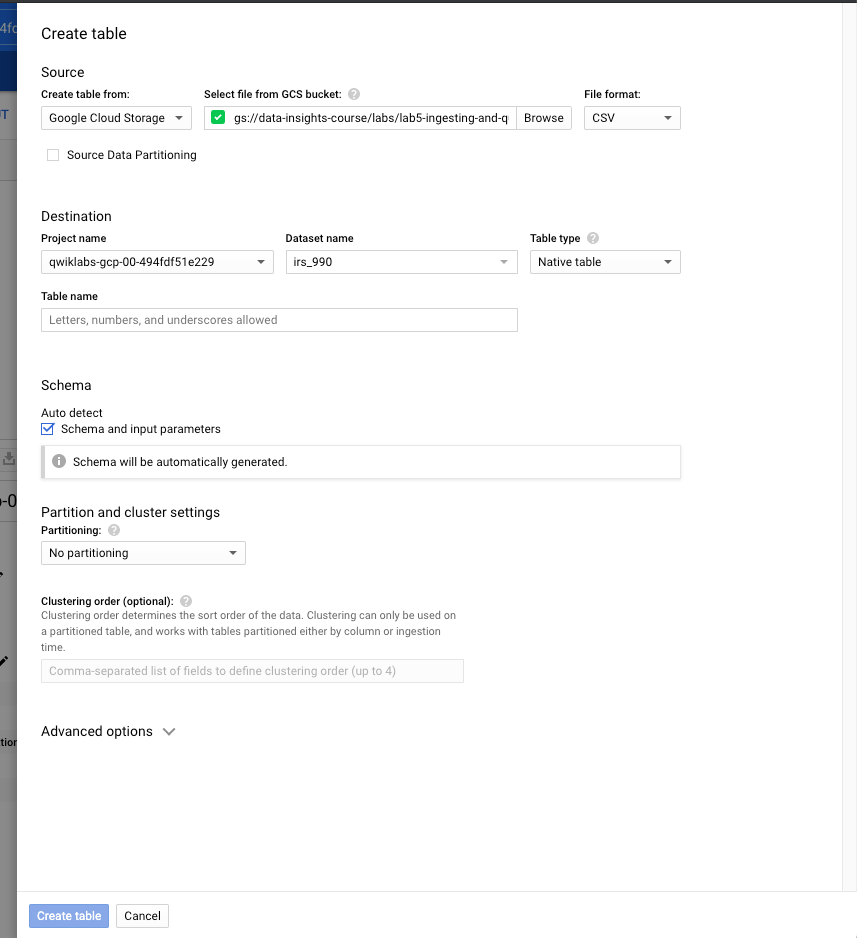
On peut choisir ses options :
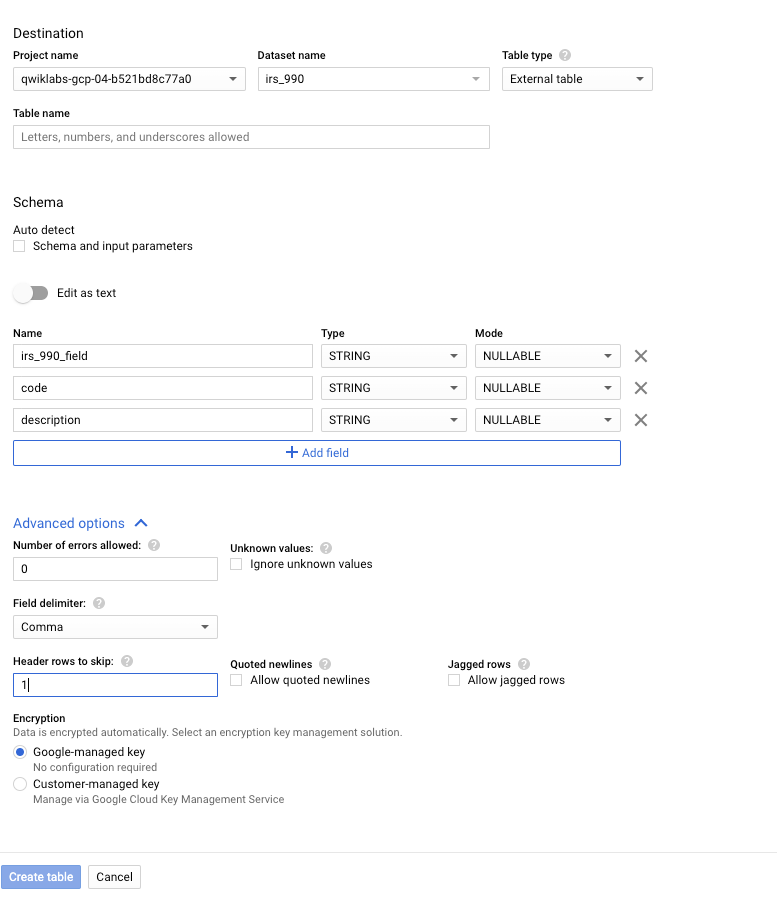
Attention : il s'agit d'une "external table". En terme de performance, cela sera donc moins bon.
Les tables partitionnées dans Google Big Query (Partitioned Tables)
Lorsque vous créez une table dans Big Query, il est possible de définir une partition. Cette partition peut être une date (en général, la date qui correspond à chaque ligne de donnée), ou alors par date d'ingestion de la donnée dans la table.
L'intérêt de créer une table partitionnée, c'est de pouvoir requêter seulement la partie de la table qui correspond à ce que l'on cherche.
Par exemple, imaginons que nous avons une table qui contient 10 années de ventes e-commerce, et que l'on veut faire une requête portant seulement sur 1 jour précis. Bien entendu, on peut faire une requête sur toute la table, avec une condition "chere" portant sur la date. mais en faisant cela, l'ensemble de la donnée sera processée. En terme de temps et de coûts, on va donc consommer beaucoup de ressource, pour pas grand chose.
La table partitionnée permet justement cela : traiter la donnée qui correspond à une plage de temps définie.
Créer une table partitionnée dans Google Big Query
Il faut simplement utiliser une commande SQL "Partition by". Par exemple ci-dessous :
sqlCREATE OR REPLACE TABLE ecommerce.partition_by_day PARTITION BY date_formatted OPTIONS( description="a table partitioned by date" ) AS SELECT DISTINCT PARSE_DATE("%Y%m%d", date) AS date_formatted, fullvisitorId FROM `data-to-insights.ecommerce.all_sessions_raw`
Dans l'interface web, votre table sera donc visible avec un picto spécifique. Et si vous allez dans l'onglet "Détails", vous verrez qu'il s'agit effectivement d'une table partitionnée.
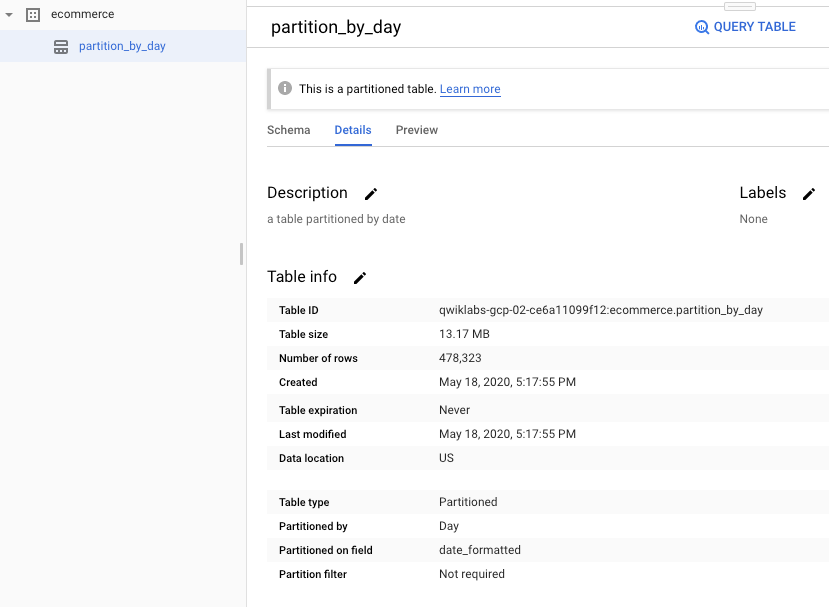
Pour requêter une table partitionnée, rien de plus simple. Il suffit de faire une requête SQL "standard", avec une clause "Where" portant sur la date. Vous verrez que la quantité de donnée processée est faible, et que le tempsd 'exécution est donc très rapide.
Par exemple :
sqlSELECT * FROM ecommerce.partition_by_day WHERE date_formatted = '2016-08-01'
Créer une table partitionnée avec dates d'expiration
Ici, c'est le même principe. Mais en complément, on va introduire une notion d'expiration de la donnée. On utilise simplement l'option "partition_expiration_days"
Par exemple :
sqlCREATE OR REPLACE TABLE ecommerce.days_with_rain PARTITION BY date OPTIONS ( partition_expiration_days=90, description="weather stations with precipitation, partitioned by day" ) AS SELECT ....
De cette manière, toutes les "anciennes" données seront supprimées au fur et à mesure que la requête est mise à jour.
Il s'agit d'un moyen simple pour limiter la quantité de donnée stockée dans une table, lorsque l'on connaît par avance la donnée que l'on va avoir à requêter souvent (par exemple pour un tableau de bord).