
Par Xavier le ‣
Le code ci-dessous permet de simplement retirer les doublons dans une liste sur BigQuery. Plus bas se trouve un cas pratique utilisant ce bout de code

Code SQL👇
sqlSELECT * REPLACE ( (SELECT ARRAY_AGG(agg_liste) FROM ( SELECT DISTINCT * FROM UNNEST(email) AS liste) -- Remplacer email par le nom de la liste à dédupliquer AS agg_liste) AS email ) -- Remplacer email par le nom de la liste à dédupliquer FROM 'TABLE' -- Insérer la source ici
Il suffit de remplacer les occurrences du mot 'email' par le nom de la colonne sous format array que vous souhaitez dé-dupliquer
Source
Cet article est inspiré de celui-ci :
How to find DISTINCT values in a ARRAY in Bigquery
Often, we have array datatypes and want to remove the duplicates (often called as dedup) and find out the unique values in an array in Bigquery, like shown in the example below: Solution: Much cleaner way is to use SQL UDF to encapsulate dedup logic as in below example and
https://copycoding.com/d/how-to-find-distinct-values-in-a-array-in-bigquery
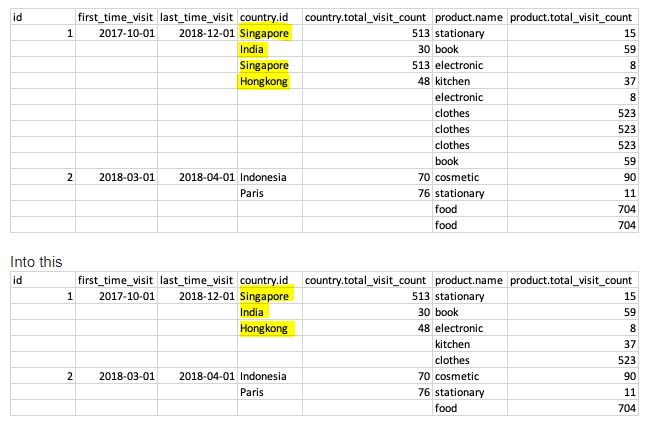
Avec pour principales différences l'ajout de noms explicites pour mieux comprendre les étapes du code et le retrait de la fonction pour que le code s'exécute sans avoir à la déclarer au préalable.
Annexe (Cas pratique)
Table utilisée en entrée
TutoDedupBQ
Sheet1 id,date,email ...
https://docs.google.com/spreadsheets/d/10XDryawq25gQOzwfe586C7yPW7vOpV4plnHvCR3AfDQ/edit?usp=sharing

Séparation des emails en liste
sqlSELECT * EXCEPT (email), SPLIT(email,',') AS email FROM `TABLE`
Aplatir la liste
sqlSELECT * EXCEPT (email, liste), liste AS email FROM dedup_mail, UNNEST(email)
Résultat
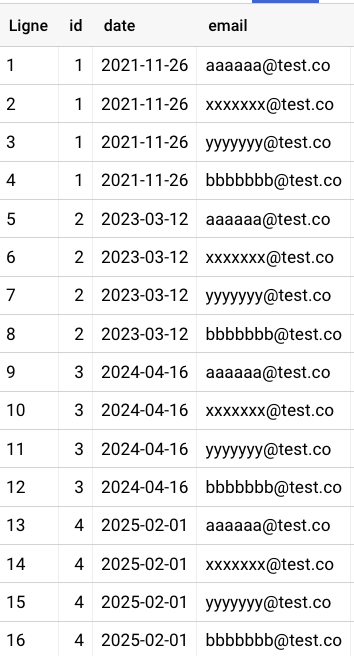
Toutes ces étapes utilisées dans une même requête
sqlWITH table_source AS ( SELECT * FROM `TABLE` -- sélection de la table en entrée ), split_mail AS ( SELECT * EXCEPT (email), SPLIT(email,',') AS email FROM table_source ), dedup_mail AS ( SELECT * REPLACE ( (SELECT ARRAY_AGG(agg_liste) FROM ( SELECT DISTINCT * FROM UNNEST(email) AS liste) AS agg_liste) AS email ) FROM split_mail ), final AS ( SELECT * EXCEPT (email, liste), liste AS email FROM dedup_mail,UNNEST(email) ) SELECT * FROM final