Le rapport sur l'expérience des utilisateurs de Chrome est disponible sur Google BigQuery, comme une source de donnée accessible à tous. Il s'agit d'un excellent moyen pour commencer à utiliser Google Big Query avec un cas pratique.
Pour commencer, vous aurez besoin d'un compte Google, d'un projet Google Cloud que vous utiliserez pour accéder au projet, et de connaissances de base sur SQL.
Accéder au projet Chrome User Experience report sur BigQuery
Le projet est disponible sur le lien https://console.cloud.google.com/bigquery?project=chrome-ux-report&page=dataset&d=all&p=chrome-ux-report.
Si vous visitez cette page et obtenez une invite à créer un projet comme celui ci-dessous, continuez avec les étapes suivantes pour créer un nouveau projet. Sinon, vous pouvez passer à la section suivante et commencer à interroger l'ensemble des données.
- Naviguez vers [Google Cloud Platform] (https://console.cloud.google.com/projectcreate) .
- Cliquez sur Create a Project.
- Donnez à votre nouveau projet un nom tel que "My Chrome UX Report" et cliquez sur Create.
Vous êtes maintenant prêt à commencer à interroger l'ensemble des données.
Comprendre le schéma de l'ensemble de données
Consultez la [documentation sur la méthodologie] (https://developers.google.com/web/tools/chrome-user-experience-report) pour un aperçu des mesures, des dimensions et du schéma de haut niveau.
Commençons à parcourir la donnée. D'une part, elle est organisée par pays (nous prendrons country_fr ici). D'autre part, par mois.
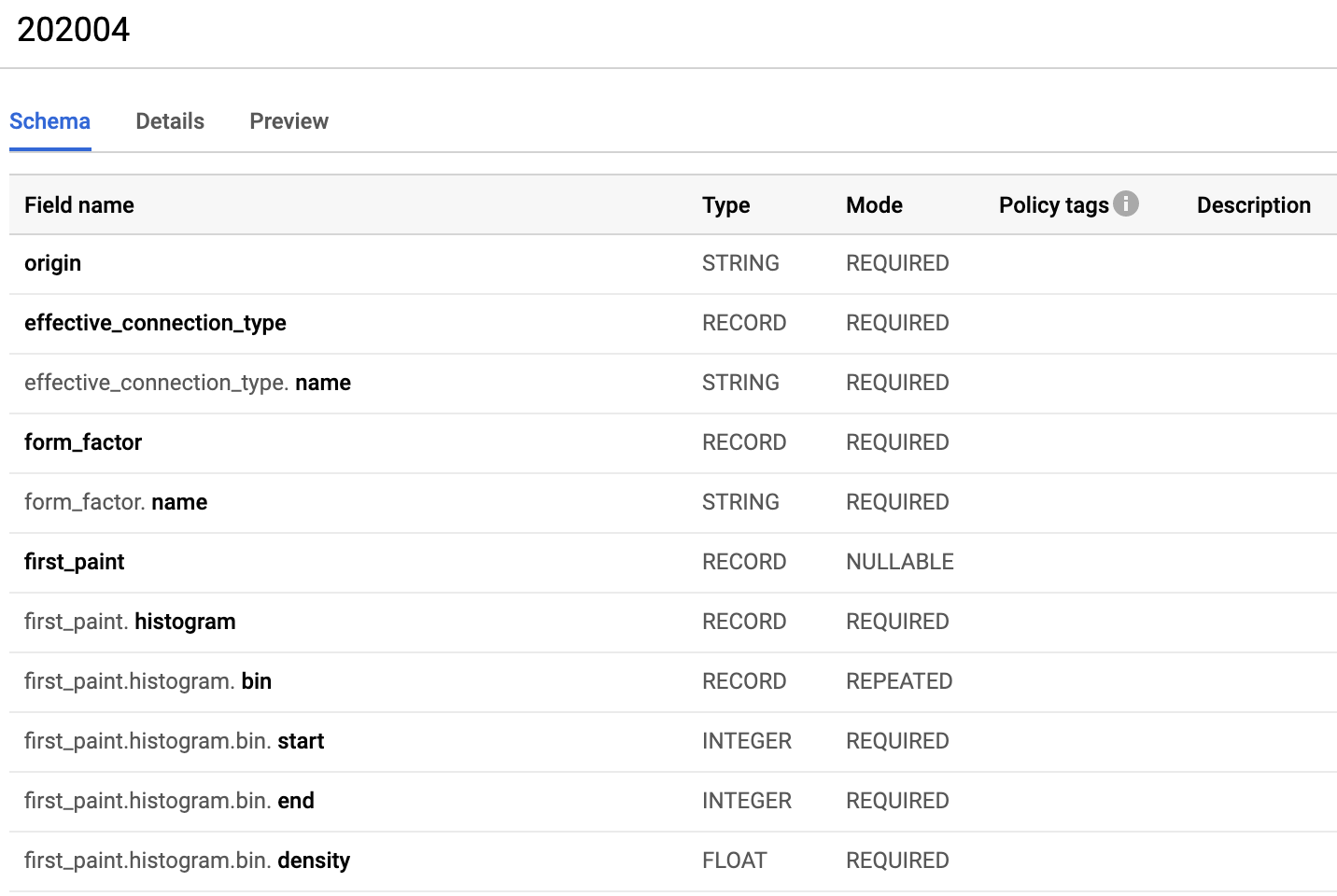
Si nous regardons maintenant le schéma de donnée, nous constatons que celle-ci est constituée de champs imbriqués (Nested fields en Anglais).
Requêter pour analyser la donnée
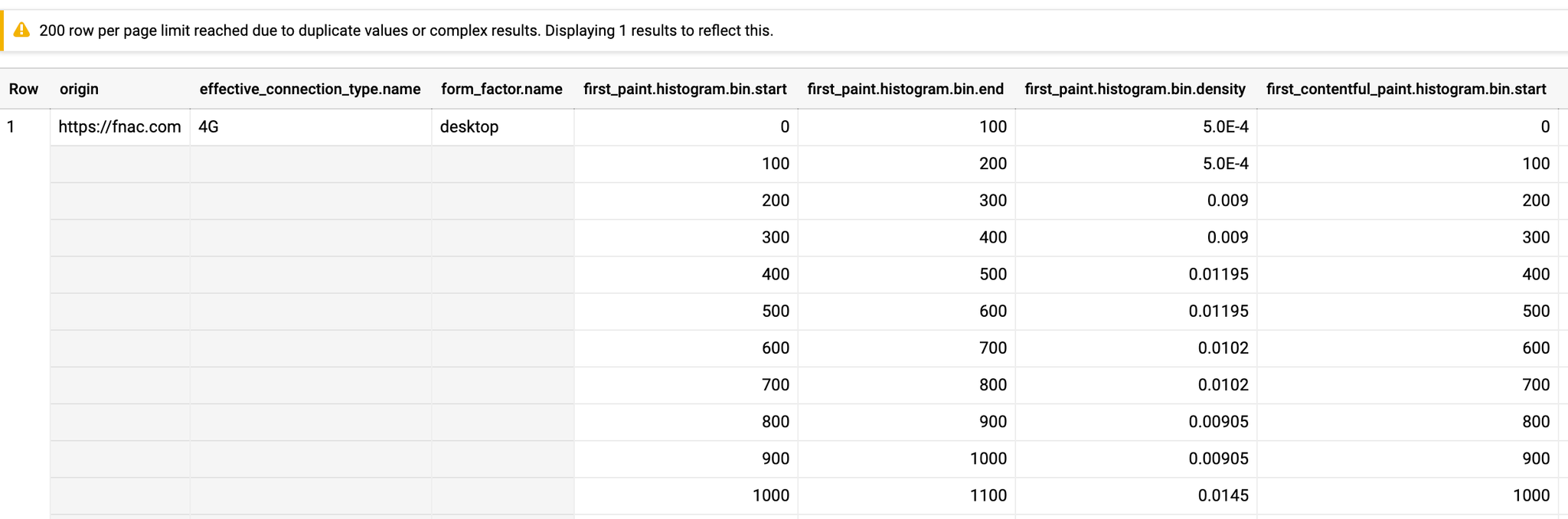
Commençons par une requête de base pour voir si un site en particulier est disponible dans l'ensemble de données. Par exemple fnac.com
sql#standardSQL SELECT * FROM `chrome-ux-report.country_fr.202005` WHERE origin LIKE '%://fnac.com' LIMIT 100
Nous avons bien des informations. Attention : il faut noter que cette simple requête a consommé 30Gb de donnée.
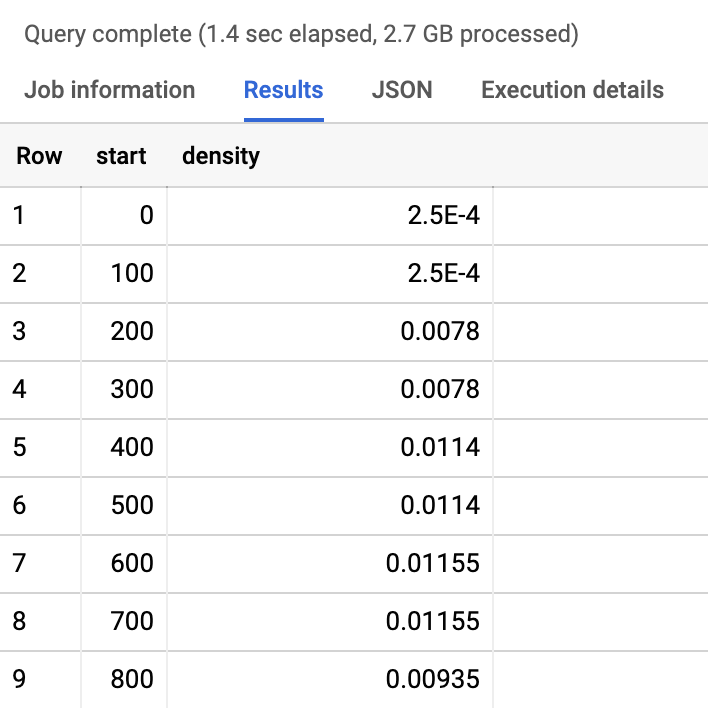
Nous pouvons maintenant plonger plus profondément dans les données relatives à l'expérience de l'utilisateur. Ecrivons une requête pour visualiser la distribution de l'histogramme.
sql#standardSQL SELECT bin.start, SUM(bin.density) AS density FROM `chrome-ux-report.country_fr.202005`, UNNEST(first_contentful_paint.histogram.bin) AS bin WHERE origin = 'https://fnac.com' GROUP BY bin.start ORDER BY bin.start
Voici les résultats :
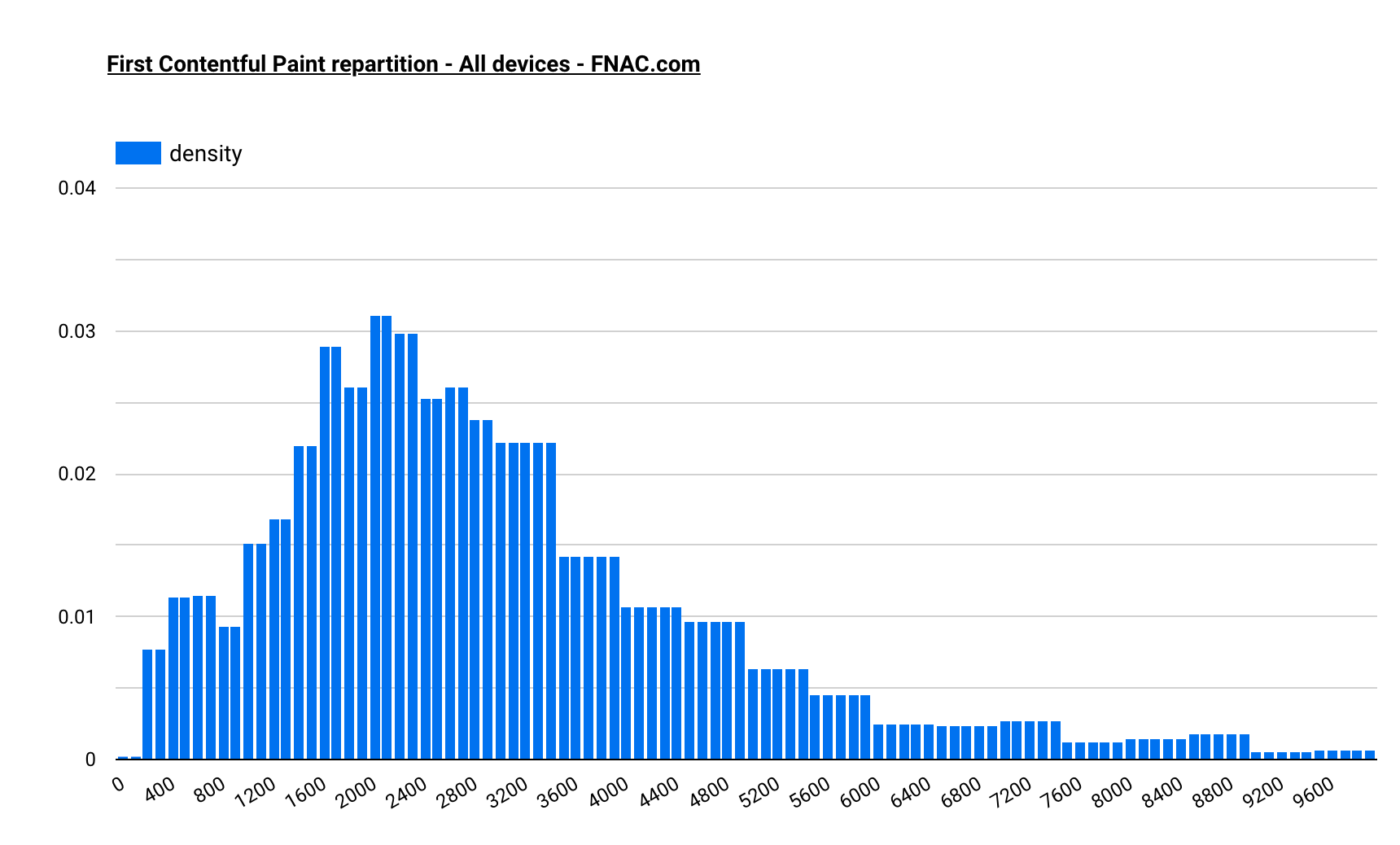
Que l'on peut visualiser plus simplement dans Google Data Studio
En modifiant un tout petit peu la requête, nous pouvons maintenant commencer à comparer les domaines entre eux.
sql#standardSQL SELECT bin.start, origin, SUM(bin.density) AS density FROM `chrome-ux-report.country_fr.202005`, UNNEST(first_contentful_paint.histogram.bin) AS bin WHERE origin IN ('https://www.fnac.com', 'https://www.cdiscount.com', 'https://www.amazon.fr') GROUP BY bin.start, origin ORDER BY bin.start
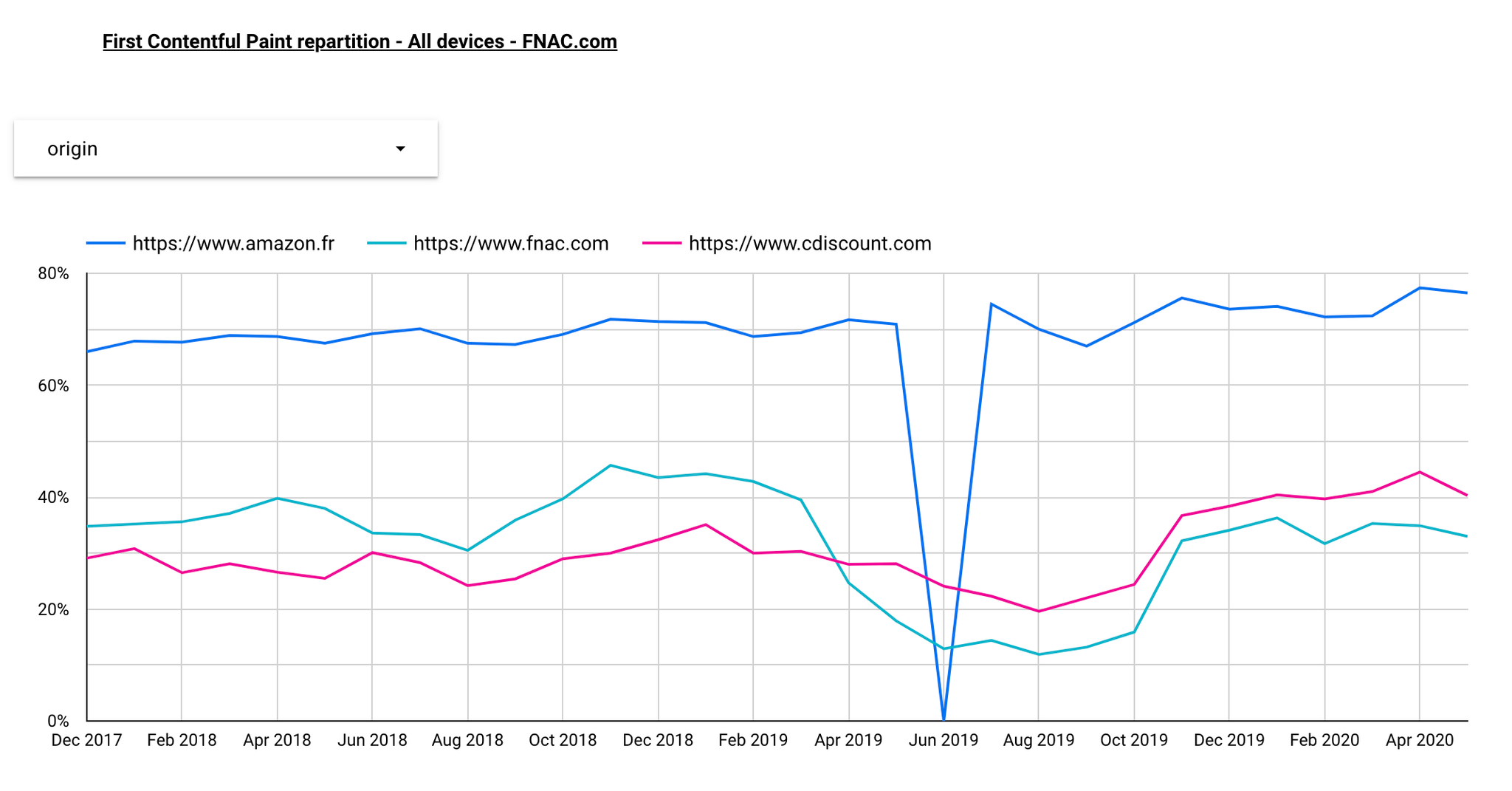
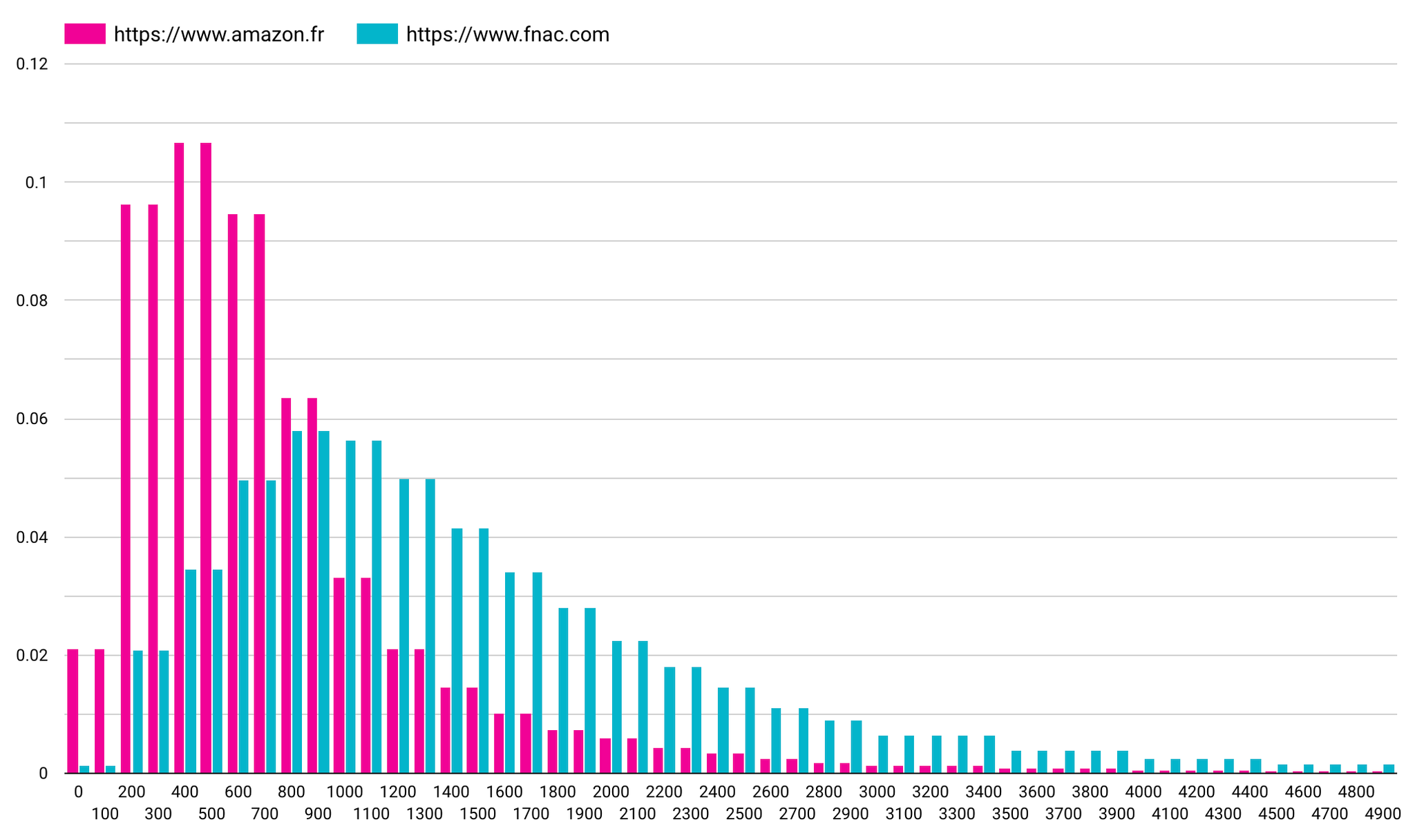
Par exemple FNAC et Amazon ci-dessous. On constate que la performance est clairement du côté d'Amazon, tant en terme de moyenne, que d'absence de valeurs extrêmement hautes :
Maintenant que nous avons un moyen d'examiner les données, écrivons quelques requêtes pour calculer des mesures de synthèse supplémentaires. Par exemple, comparons la part des utilisateurs ayant eu des FCP de moins de 1000 ms sur ces 3 sites :
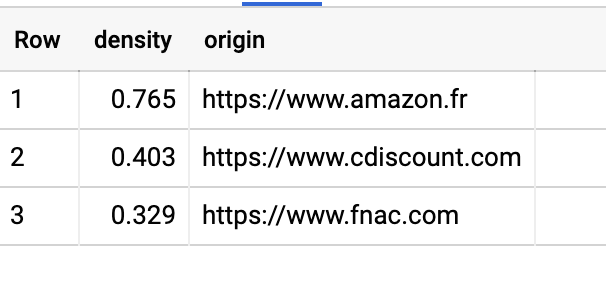
sql#standardSQL SELECT ROUND(SUM(bin.density),3) AS density, origin FROM `chrome-ux-report.country_fr.202005`, UNNEST(first_contentful_paint.histogram.bin) AS bin WHERE bin.start < 1000 AND origin IN ('https://www.fnac.com', 'https://www.cdiscount.com', 'https://www.amazon.fr') GROUP BY origin ORDER BY density DESC
Et voilà le résultat : 76,5% des vues de pages Amazon ce sont faites en moins de 1000ms, contre 32,9% pour la Fnac.
Nous pouvons aller plus loin et également segmenter l'ensemble de données via l'une des dimensions fournies. Par exemple, nous pouvons utiliser la [dimension du type de connexion effective] (https://developers.google.com/web/tools/chrome-user-experience-report/bigquery/getting-started#effective_connection_type) pour comprendre comment l'expérience ci-dessus varie pour des utilisateurs ayant des vitesses de connexion différentes.
sql#standardSQL SELECT effective_connection_type.name AS ect, origin, ROUND(SUM(bin.density),3) AS density FROM `chrome-ux-report.country_fr.202005`, UNNEST(first_contentful_paint.histogram.bin) AS bin WHERE bin.end <= 1000 AND origin IN ('https://www.fnac.com', 'https://www.cdiscount.com', 'https://www.amazon.fr') GROUP BY ect, origin ORDER BY density DESC
Le résultat de cette interrogation montre la fraction des utilisateurs qui font l'expérience du FCP en moins d'une seconde, divisée par type de connexion effective. À première vue, les utilisateurs d'une connexion 3G peuvent avoir des performances nettement inférieures, mais il est important de se rappeler que la valeur obtenue est relative à la population globale ; la valeur indiquée est également fonction de la taille de la population 3G, qui peut être inférieure - voir [conseils d'analyse et meilleures pratiques] (https://developers.google.com/web/tools/chrome-user-experience-report#analysis_tips_best_practices) pour en savoir plus.
Pour aller plus loin, nous allons vouloir requêter l'ensemble des mois disponibles, c'est à dire les tables allant de
chrome-ux-report.country_fr.201712 à chrome-ux-report.country_fr.202005Pour cela, nous allons utiliser la fonction "Table Wildcard" de BIgQuery, qui permet justement de faire cela de manière extrêmement simple :
sql#standardSQL SELECT effective_connection_type.name AS ect, origin, _TABLE_SUFFIX as date, ROUND(SUM(bin.density),3) AS density FROM `chrome-ux-report.country_fr.*`, UNNEST(first_contentful_paint.histogram.bin) AS bin WHERE bin.end <= 1000 AND origin IN ('https://www.fnac.com', 'https://www.cdiscount.com', 'https://www.amazon.fr') GROUP BY ect, origin, date ORDER BY date ASC
Nous récupérons donc une table avec toutes les valeurs, pour les 3 domaines sélectionnés, pour toutes les dates :
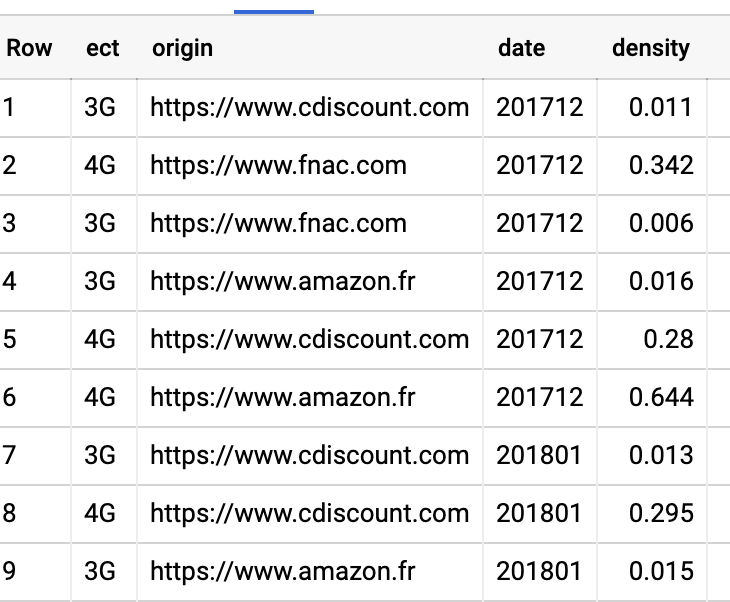
Automatiser la mise à jour
Nous allons construire un reporting dans Google Data Studio basé sur ces données. Afin d'éviter d'appeler toute la donnée à chaque fois, nous allons donc sauvegarder cette donnée dans une table, et mettre en place une récurrence de la requête.
Nous allons donc enregistrer les résultats de la requête dans une table
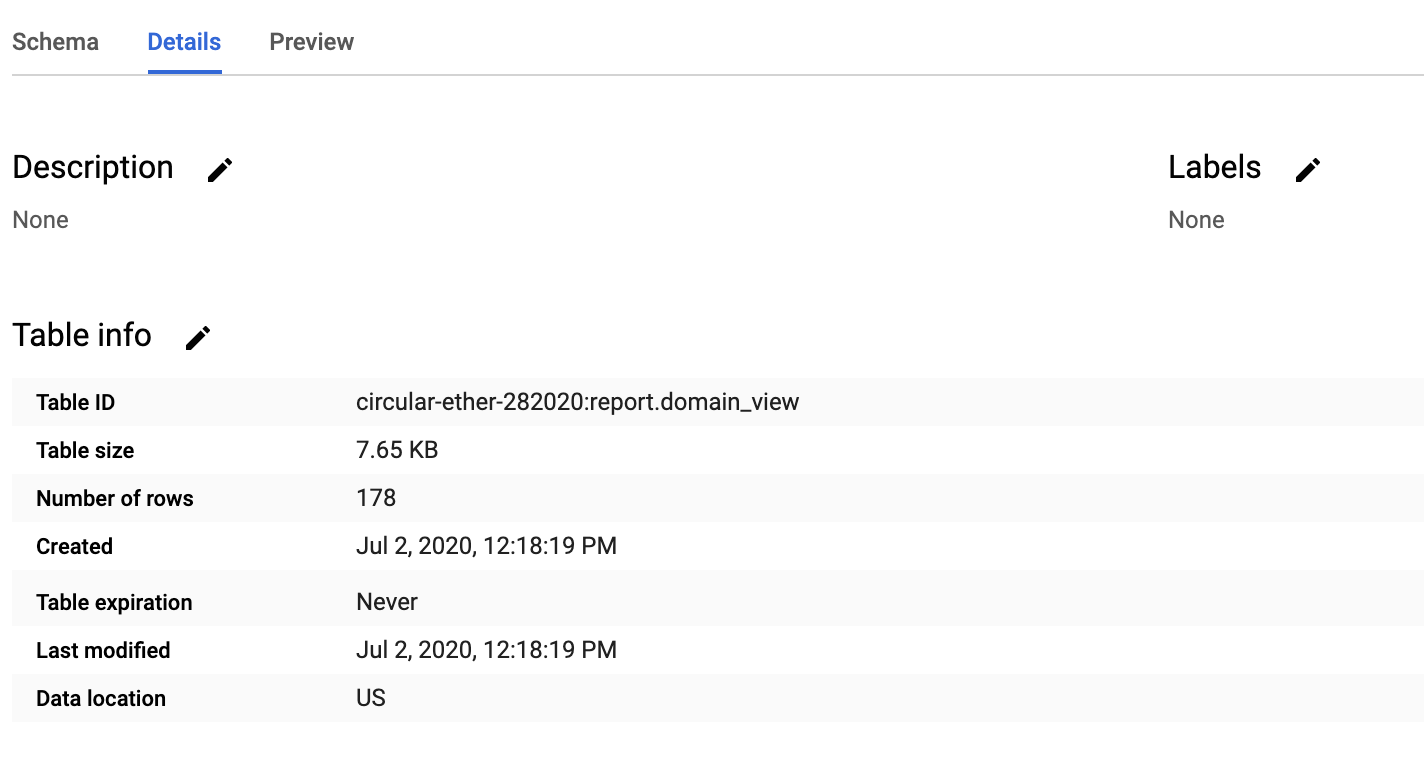
La table ne fait que 7kb. L'interroger sera donc pratiquement gratuit.
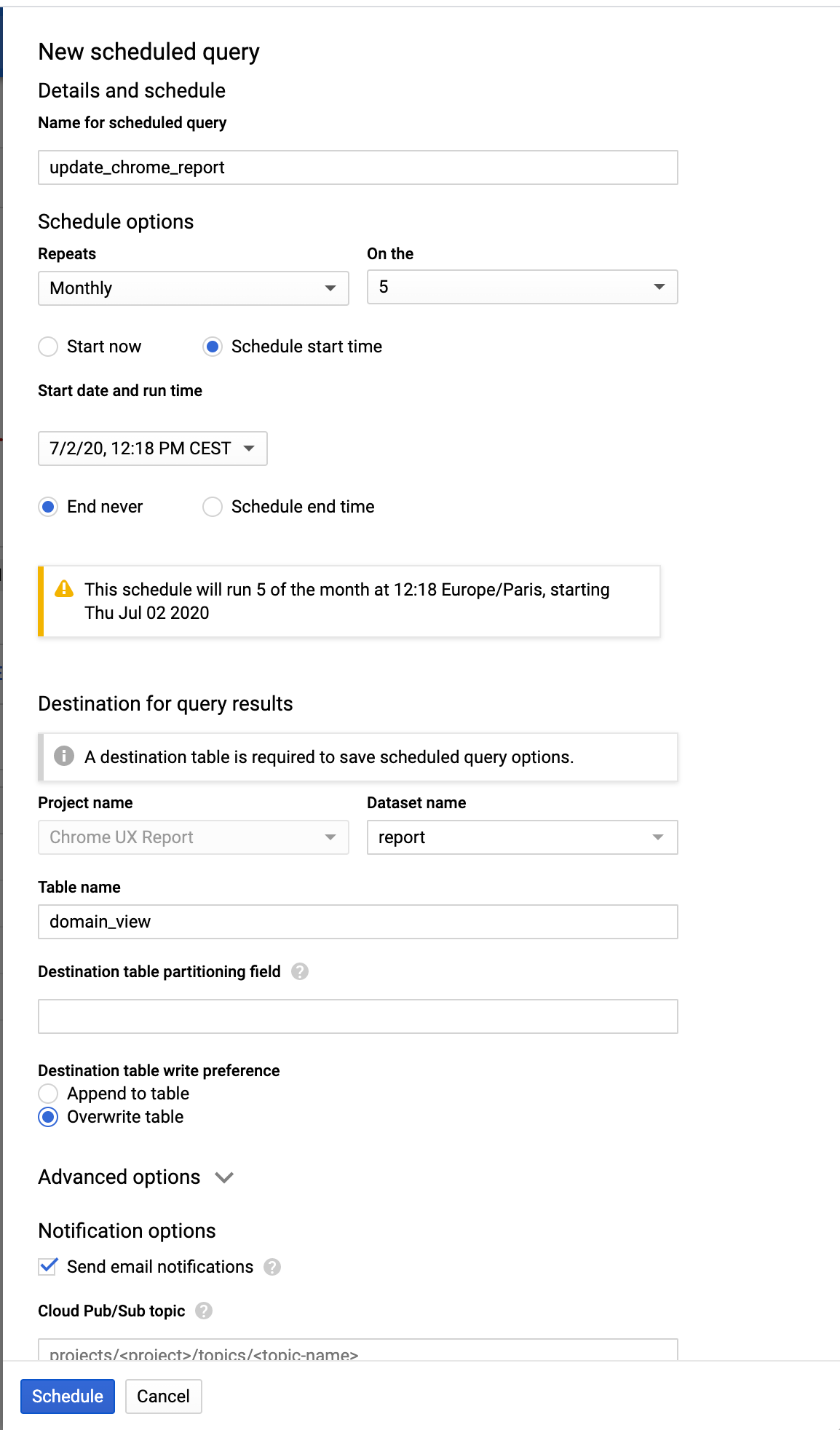
Ensuite, il ne reste qu'à mettre en place la récurrence. Nous allons mettre à jour cette table une fois par mois. Nous pouvons également demander à recevoir un email lorsque la mise à jour est effectuée. Nous pourrions aussi déclencher un évènement à envoyer dans Pub/Sub, afin de déclencher une autre action. Ce n'est pas le cas ici.
Construire le reporting dans Google Data Studio
Nous allons ajouter une source de donnée. Ici "BigQuery" :
On choisit la table que nous venons de créer :
Et il n'y a plus qu'à créer les graphiques et vues :