Par Xavier le Dec 16, 2021
Parfois on aimerait que la gestion des doublons dans BigQuery soit aussi simple que sur Excel, voici quelques tips en SQL pour les traiter le plus simplement possible.

Code 👇
Compter le nombre de lignes en double (sur la base de toutes les colonnes)
sqlwith input_table as ( select * from `VOTRE_TABLE` ) SELECT (SELECT COUNT(*) FROM ( SELECT DISTINCT * FROM input_table )) AS total_lignes_distinctes, (SELECT COUNT(*) FROM input_table ) AS total_lignes
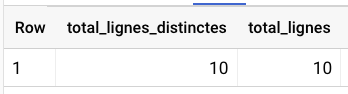
Cela pourrait marcher dans certains cas, mais ici la ligne id est toujours unique, c'est pour cela qu'il n'y a pas de différences. Le code ci-dessous permet d'y remédier.
Compter le nombre de lignes en double (selon les colonnes voulues)
sqlwith input_table as ( select * from `VOTRE_TABLE` ) SELECT -- Renseigner les combinaisons de colonnes à vérifier dans la fonction concat(), par exemple concat(nom,prenom,email) (SELECT COUNT(*) FROM ( SELECT DISTINCT concat(colonne_1,colonne_4,etc) FROM input_table )) AS total_lignes_distinctes, (SELECT COUNT(*) FROM input_table ) AS total_lignes
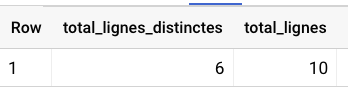
Ici, puisque nous avons décidé de ne pas prendre la colonne id, BigQuery nous retourne 6 lignes uniques. Dans les annexe se trouve une méthode qui permet d'aller vite s'il y a beaucoup de colonnes à spécifier.
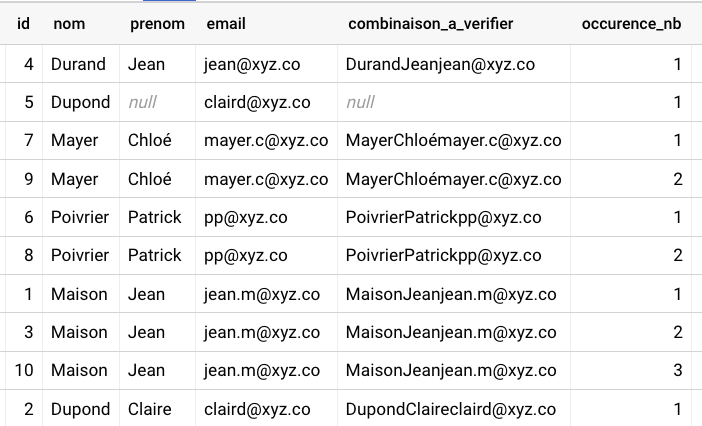
Voir rapidement les lignes qui existent en double (ou plus)
sqlwith input_table as ( select *, concat(nom,prenom,email) as combinaison_a_verifier -- Renseigner les nom des colonnes à combiner pour vérifier les doublons from `VOTRE_TABLE` ), calcul_nb_occurences as ( select *, row_number() over (partition by combinaison_a_verifier order by id asc) as occurence_nb FROM input_table )-- order by id est optionnel mais permet d'afficher les doublons apparus plus tardivement select * except(combinaison_a_verifier) from calcul_nb_occurences where occurence_nb > 1
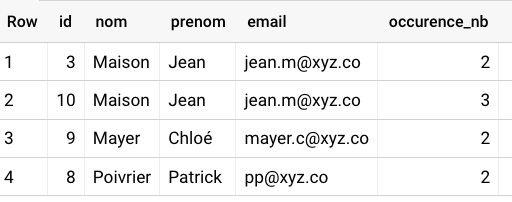
La table retournée ne contient que les lignes qui sont apparues plus d'une fois et le numéro de l'occurence. Si occurence_nb = 3, cela signifie que c'est la 3ème fois que cette ligne est observée.
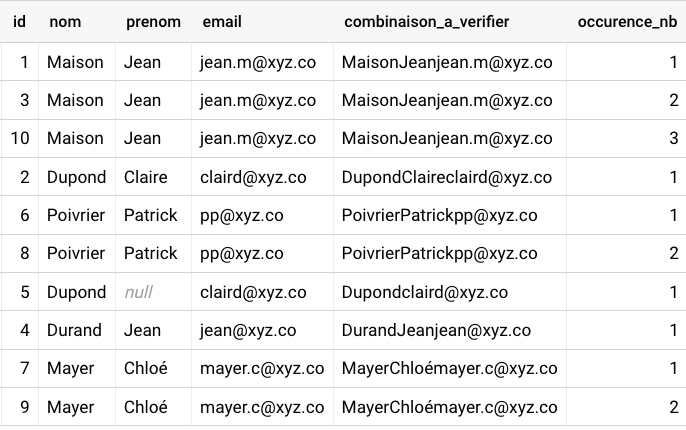
Retirer les doublons
sqlwith input_table as ( select *, concat(nom,prenom,email) as combinaison_a_verifier -- Renseigner les nom des colonnes à combiner pour vérifier les doublons from `VOTRE_TABLE` ), calcul_nb_occurences as ( select *, row_number() over (partition by combinaison_a_verifier order by id asc) as occurence_nb FROM input_table )-- order by id est optionnel mais permet de garder la versions la plus ancienne du doublon select * except(combinaison_a_verifier, occurence_nb) from calcul_nb_occurences where occurence_nb = 1
Cette table ne contient plus de doublons (selon les critères voulus). Il est alors possible de l'enregistrer dans une nouvelle table ou d'écraser la table d'origine avec les résultats sans doublons.
Annexe
Note pour les champs null
La fonction concat() renvoie une valeur null si l'un des champs est null Pour y remédier, il est possible d'utiliser la fonction coalesce(colonne_1,'') pour chaque colonne susceptible d'être null dans la fonction concat() Par exemple :
sqlconcat(nom,coalesce(prenom,''),email)
Note pour spécifier un grand nombre de colonnes d'un coup
S'il y a beaucoup de colonnes à spécifier, il peut être fastidieux des les écrire manuellement dans la fonction concat(). Il peut donc être pratique de faire tourner au préalable la requête ci-dessous (en spécifiant le projet, le dataset et la table) et de copier le résultat dans la fonction concat() et éventuellement enlever les noms de colonnes en trop.
sqlselect string_agg(concat('coalesce(',column_name,',"")')) -- ne pas changer column_name from VOTRE_PROJET.VOTRE_DATASET.INFORMATION_SCHEMA.COLUMNS where table_name = 'VOTRE_TABLE'
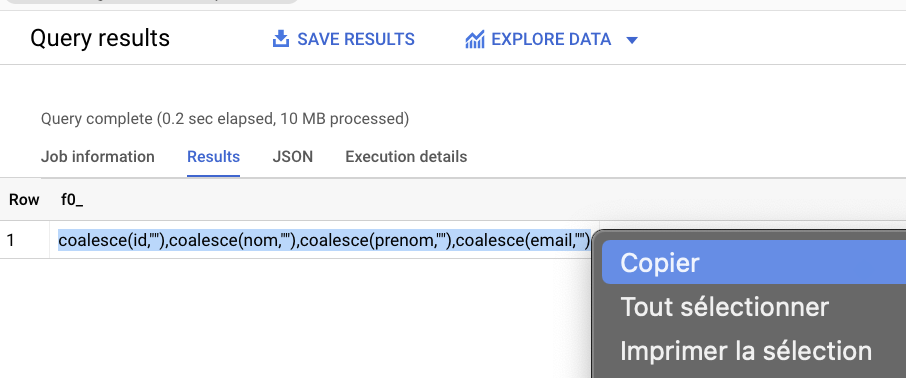
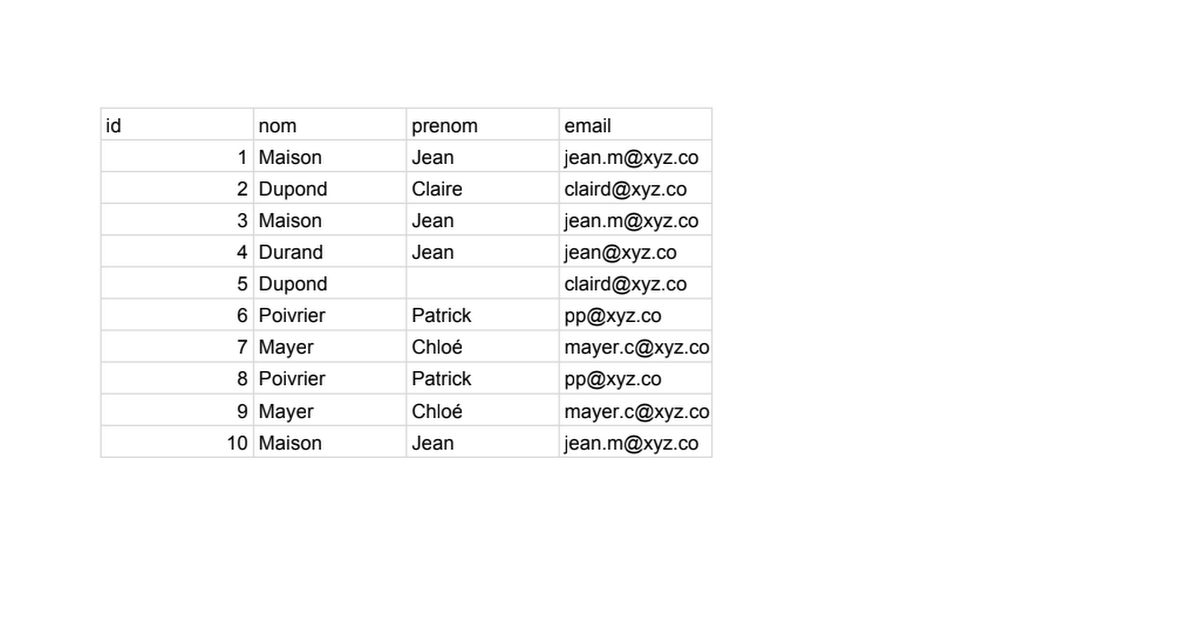
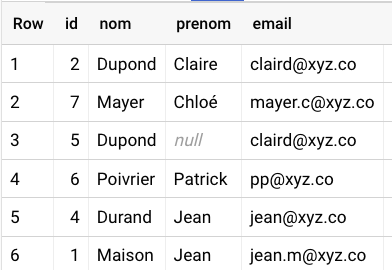
Table utilisée en entrée :
TutoDoublons
Sheet1 id,nom,prenom,email 1,Maison,Jean,jean.m@xyz.co 2,Dupond,Claire,claird@xyz.co 3,Maison,Jean,jean.m@xyz.co 4,Durand,Jean,jean@xyz.co 5,Dupond,claird@xyz.co 6,Poivrier,Patrick,pp@xyz.co 7,Mayer,Chloé,mayer.c@xyz.co 8,Poivrier,Patrick,pp@xyz.co 9,Mayer,Chloé,mayer.c@xyz.co 10,Maison,Jean,jea...
https://docs.google.com/spreadsheets/d/1t__Igw4rrNUwIXnTEMZBUBG_BF6CsvDnLA369pWq6IE/edit?usp=sharing