
Dans cet article, nous verrons comment écrire une cloud function dans Google Cloud Platform (en Python), afin d’importer les données de Matomo vers Google BigQuery
1. Contexte et objectifs
Pourquoi utiliser Matomo ?
Matomo est un outil d’analytics open source (une alternative à Google Analytics), qui a regagné en popularité récemment. En effet, Matomo peut bénéficier de l’exemption de consentement de la CNIL, ce qui permet de collecter des données d’audience, même en l’absence de consentement.
C’est donc un complément très utile à Google Analytics pour :
- Connaître plus précisément les chiffres d’audience, de conversion, de pages vues etc..., par source / device, y compris pour les utilisateurs qui refusent les cookies.
- Analyser la manière dont les internautes interagissent avec la bannière de consentement, dans le but de l’optimiser
Pour en savoir plus, quelques liens :
Matomo - L'alternative à Google Analytics qui protège vos données
Matomo est l'alternative éthique à Google Analytics qui protège vos données et la vie privée de vos clients Une puissante plateforme d'analyse Web avec la propriété de 100 % des données.
https://fr.matomo.org/
Cookies : solutions pour les outils de mesure d'audience
Dans quels cas les cookies sont-ils exemptés de consentement ? Afin de se limiter à ce qui est strictement nécessaire à la fourniture du service et être ainsi exemptés de consentement conformément à l'article 82 de la loi Informatique et Libertés, ces traceurs doivent :
https://www.cnil.fr/fr/cookies-solutions-pour-les-outils-de-mesure-daudience
- Le guide de configuration de Matomo ayant été validé par la CNIL pour bénéficier de l’exemption de consentement :
www.cnil.fr
https://www.cnil.fr/sites/default/files/atoms/files/matomo_analytics_-_exemption_-_guide_de_configuration.pdf
- 💡D’ailleurs, Matomo est la solution d’analytics utilisée sur le site de la CNIL :
Cnil cookies | CNIL
Cnil cookies Certaines fonctionnalités de ce site reposent sur l'usage de cookies. Si vous donnez votre accord (consentement), ces cookies seront déposés pour permettre de visualiser directement sur cnil.fr du contenu hébergé par des tiers. Cette page vous permet de donner, de refuser ou de retirer votre consentement à tout moment, soit globalement soit service par service.
https://www.cnil.fr/fr/gestion-des-cookies

Pourquoi importer ses données dans Google Big Query ?
Matomo possède sa propre interface d’analyse des données, assez similaire à Google Analytics
Cependant, cela ne correspond pas à ce que nous souhaitons faire, puisque dans notre cas, nous allons vouloir exporter la donnée, pour la comparer avec d’autres sources de donnée, par exemple :
- Google analytics
- Le CRM (pour les leads) ou les données e-commerce (pour les ventes)
- Les données issues de plate-forme d’Ads (Google Ads, FB Ads)
- etc...
Et nous voulons bien entendu automatiser le process (le pipeline de donnée).
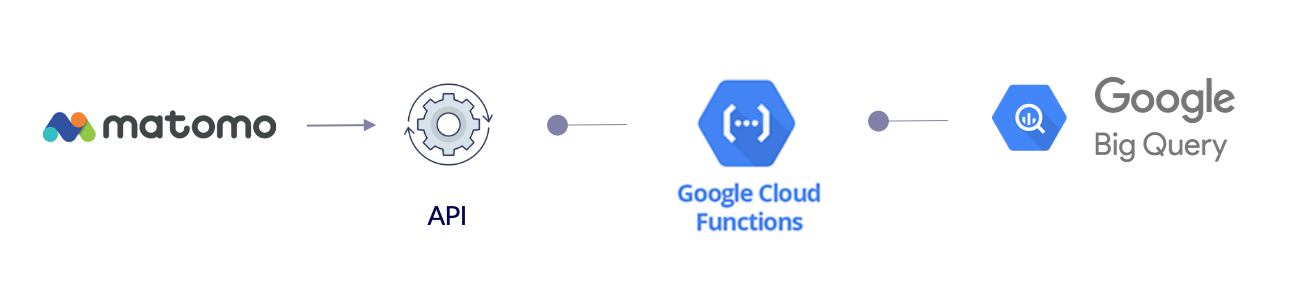
Pour faire cela, nous allons donc utiliser l’API de reporting de Matomo (pour appeler les données), via Google cloud function :
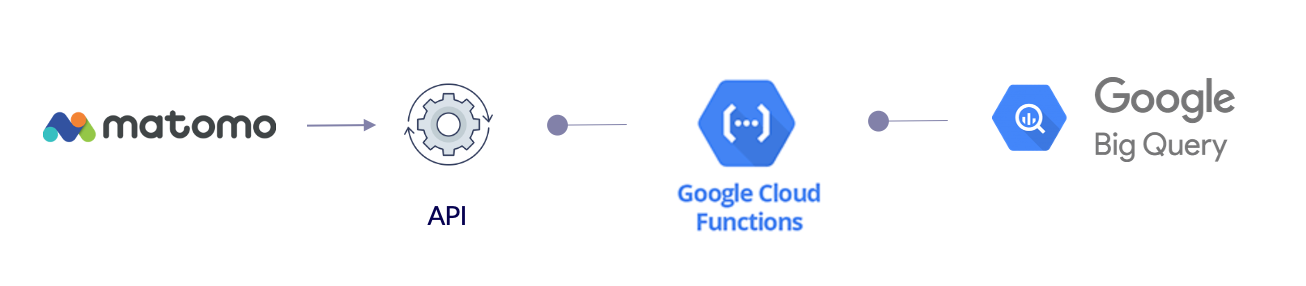
2. Dans Matomo
Nous allons donc utiliser l’API de reporting
Reporting API Reference
This is the Matomo API Reference. It lists all functions that can be called, documents the parameters, and links to examples for every call in the various formats. The APIs let you programmatically request any analytics reports from Matomo, for one or several websites and for any given date and period and in any format (CSV, JSON, XML, etc.).
https://developer.matomo.org/api-reference/reporting-api
- Pour notre exemple, nous allons créer un “custom report” dans Matomo (avec les dimensions et les métriques souhaitées), que nous allons appeler via l’API.
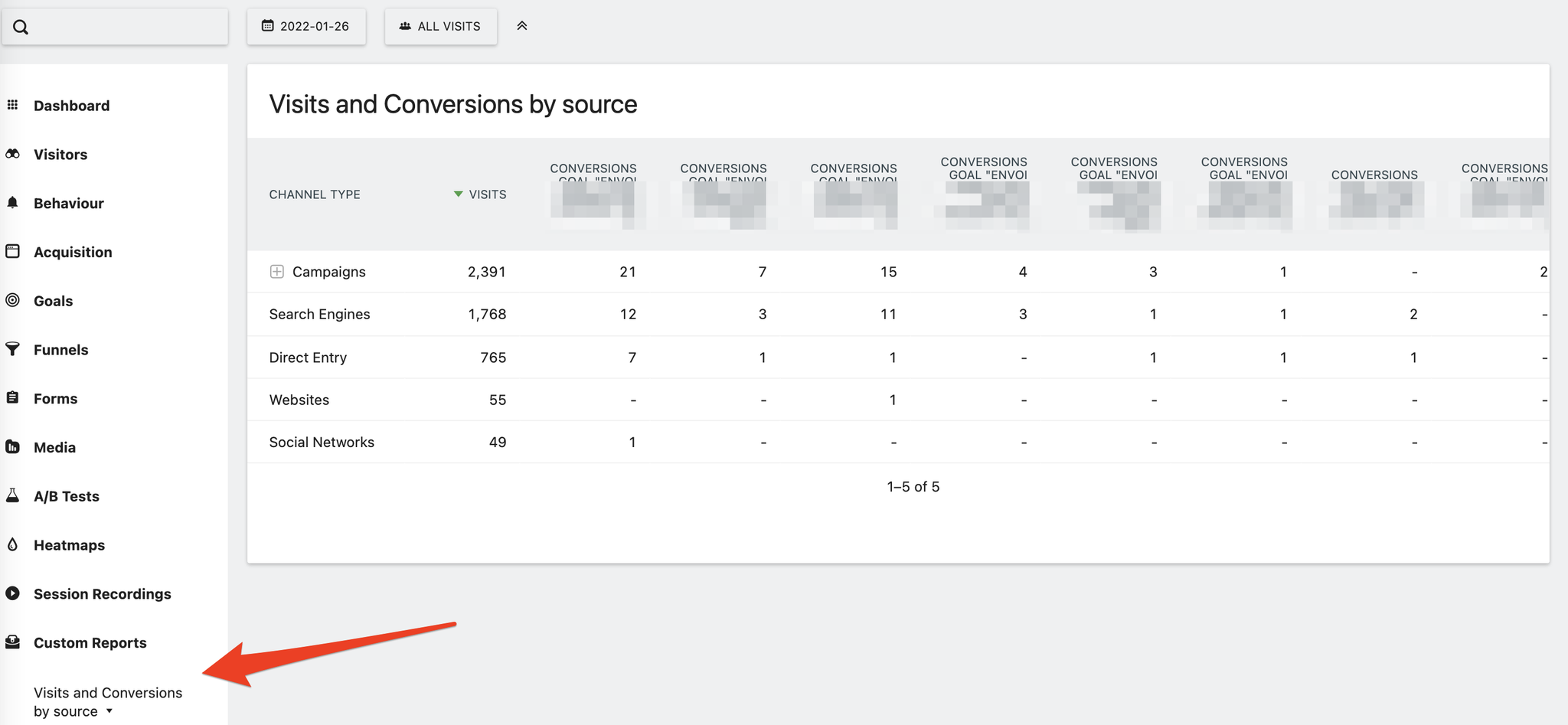
- Il faut en profiter pour relever l’ID du site et l’ID du custom report. On le trouve facilement dans l’URL de la page du rapport : https://monsite.matomo.cloud/index.php?module=CoreHome&action=index&idSite=1&period=day&date=yesterday#?idSite=1&period=day&date=yesterday&segment=&category=CustomReports_CustomReports&subcategory=1
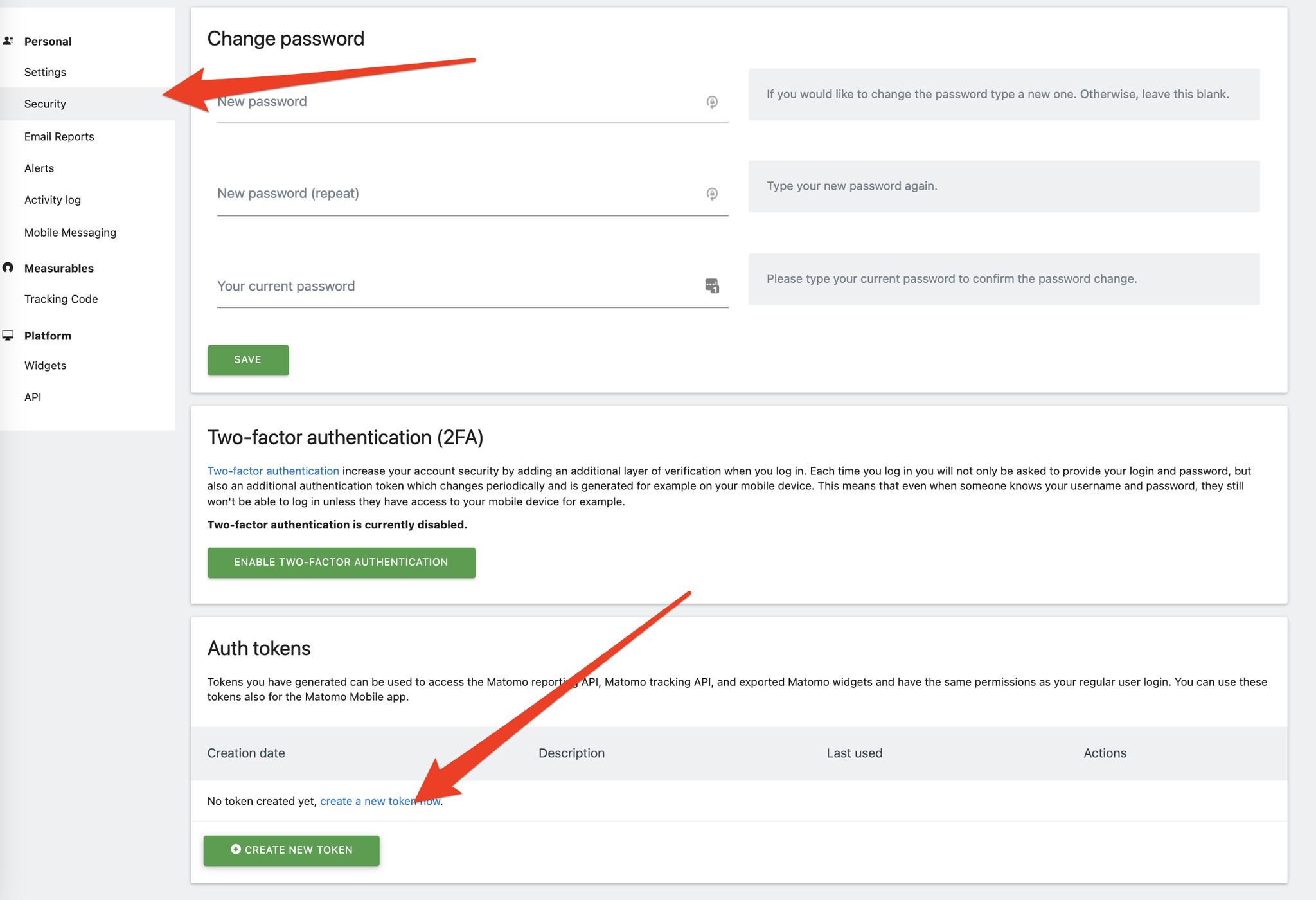
Il faut également créer le token pour l’API (dans Admin → Sécurité → Create token) qu’il faudra mettre dans ‘MyToken’
3. Dans Google Cloud platform
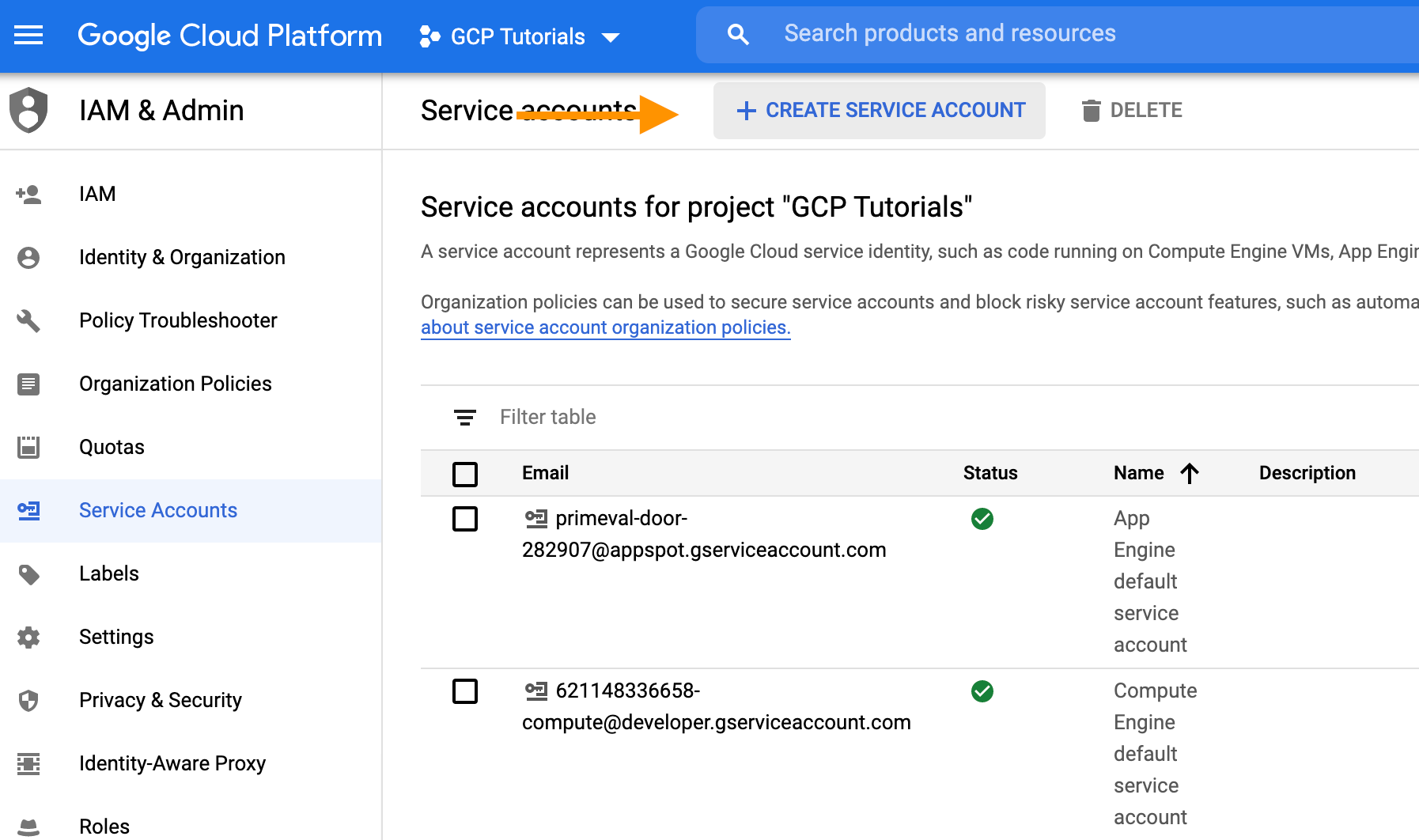
Créer un "service account" dans GCP
- Dans GCP, aller dans "IAM & Admin" → Service accounts (https://console.cloud.google.com/iam-admin/serviceaccounts). Cliquer sur "Create service account" :
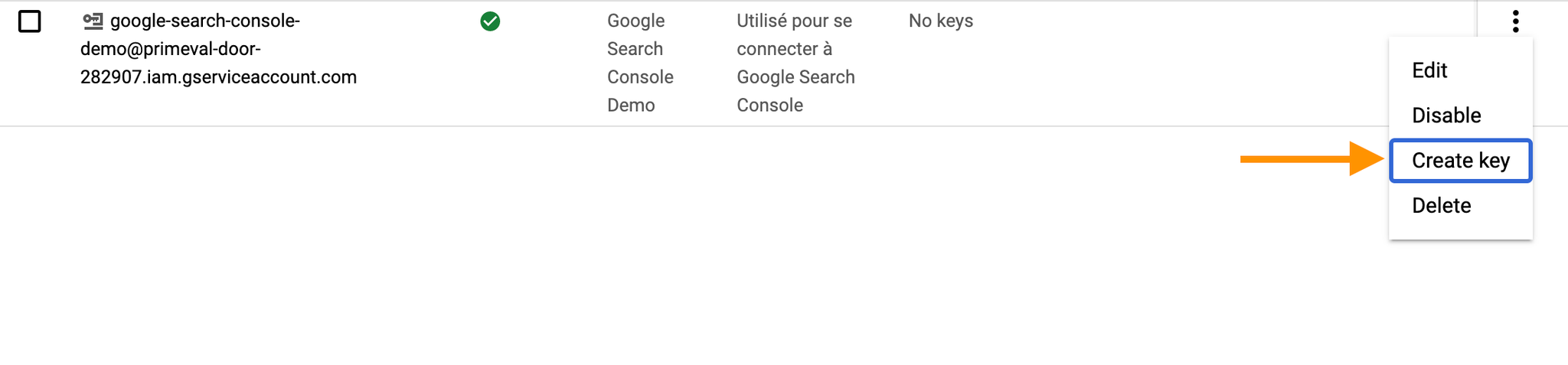
- Créer le compte, et lui donner un rôle qui permette l'écriture et la création de tables dans BigQuery (Admin)
- Créer une clé pour ce compte (JSON). Cette clé est téléchargée sur votre ordinateur. Nous en aurons besoin par la suite.
- Créer un dataset et une table
Le code dans Google Cloud function (Python)
Création de la coud function
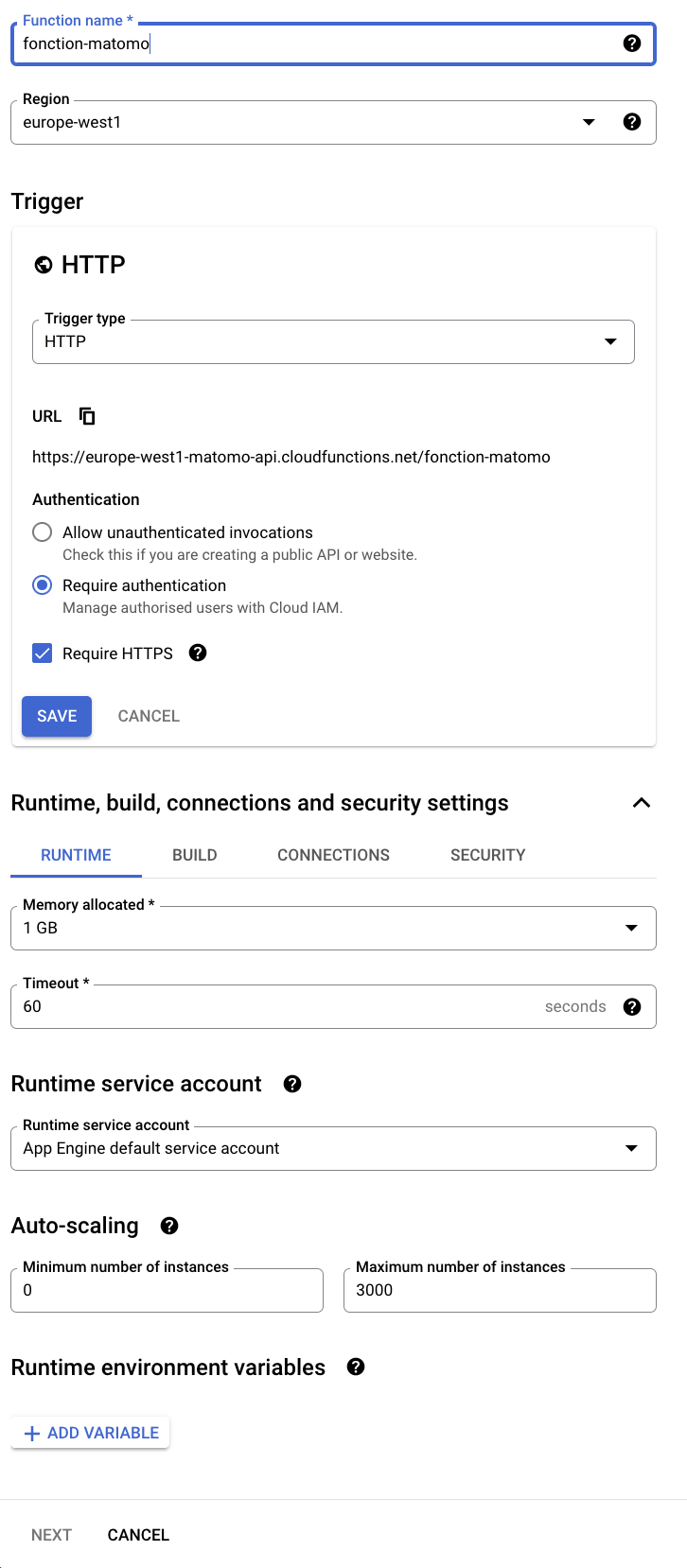
Le code est ci-dessous
pythonimport json import requests from datetime import datetime from dateutil import parser from google.cloud import bigquery from google.oauth2 import service_account ### On appelle les données de config headers = {'Content-Type': 'application/json'} TOK = 'MyToken' CRED_PATH = "applibs/google_cred.json" LOCATION = "europe-west2" CREDENTIALS = service_account.Credentials.from_service_account_file(CRED_PATH) def get_project_id(): with open(CRED_PATH) as f: data = json.load(f) return data['project_id'] PROJECT_ID = get_project_id() CLIENT = bigquery.Client(project=PROJECT_ID, credentials=CREDENTIALS) ### Fonction qui va nous servir à uploader les données dans BigQUery def save_data(json_data: json): try: dataset_name = 'my_dataset' table_id = "my_table_name" dataset_id = f'{PROJECT_ID}.{dataset_name}' dataset = bigquery.Dataset(dataset_id) dataset.location = LOCATION table_ref = dataset.table(table_id) table = CLIENT.get_table(table_ref) errors = CLIENT.insert_rows(table, json_data) print(errors) if not errors: return "success" else: error = errors[0]["errors"] message = error[0]["message"] return message except Exception as error: return f"Data saving error. Details: {error}" ### On prépare la requête API def extract(): params = (('token_auth', TOK), \ ('apiAction', 'getCustomReport'),\ ('language', 'en'),\ ('apiModule', 'CustomReports'), ('date', 'yesterday'), ('idCustomReport', 1), ('format', 'JSON')) r = requests.get('https://mydomain.matomo.cloud/?module=API&method=API.getProcessedReport&idSite=1&period=day&flat=1', params=params,headers=headers,verify = False) j = json.loads(r.text) return j def cloud_handler(request=None): """ :param request: :return: success/error message """ try: print(f"Start processing at: {datetime.now().isoformat()}") ### Extract data request_data = extract() data = request_data['reportData'] print(data) date = parser.parse(request_data['prettyDate']).strftime("%Y-%m-%d") json_data = [] for i in range(len(data)): json_data.append( { "date": date, "label": data[i]['label'], "visits": data[i]['nb_visits'], "goal_1_conversion": data[i]['goal_1_conversion'], "goal_2_conversion": data[i]['goal_2_conversion'], "goal_3_conversion": data[i]['goal_3_conversion'], "goal_4_conversion": data[i]['goal_4_conversion'], "goal_5_conversion": data[i]['goal_5_conversion'], "goal_6_conversion": data[i]['goal_6_conversion'], "goal_7_conversion": data[i]['goal_7_conversion'], "goal_11_conversion": data[i]['goal_11_conversion'] } ) print(json_data) ### store data to BigQuery res = save_data(json_data) print(res) print(f"End processing at: {datetime.now().isoformat()}") if res == "success": return {"message": "Data saved successfully."}, 200 print("error: " + res) return {"message": res}, 400 except Exception as error_info: print(error_info) return {"message": error_info}, 400
Et le fichier “requirements.txt :
sqlgoogle-api-core==1.17.0 google-api-python-client==1.7.11 google-auth==1.14.1 google-auth-httplib2==0.0.3 google-cloud-bigquery==1.24.0 google-cloud-core==1.1.0 google-cloud-firestore==1.6.0 google-cloud-storage==1.23.0 google-resumable-media==0.5.0 googleapis-common-protos==1.6.0 python-dateutil==2.7.5
Ajouter un fichier ayant le chemin applibs/google_cred.json et y copier le contenu du fichier de la clé créée pour le service account

Définir le point d’entrée en tant que cloud_handler

Dans l’interface de cloud function :
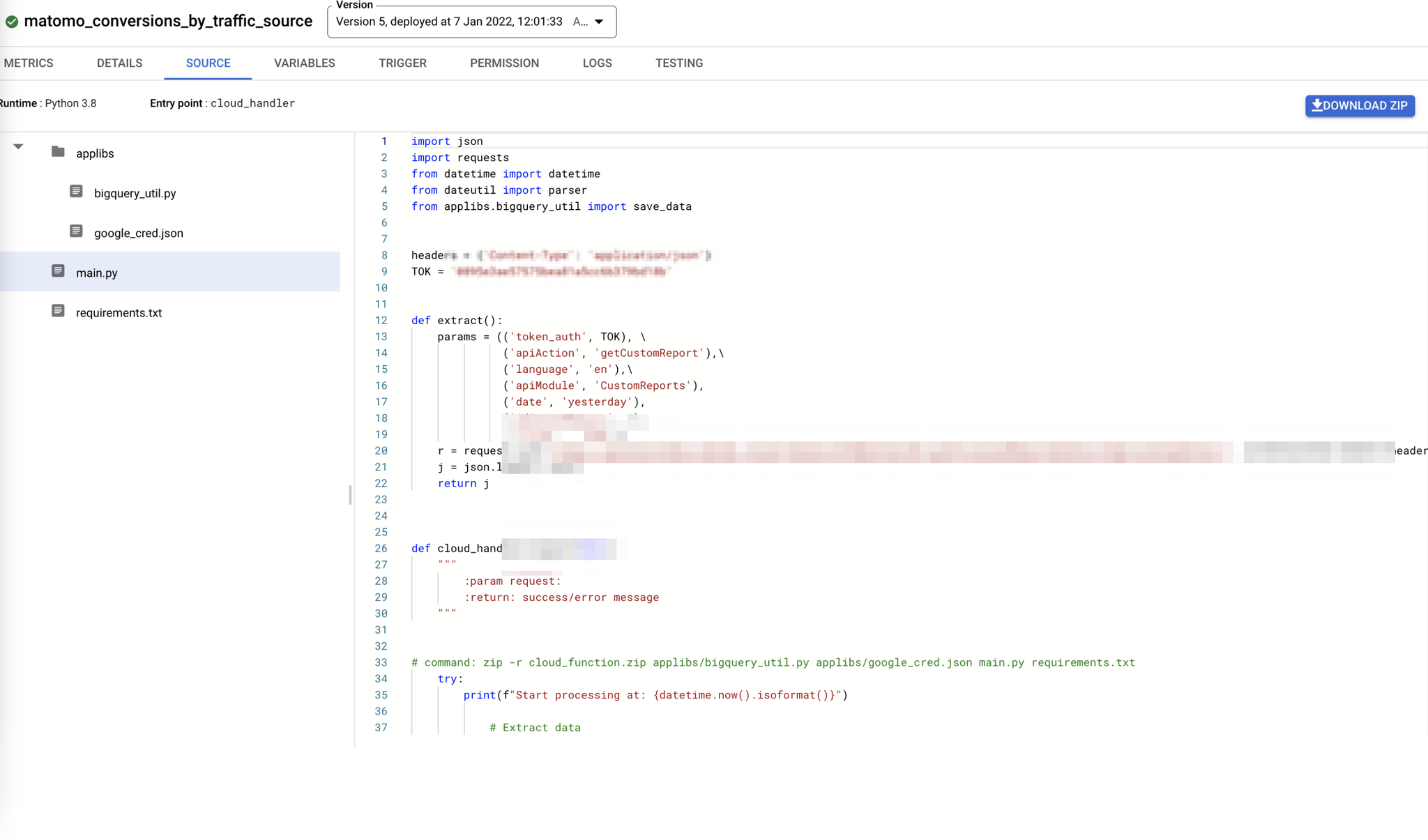
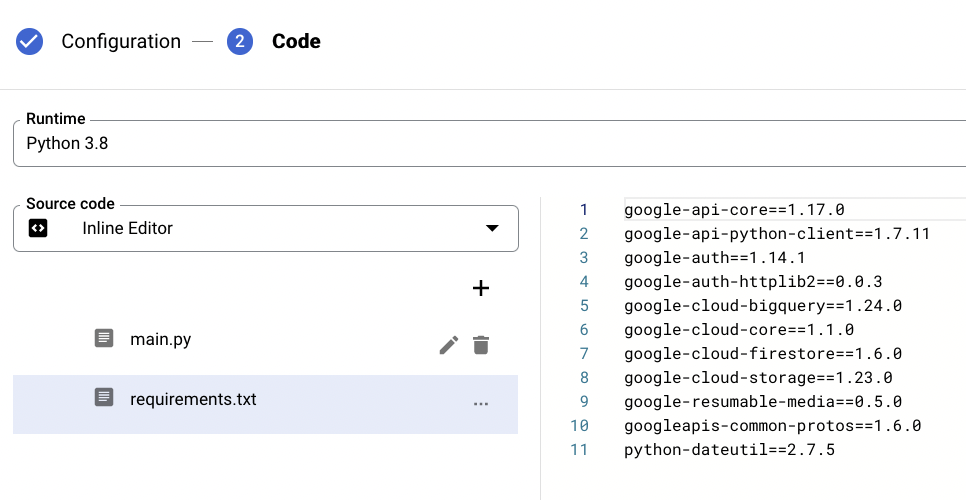
Déclencher la fonction périodiquement (tous les jours)
Pour cela, il suffit d’aller dans cloud scheduler :
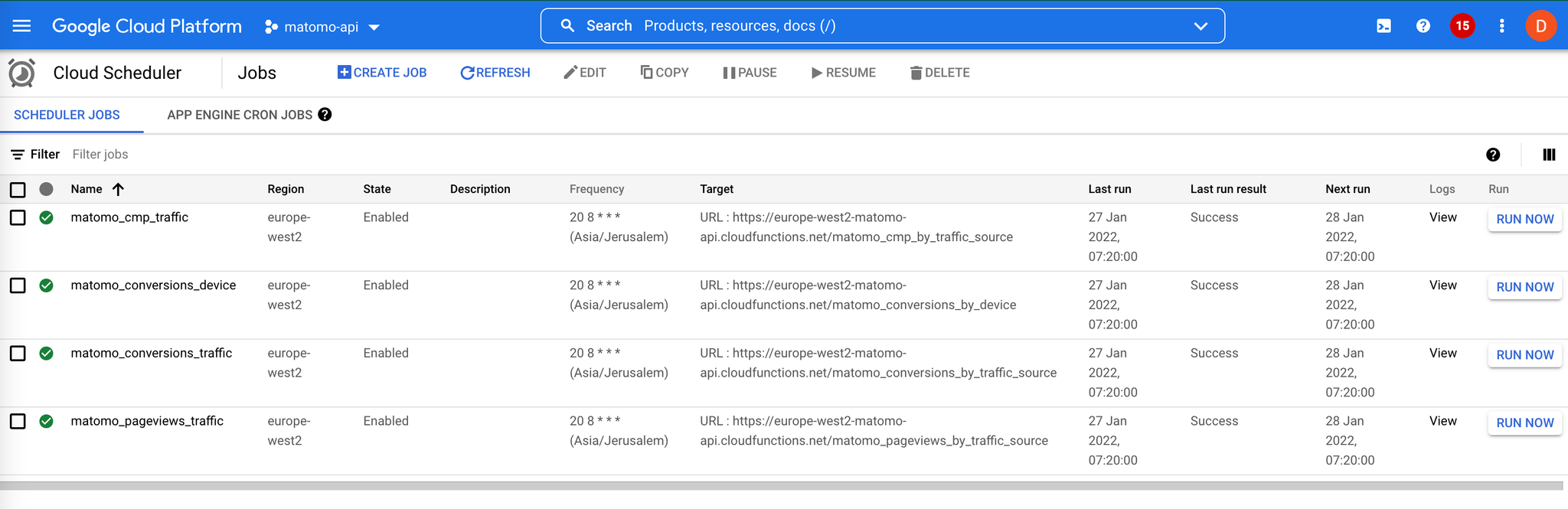
4. Admirer le résultat
Après avoir manuellement créé le dataset et la table avec les champs définis dans la cloud function, et exécuté la fonction, la donnée est maintenant dans Google Big Query :
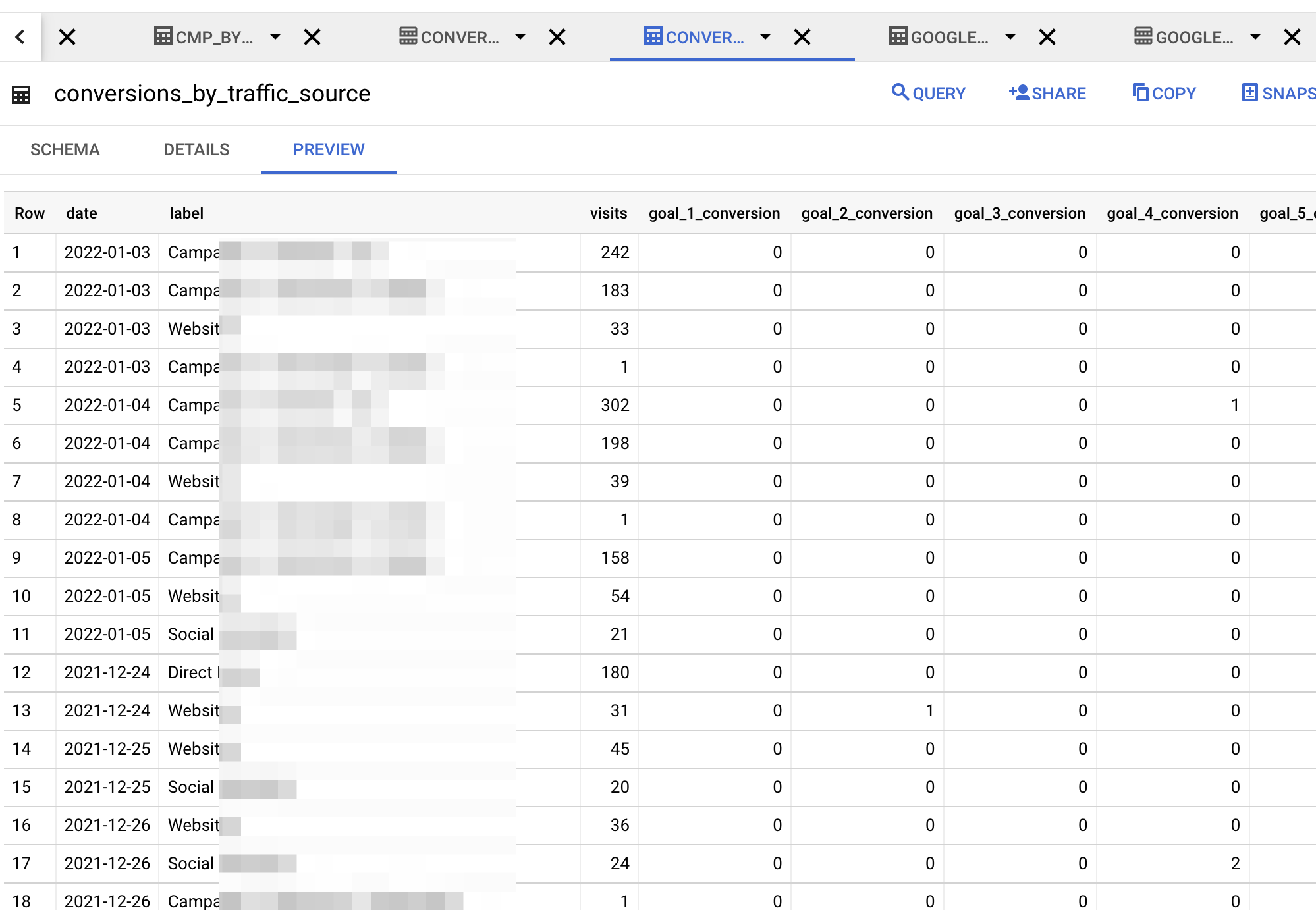
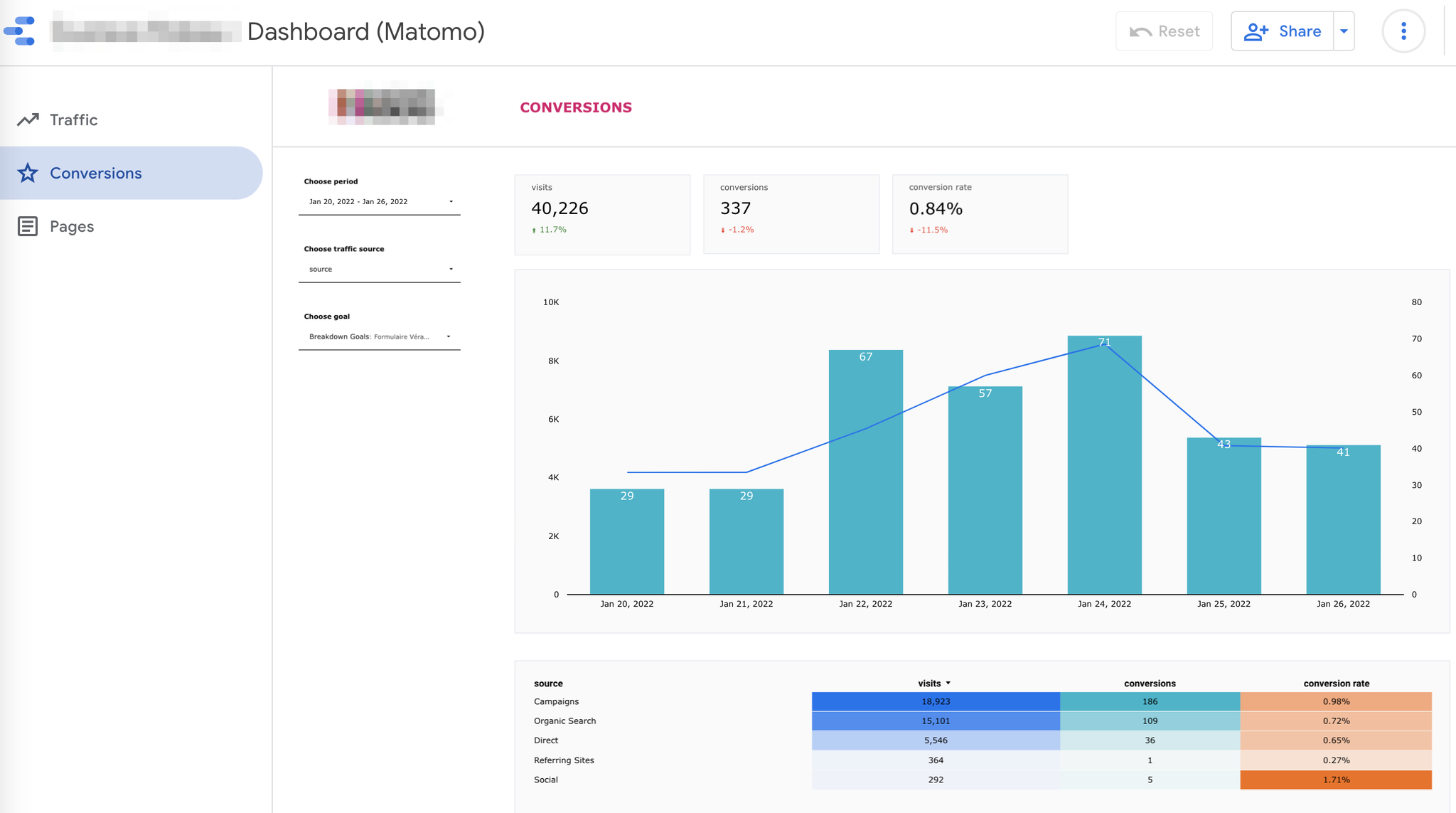
Et il ne vous reste plus qu’à brancher un outil de DataViz dessus
Envie de déployer Matomo ? 🚀
Contactez nous et nous nous ferons un plaisir de revenir vers vous.
Contact →